作者 | lionleeli
曾看过很多并发模型相关的文章,但是这些文章大部分只讲了并发模型的实现原理,并没有给出具体的示例代码,看完总觉得对并发模型这个知识点是一知半解,不得要领。为了掌握高并发模型,我这里抛砖引玉,实现了20种常见的并发模型,并对每种并发模型进行了性能压测和分析。由于本人水平有限,文章中难免有一些不准确或者纰漏的地方,欢迎大家批评指正。

一、缘起
最近看了好友推荐的一本新书《Linux后端开发工程实践》 ,该书RPC框架和微服务集群的部分甚是不错,其中的“第10章-I/O模型与并发”中介绍了 17 种不同的并发模型,看完之后更是感觉受益匪浅。
但美中不足的是这 17 种并发模型只支持短连接,配套的 BenchMark 工具不支持发起指定的请求负载,给出的性能指标也不够丰富。
受到该内容的启发,我在该内容的基础上实现了 20 种常见的支持长连接的并发模型,完善了协议解析效率和BenchMark 工具。
二、前置说明
因为这 20 种并发模型的代码量已经达到了 1万2千多行,是不适合在一篇文章中全部展示的。所以我把相关的代码开源在github上,方便大家查看。
在文中介绍到相关代码时都会给出具体的代码位置,但只会在文章中贴出关键的代码,即便如此,本文的代码量依然不少,强烈建议收藏后阅读。
github上的项目是MyEchoServer,项目链接为:github.com/newland2024
项目的目录结构
MyEchoServer 项目的目录结构如下所示。
.
├── BenchMark
│ ├── benchmark.cpp
│ ├── client.hpp
│ ├── clientmanager.hpp
│ ├── makefile
│ ├── percentile.hpp
│ ├── stat.hpp
│ └── timer.hpp
├── common
│ ├── cmdline.cpp
│ ├── cmdline.h
│ ├── codec.hpp
│ ├── conn.hpp
│ ├── coroutine.cpp
│ ├── coroutine.h
│ ├── epollctl.hpp
│ ├── packet.hpp
│ └── utils.hpp
├── ConcurrencyModel
│ ├── Epoll
│ ├── EpollReactorProcessPoolCoroutine
│ ├── EpollReactorProcessPoolMS
│ ├── EpollReactorSingleProcess
│ ├── EpollReactorSingleProcessCoroutine
│ ├── EpollReactorSingleProcessET
│ ├── EpollReactorThreadPool
│ ├── EpollReactorThreadPoolHSHA
│ ├── EpollReactorThreadPoolMS
│ ├── LeaderAndFollower
│ ├── MultiProcess
│ ├── MultiThread
│ ├── Poll
│ ├── PollReactorSingleProcess
│ ├── ProcessPool1
│ ├── ProcessPool2
│ ├── Select
│ ├── SelectReactorSingleProcess
│ ├── SingleProcess
│ └── ThreadPool
├── readme.md
└── test
├── codectest.cpp
├── coroutinetest.cpp
├── makefile
├── packettest.cpp
├── unittestcore.hpp
└── unittestentry.cpp相关的目录说明如下:
- BenchMark是基准性能压测工具的代码目录。
- ConcurrencyModel是20种不同并发模型的代码目录,这个目录下有 20 个不同的子目录,每个子目录都代表着一种并发模型的实现示例。
- common是公共代码的目录。
- test目录为单元测试代码的目录。
三、预备工作
因为I/O模型是并发模型涉及到的关键技术点,所以我们也不会免俗,也会介绍一下常见的I/O模型。
为了降低实现难度,这里我们实现了一个简单的应用层协议,并实现一些通用的基础代码,以便后续高效的实现不同的并发实例。
1. 常见I/O模型
常见的I/O模型有五种:阻塞I/O、非阻塞I/O、多路I/O复用、信号驱动I/O、异步I/O。其中的阻塞I/O、非阻塞I/O、多路I/O复用、信号驱动I/O都是同步IO。
同步I/O和异步I/O的区别在于,是否需要进程自己再调用I/O读写函数。同步I/O需要,异步I/O不需要。
(1) 阻塞I/O
在阻塞IO模式下,只要I/O暂不可用,读写操作就会被阻塞,直到I/O可用为止,在被阻塞期间,当前进程是被挂起的,这样就无法充分的使用CPU,导致并发效率低下。
(2) 非阻塞I/O
在非阻塞IO模式下,读写操作都是立即返回,此时当前进程并不会被挂起,这样就可以充分的使用CPU,非阻塞I/O通常会和多路I/O复用配合着一起使用,从而实现多个客户端请求的并发处理。
(3) 多路I/O复用
多路I/O复用实现了多个客户端连接的同时监听,大大提升了程序感知客户端连接可读写状态变化的效率。在Linux下多路I/O复用的系统调用为select、poll、epoll。
(4) 信号驱动I/O
通过注册SIGIO信号的处理函数,实现了一个I/O就绪的通知机制,在SIGIO信号的处理函数再进行读写操作,从而避免了低效的I/O是否就绪的轮询操作。
但是在信号处理函数中是不能调用异步信号不安全的函数,例如,有锁操作的函数就是异步信号不安全的,故信号驱动I/O应用的并不多。
(5) 异步I/O
前面的4种I/O模型都是同步IO,最后一种I/O模型是异步IO。异步I/O就是先向操作系统注册读写述求,然后就立马返回,进程不会被挂起。操作系统在完成读写操作之后,再调用进程之前注册读写述求时指定的回调函数,或者触发指定的信号。
2. 应用层协议
20种并发示例实现的是最常见的Echo(回显)服务,这里我们设计了一个简单的应用层协议,格式如下图所示。

协议由两部分组成,第一部分是固定长度(4字节)的协议头部,协议头部用于标识后面的变长协议体的长度,第二部分就是是具体的变长协议体。
(1) 协议实现
协议的编解码在common目录的codec.hpp文件中实现,其中DeCode函数用于实现协议的流式解析。
采用流式解析,能避免拒绝服务攻击。例如,攻击者创建大量的连接,然后每个连接上只发送一个字节的数据,如果采用常见的解析方式,一直在socket上读取数据,直到完成一个完整协议请求的解析。
在不采用协程的情况下,不管是阻塞IO、非阻塞IO、IO复用,当前的工作进程或者线程不是被挂起(阻塞IO),就是CPU使用率飙升(非阻塞IO),服务可用的工作进程或者线程会快速被消耗完,导致服务无法对正常的客户端提供服务,从而形成拒绝服务攻击。
流式解析(来多少字节,就解析多少字节)+ 协程切换(IO不可用时切换到其他协程)+ Reactor定时器实现非阻塞IO的超时机制,就可以很好的解决这种拒绝服务攻击。
(2) 共享的二进制缓冲区
这里特别说明一下二进制缓冲区的实现。在实现协议的时候,通常会「存储读取到的网络数据缓冲区」和「协议解析的缓冲区」这两份独立的缓冲区。
而我这里思考后,发现其实不用多申请一块二进制缓冲区,写入读取到的网络数据和解析读取到的网络数据可以共享同一个二进制缓冲区,进而减少了内存的分配和两块内存之间的拷贝。共享的二进制缓冲区的示意图如下图所示。
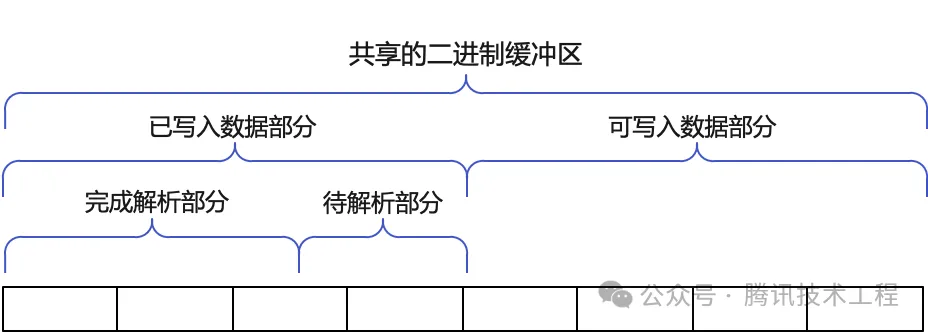
共享的二进制缓冲区在common目录的packet.hpp文件中实现。
3. 命令行参数解析
不管是BenchMark工具,还是不同的并发模型程序,都需要支持从命令行中读取动态参数的能力。因为参数解析的getopt系列函数并不易用,故参考Go语言的flag包实现,独立封装了一套易用的命令行参数解析函数。
具体的实现在common目录的cmdline.h和cmdline.cpp文件中。
4. 协程池实现
因为有协程池相关的并发模型,所以需要实现协程池。协程池的实现在common目录的coroutine.h和coroutine.cpp文件中。
特别提一下,协程池这里通过getcontext、makecontext、swapcontext这三个库函数来实现,并且通过C++11的模版函数和可变参数模板的特性,实现了支持变参列表的协程创建函数。协程创建函数的实现如下所示。
template <typename Function, typename... Args>
int CoroutineCreate(Schedule& schedule, Function&& f, Args&&... args) {
int id = 0;
for (id = 0; id < schedule.coroutineCnt; id++) {
if (schedule.coroutines[id]->state == Idle) break;
}
if (id >= schedule.coroutineCnt) {
return kInvalidRoutineId;
}
Coroutine* routine = schedule.coroutines[id];
std::function<void()> entry = std::bind(std::forward<Function>(f), std::forward<Args>(args)...);
CoroutineInit(schedule, routine, entry);
return id;
}四、BenchMark 工具
正所谓工欲善其事,必先利其器。为了评估不同并发模型的性能,需要构建一个BenchMark工具来实现请求的发压。
1. 并发模型
在看压测工具实现之前,需要思考一个问题,「如果压测工具本身并发能力不足,则无法产生足够的流量负载,也就无法测试出不同并模型的性能极限」,所以也需要设计好压测工具使用的并发模型。
我们使用多线程+Reactor的并发模型来实现压测工具。发起请求的每个线程都是一个单独的Reactor模型。Reactor模型简图如下图所示。

Reactor是一种事件监听和分发模型,配合epoll可以实现高效的并发处理,从而能充分的利用CPU,即使是单线程也能产生足够大的请求负载。
2. 支持的特性
发压工具BenchMark的usage输出如下所示。
root@centos BenchMark $ ./BenchMark -h
BenchMark -ip 0.0.0.0 -port 1688 -thread_count 1 -max_req_count 100000 -pkt_size 1024 -client_count 200 -run_time 60 -rate_limit 10000 -debug
options:
-h,--help print usage
-ip,--ip service listen ip
-port,--port service listen port
-thread_count,--thread_count run thread count
-max_req_count,--max_req_count one connection max req count
-pkt_size,--pkt_size size of send packet, unit is byte
-client_count,--client_count count of client
-run_time,--run_time run time, unit is second
-rate_limit,--rate_limit rate limit, unit is qps/second
-debug,--debug debug mode, more info print发压工具实现了以下的特性:
- 支持对监听在指定的ip和port的服务发起压测。
- 支持多线程压测,并可以指定使用的线程数。
- 支持指定客户端连接建立成功之后,最多可以发起多少次请求。(ps:这个选项值如果设置为1,则请求就退化成通过短连接来完成)
- 支持指定请求包的大小,单位为字节。
- 支持指定每个线程下发起请求的客户端并发连接数。
- 支持指定总的压测时间,单位秒。
- 支持指定压测能产生的最大的流量负载,单位qps。
- 支持debug模式。
4.3 代码实现
在单独的BenchMark目录中实现了这个压测工具,大家可以自行查看相关代码。这里特别说明一下,我使用了状态机来实现客户端请求的持续发送,代码会稍显复杂。
4. 执行效果
这里展示一下,压测其中一个单进程并发模型(EpollReactorSingleProcess)的效果,执行结果如下图所示。
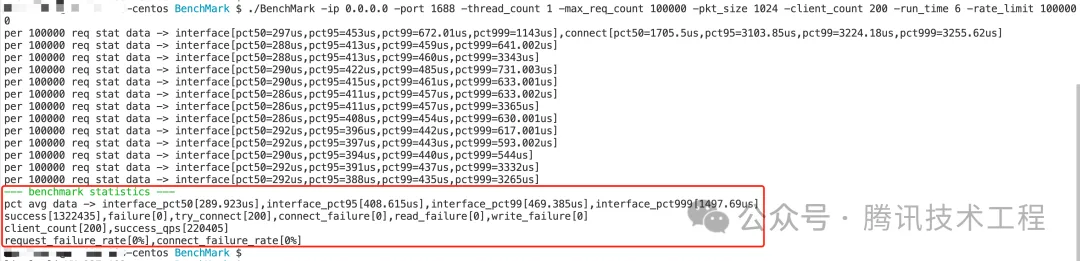
从上图的压测结果可以看出,在请求数据长度为1k的情况下,EpollReactorSingleProcess的并发模型就能对外提供高达22万qps的并发处理能力。
上图中红色框出的内容就是最后的压测结果数据,这里的数据分为4部分:
- 接口的pct50、pct95、pct99和pct999的耗时数据。
- 请求成功数、请求失败数、尝试建立连接数、连接失败数、读失败数和写失败数。
- 客户端连接数和请求成功的qps数。
- 请求失败率和连接失败率。
五、20种不同的并发模型
在本节,我们将展示20种不同的并发模型的具体实现。
ConcurrencyModel目录下的每一个子目录都对应一种并发模型的实现。例如,SingleProcess子目录就是单进程并发模型的实现。
ConcurrencyModel目录下的每个子目录下都只有一个cpp文件和一个makefile文件,而这个cpp文件就是这种并发模型的主流程代码,而makefile文件是用于编译的。例如,SingleProcess子目录下只有一个singleprocess.cpp文件。
1. 简单模型
(1) SingleProcess
单进程的并发模型是最简单的,每次只为一个客户端连接服务,直到读写失败或者客户端关闭了连接。对应的代码如下所示。
#include <sys/socket.h>
#include <unistd.h>
#include <iostream>
#include "../../common/cmdline.h"
#include "../../common/utils.hpp"
using namespace std;
using namespace MyEcho;
void handlerClient(int client_fd) {
string msg;
while (true) {
if (not RecvMsg(client_fd, msg)) {
return;
}
if (not SendMsg(client_fd, msg)) {
return;
}
}
}
void usage() {
cout << "SingleProcess -ip 0.0.0.0 -port 1688" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << endl;
}
int main(int argc, char* argv[]) {
string ip;
int64_t port;
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
int sock_fd = CreateListenSocket(ip, port, false);
if (sock_fd < 0) {
return -1;
}
while (true) {
int client_fd = accept(sock_fd, NULL, 0);
if (client_fd < 0) {
perror("accept failed");
continue;
}
handlerClient(client_fd);
close(client_fd);
}
return 0;
}在main函数中,开启网络监听之后,就陷入死循环,在循序中获取客户端的连接,并处理客户端的请求。
(2) MultiProcess
多进程的并发模型是专门为每个客户端连接创建一个进程,进程服务完客户端之后再退出。对应的代码如下所示。
#include <signal.h>
#include <sys/socket.h>
#include <unistd.h>
#include <iostream>
#include "../../common/cmdline.h"
#include "../../common/utils.hpp"
using namespace std;
using namespace MyEcho;
void handlerClient(int client_fd) {
string msg;
while (true) {
if (not RecvMsg(client_fd, msg)) {
return;
}
if (not SendMsg(client_fd, msg)) {
return;
}
}
}
void childExitSignalHandler() {
struct sigaction act;
act.sa_handler = SIG_IGN; //设置信号处理函数,这里忽略子进程的退出信号
sigemptyset(&act.sa_mask); //信号屏蔽设置为空
act.sa_flags = 0; //标志位设置为0
sigaction(SIGCHLD, &act, NULL);
}
void usage() {
cout << "MultiProcess -ip 0.0.0.0 -port 1688" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << endl;
}
int main(int argc, char* argv[]) {
string ip;
int64_t port;
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
int sock_fd = CreateListenSocket(ip, port, false);
if (sock_fd < 0) {
return -1;
}
childExitSignalHandler(); // 这里需要忽略子进程退出信号,否则会导致大量的僵尸进程,服务后续无法再创建子进程
while (true) {
int client_fd = accept(sock_fd, NULL, 0);
if (client_fd < 0) {
perror("accept failed");
continue;
}
pid_t pid = fork();
if (pid == -1) {
close(client_fd);
perror("fork failed");
continue;
}
if (pid == 0) { // 子进程
handlerClient(client_fd);
close(client_fd);
exit(0); // 处理完请求,子进程直接退出
} else {
close(client_fd); // 父进程直接关闭客户端连接,否则文件描述符会泄露
}
}
return 0;
}在main函数中,开启网络监听之后,就陷入死循环。在循环中,每获取到一个客户端的连接,就调用fork函数创建一个子进程,并在子进程中处理客户端的请求,处理完客户端的请求之后,子进程就直接退出。
(3) MultiThread
多进程的并发模型是专门为每个客户端连接创建一个线程,线程服务完客户端之后再退出。对应的代码如下所示。
#include <sys/socket.h>
#include <unistd.h>
#include <iostream>
#include <thread>
#include "../../common/cmdline.h"
#include "../../common/utils.hpp"
using namespace std;
using namespace MyEcho;
void handlerClient(int client_fd) {
string msg;
while (true) {
if (not RecvMsg(client_fd, msg)) {
break;
}
if (not SendMsg(client_fd, msg)) {
break;
}
}
close(client_fd);
}
void usage() {
cout << "MultiThread -ip 0.0.0.0 -port 1688" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << endl;
}
int main(int argc, char* argv[]) {
string ip;
int64_t port;
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
int sock_fd = CreateListenSocket(ip, port, false);
if (sock_fd < 0) {
return -1;
}
while (true) {
int client_fd = accept(sock_fd, NULL, 0);
if (client_fd < 0) {
perror("accept failed");
continue;
}
std::thread(handlerClient, client_fd).detach(); // 这里需要调用detach,让创建的线程独立运行
}
return 0;
}在main函数中,开启网络监听之后,就陷入死循环。在循环中,每获取到一个客户端的连接,就调用thread函数创建一个子线程,并在子线程中处理客户端的请求,处理完客户端的请求之后,子线程就直接退出。
(4) ProcessPool1
多进程的并发模型需要频繁的创建和销毁进程,这会导致系统开销高,资源占用较多。而进程池的并发模型,则是预先创建指定数量的进程,每个进程不退出,而是一直为不同的客户端提供服务。这种模型可以减少进程的创建和销毁,从而提高系统的并发处理能力,降低系统开销和资源占用。对应的代码如下所示。
#include <sys/socket.h>
#include <unistd.h>
#include <iostream>
#include "../../common/cmdline.h"
#include "../../common/utils.hpp"
using namespace std;
using namespace MyEcho;
void handlerClient(int client_fd, int64_t& count) {
string msg;
while (true) {
if (not RecvMsg(client_fd, msg)) {
return;
}
if (not SendMsg(client_fd, msg)) {
return;
}
count++;
}
}
void handler(int worker_id, int sock_fd) {
int64_t count = 0;
while (true) {
int client_fd = accept(sock_fd, NULL, 0);
if (client_fd < 0) {
perror("accept failed");
continue;
}
handlerClient(client_fd, count);
close(client_fd);
count++;
if (count >= 10000) {
cout << "worker_id[" << worker_id << "] deal_1w_request" << endl;
count = 0;
}
}
}
void usage() {
cout << "ProcessPool1 -ip 0.0.0.0 -port 1688" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << endl;
}
int main(int argc, char* argv[]) {
string ip;
int64_t port;
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
int sock_fd = CreateListenSocket(ip, port, false);
if (sock_fd < 0) {
return -1;
}
for (int i = 0; i < GetNProcs(); i++) {
pid_t pid = fork();
if (pid < 0) {
perror("fork failed");
continue;
}
if (0 == pid) {
handler(i, sock_fd); // 子进程陷入死循环,处理客户端请求
exit(0);
}
}
while (true) sleep(1); // 父进程陷入死循环
return 0;
}在main函数中,开启监听之后,根据系统当前可用的CPU核数,预先创建数量与之相等的子进程。每个子进程都陷入死循环一直监听客户端连接的到来并给客户端提供服务。
(5) ProcessPool2
在前面的进程池并发模型中,所有的子进程都会调用accept函数来接受新的客户端连接。这种方式存在竞争,当客户端新的连接到来时,多个子进程之间会争夺接受连接的机会。在操作系统内核2.6版本之前,所有子进程都会被唤醒,但只有一个可以accept成功,其他失败,并设置EGAIN错误码。这种方式会导致不必要的系统调用,降低系统的性能。
在内核2.6版本及之后,新增了互斥等待变量,只有一个子进程会被唤醒,减少了不必要的系统调用,提高了系统的性能。这种方式称为"惊群"问题的解决方案,可以有效地避免不必要的系统调用,提高系统的并发处理能力。
虽然内核2.6版本及之后只有一个子进程被唤醒,但仍然存在互斥等待,这种方式并不够优雅。我们可以使用socket套接字的SO_REUSEPORT选项,让多个进程同时监听在相同的网络地址(IP+Port)上,内核会自动在多个进程之间做连接的负载均衡,而不存在互斥等待行为,从而提高系统的性能和可靠性。
对应的代码如下所示。
#include <sys/socket.h>
#include <unistd.h>
#include <iostream>
#include "../../common/cmdline.h"
#include "../../common/utils.hpp"
using namespace std;
using namespace MyEcho;
void handlerClient(int client_fd, int64_t& count) {
string msg;
while (true) {
if (not RecvMsg(client_fd, msg)) {
return;
}
if (not SendMsg(client_fd, msg)) {
return;
}
count++;
}
}
void handler(int worker_id, string ip, int64_t port) {
// 开启SO_REUSEPORT选项
int sock_fd = CreateListenSocket(ip, port, true);
if (sock_fd < 0) {
return;
}
int64_t count = 0;
while (true) {
int client_fd = accept(sock_fd, NULL, 0);
if (client_fd < 0) {
perror("accept failed");
continue;
}
handlerClient(client_fd, count);
close(client_fd);
if (count >= 10000) {
cout << "worker_id[" << worker_id << "] deal_1w_request" << endl;
count = 0;
}
}
}
void usage() {
cout << "ProcessPool2 -ip 0.0.0.0 -port 1688" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << endl;
}
int main(int argc, char* argv[]) {
string ip;
int64_t port;
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
for (int i = 0; i < GetNProcs(); i++) {
pid_t pid = fork();
if (pid < 0) {
perror("fork failed");
continue;
}
if (0 == pid) {
handler(i, ip, port); // 子进程陷入死循环,处理客户端请求
exit(0);
}
}
while (true) sleep(1); // 父进程陷入死循环
return 0;
}在main函数中,我们根据系统当前可用的CPU核数,预先创建数量与之相等的子进程。每个子进程都创建自己的socket套接字,设置SO_REUSEPORT选项,并在相同的网络地址开启监听。最后,每个子进程都陷入死循环,等待客户端请求的到来,并为其提供服务。
(6) ThreadPool
在线程池的并发模型中,我们预先创建指定数量的线程,每个线程都不退出,一直等待客户端连接的到来,并为其提供服务。这种方式可以避免频繁地创建和销毁线程,提高系统的性能和效率,同时也可以降低系统的开销和资源占用。线程池并发模型的代码如下所示。
#include <arpa/inet.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <unistd.h>
#include <iostream>
#include <thread>
#include "../../common/cmdline.h"
#include "../../common/utils.hpp"
using namespace std;
using namespace MyEcho;
void handlerClient(int client_fd) {
string msg;
while (true) {
if (not RecvMsg(client_fd, msg)) {
return;
}
if (not SendMsg(client_fd, msg)) {
return;
}
}
}
void handler(string ip, int64_t port) {
// 开启SO_REUSEPORT选项
int sock_fd = CreateListenSocket(ip, port, true);
if (sock_fd < 0) {
return;
}
while (true) {
int client_fd = accept(sock_fd, NULL, 0);
if (client_fd < 0) {
perror("accept failed");
continue;
}
handlerClient(client_fd);
close(client_fd);
}
}
void usage() {
cout << "ThreadPool -ip 0.0.0.0 -port 1688" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << endl;
}
int main(int argc, char* argv[]) {
string ip;
int64_t port;
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
for (int i = 0; i < GetNProcs(); i++) {
std::thread(handler, ip, port).detach(); // 这里需要调用detach,让创建的线程独立运行
}
while (true) sleep(1); // 主线程陷入死循环
return 0;
}在main函数中,我们根据系统当前可用的CPU核数,预先创建数量与之相等的线程。每个线程都创建自己的socket套接字,设置SO_REUSEPORT选项,并在相同的网络地址开启监听。最后,每个线程都陷入死循环,等待客户端请求的到来,并为其提供服务。
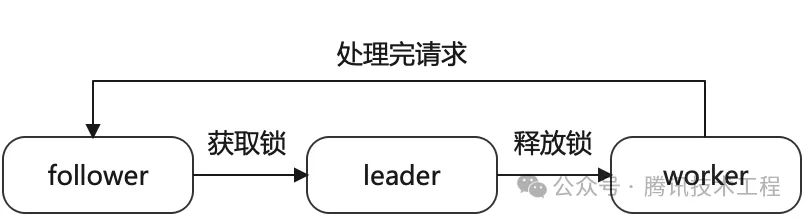
(7) LeaderAndFollower
线程池的并发模型中,线程之间的关系是对等的。领导者/跟随者的并发模型是线程池的一种变种,一开始所有的线程都是follower,它们会竞争上岗,有一个线程成为leader。leader线程会监听客户端连接的到来,接受到客户端的连接时,它会放弃领导权,由其他follower去竞争。此时leader线程变成了worker线程,为新来的客户端提供服务。领导者/跟随者并发模型的代码如下所示。
#include <sys/socket.h>
#include <unistd.h>
#include <iostream>
#include <mutex>
#include <thread>
#include "../../common/cmdline.h"
#include "../../common/utils.hpp"
using namespace std;
using namespace MyEcho;
std::mutex Mutex;
void handlerClient(int client_fd) {
string msg;
while (true) {
if (not RecvMsg(client_fd, msg)) {
return;
}
if (not SendMsg(client_fd, msg)) {
return;
}
}
}
void handler(int sock_fd) {
while (true) {
int client_fd;
// follower等待获取锁,成为leader
{
std::lock_guard<std::mutex> guard(Mutex);
client_fd = accept(sock_fd, NULL, 0); // 获取锁,并获取客户端的连接
if (client_fd < 0) {
perror("accept failed");
continue;
}
}
handlerClient(client_fd); // 处理每个客户端请求
close(client_fd);
}
}
void usage() {
cout << "LeaderAndFollower -ip 0.0.0.0 -port 1688" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << endl;
}
int main(int argc, char* argv[]) {
string ip;
int64_t port;
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
int sock_fd = CreateListenSocket(ip, port, false);
if (sock_fd < 0) {
return -1;
}
for (int i = 0; i < GetNProcs(); i++) {
std::thread(handler, sock_fd).detach(); // 这里需要调用detach,让创建的线程独立运行
}
while (true) sleep(1); // 主进程陷入死循环
return 0;
}在 main 函数中,首先会开启监听,然后根据系统当前可用的 CPU 核数,预先创建相同数量的线程。主线程会进入一个死循环,而所有从线程都会尝试获取锁。获取到锁的线程会开始监听客户端连接的到来,一旦有客户端连接到来,该线程会释放锁,并开始处理客户端的请求。其他线程则会继续尝试获取锁,以等待下一个客户端连接的到来。每个从线程的状态迁移如下图所示:
5.1.8 性能压测与对比:
- 压测运行环境:云开发机,16核32G的CentOS主机,每个CPU的频率为2.59GHz。(被压测的服务和压测工具都运行在同一台云主机上)
- 压测的参数为:一个线程、单个请求包1k、单客户端单次最多请求40次、64个客户端、压测60秒、限频20万qps。
- 压测命令:BenchMark -ip 0.0.0.0 -port 1688 -thread_count 1 -max_req_count 40 -pkt_size 1024 -client_count 64 -run_time 60 -rate_limit 200000
所有简单模型压测后的性能指标如下表所示:
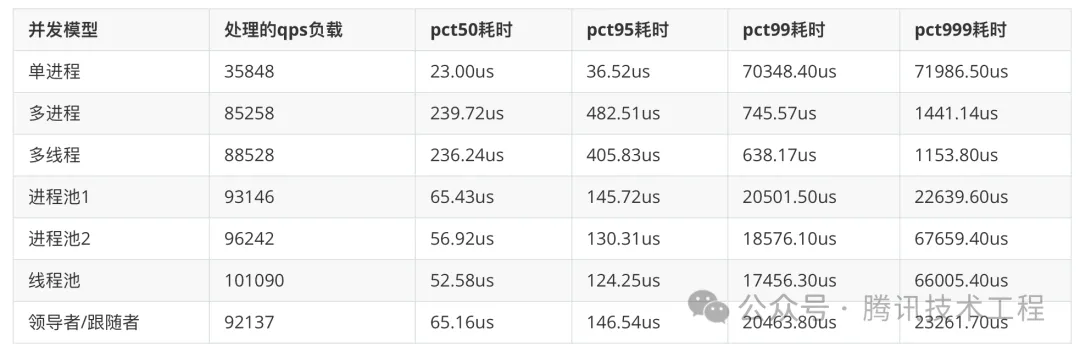
从上表的数据中,我们可以得出以下结论:
- 我们可以看到单进程的并发模型性能是最差的。
- 多进程和多线程的并发模型,由于能使用到多个CPU,所以性能有所提升,但是因为需要频繁的创建和销毁进程和线程,接口的pct50和pct95耗时较高。
- 进程池1和进程池2的并发模型,由于没有频繁的创建和销毁进程和线程的损耗,性能比多进程和多线程的并发模型高,接口的pct50和pct95耗时也更低。
- 进程池2并发模型接口的pct999耗时比进程池1并发模型的高出不少,这个是因为进程池2的并发模型是由操作系统来做负载均衡的,但这个策略并无法保证对流量负载做完美的均分,导致接口长尾的耗时较高,而进程池1的并发模型是多进程抢锁,每个进程的流量负载会更均衡,但因为有锁,所以进程池1的并发模型性能比进程池2的并发模型低一些。
- 线程池的并发模型和进程池2的并发模型,性能差异并不是很大,因为线程池的并发模型也是由操作系统来做负载均衡的,所以存在接口长尾的耗时较高的情况。
- 领导者/跟随者的并发模型和进程池1的并发模型很相似,这两个模型所有的指标都差异很小,领导者/跟随者的并发模型可以看到显式的使用锁,而进程池1的并发模型没有。
2. 多路I/O复用简单模型
(1) Select
多路I/O复用最早支持的系统调用是select函数,select函数存在天然的缺陷,因为select函数最多支持对1024个文件描述的事件进行监听,且文件描述符的值必须小于1024,而1024这个值是由FD_SETSIZE这个宏来决定的。使用select函数实现的并发模型代码如下所示:
#include <stdio.h>
#include <unistd.h>
#include <iostream>
#include <unordered_set>
#include "../../common/cmdline.h"
#include "../../common/utils.hpp"
using namespace std;
using namespace MyEcho;
void updateReadSet(unordered_set<int> &read_fds, int &max_fd, int sock_fd, fd_set &read_set) {
max_fd = sock_fd;
FD_ZERO(&read_set);
for (const auto &read_fd : read_fds) {
if (read_fd > max_fd) {
max_fd = read_fd;
}
FD_SET(read_fd, &read_set);
}
}
void handlerClient(int client_fd) {
string msg;
while (true) {
if (not RecvMsg(client_fd, msg)) {
return;
}
if (not SendMsg(client_fd, msg)) {
return;
}
}
}
void usage() {
cout << "Select -ip 0.0.0.0 -port 1688" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << endl;
}
int main(int argc, char *argv[]) {
string ip;
int64_t port;
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
int sock_fd = CreateListenSocket(ip, port, false);
if (sock_fd < 0) {
return -1;
}
int max_fd;
fd_set read_set;
SetNotBlock(sock_fd);
unordered_set<int> read_fds;
while (true) {
read_fds.insert(sock_fd);
updateReadSet(read_fds, max_fd, sock_fd, read_set);
int ret = select(max_fd + 1, &read_set, NULL, NULL, NULL);
if (ret <= 0) {
if (ret < 0) perror("select failed");
continue;
}
for (int i = 0; i <= max_fd; i++) {
if (not FD_ISSET(i, &read_set)) {
continue;
}
if (i == sock_fd) { // 监听的sock_fd可读,则表示有新的链接
LoopAccept(sock_fd, 1024, [&read_fds](int client_fd) {
if (client_fd >= FD_SETSIZE) { // 大于FD_SETSIZE的值,则不支持
close(client_fd);
return;
}
read_fds.insert(client_fd); // 新增到要监听的fd集合中
});
continue;
}
handlerClient(i);
read_fds.erase(i);
close(i);
}
}
return 0;
}在main函数中,使用select函数来监听所有客户端连接上的可读事件,如果客户端文件描述符值大于等于FD_SETSIZE,则直接关闭客户端的链接。当客户端连接上有可读事件发生时,就处理对应客户端连接上的请求,直到客户端关闭连接或者读写失败。
(2) Poll
为了解决select函数文件描述符数量和值的限制,Linux 系统后续新增了poll函数。与select不同的是,poll函数在没有触碰到系统其他限制之前,理论上只要内存充足,则可以支持监听的文件描述符数量是没有上限的。使用poll函数实现的并发模型代码如下所示:
#include <arpa/inet.h>
#include <netinet/in.h>
#include <poll.h>
#include <stdio.h>
#include <unistd.h>
#include <iostream>
#include <unordered_set>
#include "../../common/cmdline.h"
#include "../../common/utils.hpp"
using namespace std;
using namespace MyEcho;
void updateFds(std::unordered_set<int> &client_fds, pollfd **fds, int &nfds) {
if (*fds != nullptr) {
delete[](*fds);
}
nfds = client_fds.size();
*fds = new pollfd[nfds];
int index = 0;
for (const auto &client_fd : client_fds) {
(*fds)[index].fd = client_fd;
(*fds)[index].events = POLLIN;
(*fds)[index].revents = 0;
index++;
}
}
void handlerClient(int client_fd) {
string msg;
while (true) {
if (not RecvMsg(client_fd, msg)) {
return;
}
if (not SendMsg(client_fd, msg)) {
return;
}
}
}
void usage() {
cout << "Poll -ip 0.0.0.0 -port 1688" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << endl;
}
int main(int argc, char *argv[]) {
string ip;
int64_t port;
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
int sock_fd = CreateListenSocket(ip, port, false);
if (sock_fd < 0) {
return -1;
}
int nfds = 0;
pollfd *fds = nullptr;
std::unordered_set<int> client_fds;
client_fds.insert(sock_fd);
SetNotBlock(sock_fd);
while (true) {
updateFds(client_fds, &fds, nfds);
int ret = poll(fds, nfds, -1);
if (ret <= 0) {
if (ret < 0) perror("poll failed");
continue;
}
for (int i = 0; i < nfds; i++) {
if (not(fds[i].revents & POLLIN)) {
continue;
}
int current_fd = fds[i].fd;
if (current_fd == sock_fd) {
LoopAccept(sock_fd, 1024, [&client_fds](int client_fd) {
client_fds.insert(client_fd); // 新增到要监听的fd集合中
});
continue;
}
handlerClient(current_fd);
client_fds.erase(current_fd);
close(current_fd);
}
}
return 0;
}在main函数中,使用poll函数来监听所有客户端连接上的可读事件,当客户端连接上有可读事件发生时,就处理对应客户端连接上的请求,直到客户端关闭连接或者读写失败。
(3) Epoll
epoll是poll的一种变种,它通过事件注册和通知机制,有效提升了事件监听效率,并且对更大数量文件描述符的监听有更好的可扩展性。相比于poll和select,epoll更加高效,能够处理更多的连接。使用epoll函数实现的并发模型代码如下所示。
#include <arpa/inet.h>
#include <assert.h>
#include <netinet/in.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include <sys/socket.h>
#include <unistd.h>
#include <iostream>
#include "../../common/cmdline.h"
#include "../../common/epollctl.hpp"
using namespace std;
using namespace MyEcho;
void handlerClient(int client_fd) {
string msg;
while (true) {
if (not RecvMsg(client_fd, msg)) {
return;
}
if (not SendMsg(client_fd, msg)) {
return;
}
}
}
void usage() {
cout << "Epoll -ip 0.0.0.0 -port 1688 -la" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << " -la,--la loop accept" << endl;
cout << endl;
}
int main(int argc, char *argv[]) {
string ip;
int64_t port;
bool is_loop_accept;
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::BoolOpt(&is_loop_accept, "la");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
int sock_fd = CreateListenSocket(ip, port, false);
if (sock_fd < 0) {
return -1;
}
epoll_event events[2048];
int epoll_fd = epoll_create(1);
if (epoll_fd < 0) {
perror("epoll_create failed");
return -1;
}
cout << "loop_accept = " << is_loop_accept << endl;
Conn conn(sock_fd, epoll_fd, false);
SetNotBlock(sock_fd);
AddReadEvent(&conn);
while (true) {
int num = epoll_wait(epoll_fd, events, 2048, -1);
if (num < 0) {
perror("epoll_wait failed");
continue;
}
for (int i = 0; i < num; i++) {
Conn *conn = (Conn *)events[i].data.ptr;
if (conn->Fd() == sock_fd) {
int max_conn = is_loop_accept ? 2048 : 1;
LoopAccept(sock_fd, max_conn, [epoll_fd](int client_fd) {
Conn *conn = new Conn(client_fd, epoll_fd, false);
AddReadEvent(conn); // 监听可读事件,保持fd为阻塞IO
});
continue;
}
handlerClient(conn->Fd());
ClearEvent(conn);
delete conn;
}
}
return 0;
}在main函数中,使用epoll函数来监听所有客户端连接上的可读事件,当客户端连接上有可读事件发生时,就处理对应客户端连接上的请求,直到客户端关闭连接或者读写失败。
(4) 性能压测与对比
- 压测运行环境:云开发机,16核32G的CentOS主机,每个CPU的频率为2.59GHz。(被压测的服务和压测工具都运行在同一台云主机上)
- 压测的参数为:一个线程、单个请求包1k、单客户端单次最多请求40次、64个客户端、压测60秒、限频20万qps。
- 压测命令:BenchMark -ip 0.0.0.0 -port 1688 -thread_count 1 -max_req_count 40 -pkt_size 1024 -client_count 64 -run_time 60 -rate_limit 200000
多路I/O复用简单模型压测后的性能指标如下表所示。

从上表的数据中,我们可以得出以下结论:
- 如果仅仅只是把IO复用的事件监听当做简单的客户端处理的触发器,则这3个并发模型和单进程的并发模型的所有指标没什么差异,它们在同一时间只有一个客户端请求在被处理。
- 当然poll和epoll可以支持更多的客户端连接。
3. Reactor相关模型
最后介绍的10种不同的并发模型,都是Reactor模型相关的,最基础的Reactor并发模型如下图所示。

(1) SelectReactorSingleProcess
使用select函数可以实现Reactor的并发模型,相关的代码如下所示:
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#include <iostream>
#include <unordered_map>
#include <unordered_set>
#include "../../common/cmdline.h"
#include "../../common/conn.hpp"
using namespace std;
using namespace MyEcho;
void updateSet(unordered_set<int> &read_fds, unordered_set<int> &write_fds, int &max_fd, int sock_fd, fd_set &read_set,
fd_set &write_set) {
max_fd = sock_fd;
FD_ZERO(&read_set);
FD_ZERO(&write_set);
for (const auto &read_fd : read_fds) {
if (read_fd > max_fd) {
max_fd = read_fd;
}
FD_SET(read_fd, &read_set);
}
for (const auto &write_fd : write_fds) {
if (write_fd > max_fd) {
max_fd = write_fd;
}
FD_SET(write_fd, &write_set);
}
}
void usage() {
cout << "SelectReactorSingleProcess -ip 0.0.0.0 -port 1688" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << endl;
}
int main(int argc, char *argv[]) {
string ip;
int64_t port;
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
int sock_fd = CreateListenSocket(ip, port, false);
if (sock_fd < 0) {
return -1;
}
int max_fd;
fd_set read_set;
fd_set write_set;
SetNotBlock(sock_fd);
unordered_set<int> read_fds;
unordered_set<int> write_fds;
unordered_map<int, Conn *> conns;
while (true) {
read_fds.insert(sock_fd);
updateSet(read_fds, write_fds, max_fd, sock_fd, read_set, write_set);
int ret = select(max_fd + 1, &read_set, &write_set, nullptr, nullptr);
if (ret <= 0) {
if (ret < 0) perror("select failed");
continue;
}
unordered_set<int> temp = read_fds;
for (const auto &fd : temp) {
if (not FD_ISSET(fd, &read_set)) {
continue;
}
if (fd == sock_fd) { // 监听的sock_fd可读,则表示有新的链接
LoopAccept(sock_fd, 1024, [&read_fds, &conns](int client_fd) {
if (client_fd >= FD_SETSIZE) { // 大于FD_SETSIZE的值,则不支持
close(client_fd);
return;
}
read_fds.insert(client_fd); // 新增到要监听的fd集合中
conns[client_fd] = new Conn(client_fd, true);
});
continue;
}
// 执行到这里,表明可读
Conn *conn = conns[fd];
if (not conn->Read()) { // 执行读失败
delete conn;
conns.erase(fd);
read_fds.erase(fd);
close(fd);
continue;
}
if (conn->OneMessage()) { // 判断是否要触发写事件
conn->EnCode();
read_fds.erase(fd);
write_fds.insert(fd);
}
}
temp = write_fds;
for (const auto &fd : temp) {
if (not FD_ISSET(fd, &write_set)) {
continue;
}
// 执行到这里,表明可写
Conn *conn = conns[fd];
if (not conn->Write()) { // 执行写失败
delete conn;
conns.erase(fd);
write_fds.erase(fd);
close(fd);
continue;
}
if (conn->FinishWrite()) { // 完成了请求的应答写
conn->Reset();
write_fds.erase(fd);
read_fds.insert(fd);
}
}
}
return 0;
}在main函数中,我们使用select函数来监听多个客户端连接上的事件,因为select函数最大支持FD_SETSIZE个文件描述符,所以对于不支持的客户端连接,则直接关闭连接。select函数每次调用之前都需要重新更新一遍要监听的读写事件的文件描述符的集合。
(2) PollReactorSingleProcess
使用poll函数也可以实现Reactor的并发模型,相关的代码如下所示:
#include <poll.h>
#include <stdio.h>
#include <unistd.h>
#include <iostream>
#include <unordered_map>
#include <unordered_set>
#include "../../common/cmdline.h"
#include "../../common/conn.hpp"
#include "../../common/utils.hpp"
using namespace std;
using namespace MyEcho;
void updateFds(unordered_set<int> &read_fds, unordered_set<int> &write_fds, pollfd **fds, int &nfds) {
if (*fds != nullptr) {
delete[](*fds);
}
nfds = read_fds.size() + write_fds.size();
*fds = new pollfd[nfds];
int index = 0;
for (const auto &read_fd : read_fds) {
(*fds)[index].fd = read_fd;
(*fds)[index].events = POLLIN;
(*fds)[index].revents = 0;
index++;
}
for (const auto &write_fd : write_fds) {
(*fds)[index].fd = write_fd;
(*fds)[index].events = POLLOUT;
(*fds)[index].revents = 0;
index++;
}
}
void usage() {
cout << "PollReactorSingleProcess -ip 0.0.0.0 -port 1688" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << endl;
}
int main(int argc, char *argv[]) {
string ip;
int64_t port;
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
int sock_fd = CreateListenSocket(ip, port, false);
if (sock_fd < 0) {
return -1;
}
int nfds = 0;
pollfd *fds = nullptr;
unordered_set<int> read_fds;
unordered_set<int> write_fds;
unordered_map<int, Conn *> conns;
SetNotBlock(sock_fd);
while (true) {
read_fds.insert(sock_fd);
updateFds(read_fds, write_fds, &fds, nfds);
int ret = poll(fds, nfds, -1);
if (ret <= 0) {
if (ret < 0) perror("poll failed");
continue;
}
for (int i = 0; i < nfds; i++) {
if (fds[i].revents & POLLIN) {
int fd = fds[i].fd;
if (fd == sock_fd) {
LoopAccept(sock_fd, 2048, [&read_fds, &conns](int client_fd) {
read_fds.insert(client_fd); // 新增到要监听的fd集合中
conns[client_fd] = new Conn(client_fd, true);
});
continue;
}
// 执行到这里,表明可读
Conn *conn = conns[fd];
if (not conn->Read()) { // 执行读失败
delete conn;
conns.erase(fd);
read_fds.erase(fd);
close(fd);
continue;
}
if (conn->OneMessage()) { // 判断是否要触发写事件
conn->EnCode();
read_fds.erase(fd);
write_fds.insert(fd);
}
}
if (fds[i].revents & POLLOUT) { // 可写
int fd = fds[i].fd;
Conn *conn = conns[fd];
if (not conn->Write()) { // 执行写失败
delete conn;
conns.erase(fd);
write_fds.erase(fd);
close(fd);
continue;
}
if (conn->FinishWrite()) { // 完成了请求的应答写
conn->Reset();
write_fds.erase(fd);
read_fds.insert(fd);
}
}
}
}
return 0;
}在main函数中,我们使用poll函数来监听多个客户端连接上的事件,poll函数没有文件描述符数量的限制。同样的poll函数每次调用之前都需要重新更新一遍要监听的读写事件的文件描述符的集合。
(3) EpollReactorSingleProcess
使用epoll函数也可以实现Reactor的并发模型,相关的代码如下所示:
#include <arpa/inet.h>
#include <assert.h>
#include <fcntl.h>
#include <netinet/in.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include <sys/socket.h>
#include <unistd.h>
#include <iostream>
#include "../../common/cmdline.h"
#include "../../common/epollctl.hpp"
using namespace std;
using namespace MyEcho;
void usage() {
cout << "EpollReactorSingleProcess -ip 0.0.0.0 -port 1688 -multiio -la -writefirst" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << " -multiio,--multiio multi io" << endl;
cout << " -la,--la loop accept" << endl;
cout << " -writefirst--writefirst write first" << endl;
cout << endl;
}
int main(int argc, char *argv[]) {
string ip;
int64_t port;
bool is_multi_io;
bool is_loop_accept;
bool is_write_first;
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::BoolOpt(&is_multi_io, "multiio");
CmdLine::BoolOpt(&is_loop_accept, "la");
CmdLine::BoolOpt(&is_write_first, "writefirst");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
cout << "is_loop_accept = " << is_loop_accept << endl;
cout << "is_multi_io = " << is_multi_io << endl;
cout << "is_write_first = " << is_write_first << endl;
int sock_fd = CreateListenSocket(ip, port, false);
if (sock_fd < 0) {
return -1;
}
epoll_event events[2048];
int epoll_fd = epoll_create(1);
if (epoll_fd < 0) {
perror("epoll_create failed");
return -1;
}
Conn conn(sock_fd, epoll_fd, is_multi_io);
SetNotBlock(sock_fd);
AddReadEvent(&conn);
while (true) {
int num = epoll_wait(epoll_fd, events, 2048, -1);
if (num < 0) {
perror("epoll_wait failed");
continue;
}
for (int i = 0; i < num; i++) {
Conn *conn = (Conn *)events[i].data.ptr;
if (conn->Fd() == sock_fd) {
int max_conn = is_loop_accept ? 2048 : 1;
LoopAccept(sock_fd, max_conn, [epoll_fd, is_multi_io](int client_fd) {
Conn *conn = new Conn(client_fd, epoll_fd, is_multi_io);
SetNotBlock(client_fd);
AddReadEvent(conn); // 监听可读事件
});
continue;
}
auto releaseConn = [&conn]() {
ClearEvent(conn);
delete conn;
};
if (events[i].events & EPOLLIN) { // 可读
if (not conn->Read()) { // 执行读失败
releaseConn();
continue;
}
if (conn->OneMessage()) { // 判断是否要触发写事件
conn->EnCode();
if (is_write_first) { // 判断是否要先写数据
if (not conn->Write()) {
releaseConn();
continue;
}
}
if (conn->FinishWrite()) {
conn->Reset();
ModToReadEvent(conn); // 修改成只监控可读事件
} else {
ModToWriteEvent(conn); // 修改成只监控可写事件
}
}
}
if (events[i].events & EPOLLOUT) { // 可写
if (not conn->Write()) { // 执行写失败
releaseConn();
continue;
}
if (conn->FinishWrite()) { // 完成了请求的应答写
conn->Reset();
ModToReadEvent(conn); // 修改成只监控可读事件
}
}
}
}
return 0;
}在main函数中,我们使用epoll函数来监听多个客户端连接上的事件,epoll函数没有文件描述符数量的限制。相反的epoll函数每次调用之前不需要重新更新一遍要监听的读写事件的文件描述符的集合,epoll函数的效率更高。
(4) EpollReactorSingleProcessET
上一个示例中我们使用的是epoll默认的水平触发模式,在本例中使用的是epoll的边缘模式来实现Reactor的并发模型,相关的代码如下所示:
#include <arpa/inet.h>
#include <assert.h>
#include <fcntl.h>
#include <netinet/in.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include <sys/socket.h>
#include <unistd.h>
#include <iostream>
#include "../../common/cmdline.h"
#include "../../common/epollctl.hpp"
using namespace std;
using namespace MyEcho;
void usage() {
cout << "EpollReactorSingleProcessET -ip 0.0.0.0 -port 1688" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << endl;
}
int main(int argc, char *argv[]) {
string ip;
int64_t port;
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
int sock_fd = CreateListenSocket(ip, port, false);
if (sock_fd < 0) {
return -1;
}
epoll_event events[2048];
int epoll_fd = epoll_create(1);
if (epoll_fd < 0) {
perror("epoll_create failed");
return -1;
}
Conn conn(sock_fd, epoll_fd, true);
SetNotBlock(sock_fd);
AddReadEvent(&conn);
while (true) {
int num = epoll_wait(epoll_fd, events, 2048, -1);
if (num < 0) {
perror("epoll_wait failed");
continue;
}
for (int i = 0; i < num; i++) {
Conn *conn = (Conn *)events[i].data.ptr;
if (conn->Fd() == sock_fd) {
LoopAccept(sock_fd, 2048, [epoll_fd](int client_fd) {
Conn *conn = new Conn(client_fd, epoll_fd, true);
SetNotBlock(client_fd);
AddReadEvent(conn, true); // 监听可读事件,开启边缘模式
});
continue;
}
auto releaseConn = [&conn]() {
ClearEvent(conn);
delete conn;
};
if (events[i].events & EPOLLIN) { // 可读
if (not conn->Read()) { // 执行非阻塞读
releaseConn();
continue;
}
if (conn->OneMessage()) { // 判断是否要触发写事件
conn->EnCode();
ModToWriteEvent(conn, true); // 修改成只监控可写事件,开启边缘模式
}
}
if (events[i].events & EPOLLOUT) { // 可写
if (not conn->Write()) { // 执行非阻塞写
releaseConn();
continue;
}
if (conn->FinishWrite()) { // 完成了了请求的应答写,则可以释放连接
conn->Reset();
ModToReadEvent(conn, true); // 修改成只监控可读事件
}
}
}
}
return 0;
}同上一个示例的区别在于,读写事件的监听都会切换成边缘模式,这里需要特别注意的是,启用边缘模式时,每次I/O的读写都要执行多次读写,直到返回EAGAIN或者EWOULDBLOCK的错误码为止。
(5) EpollReactorSingleProcessCoroutine
之前已经实现了简单的协程池。在当前示例中,我们将使用协程池配合epoll来实现Reactor的并发模型,相关的代码如下所示:
#include <arpa/inet.h>
#include <assert.h>
#include <fcntl.h>
#include <netinet/in.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include <sys/socket.h>
#include <unistd.h>
#include <iostream>
#include "../../common/cmdline.h"
#include "../../common/coroutine.h"
#include "../../common/epollctl.hpp"
using namespace std;
using namespace MyEcho;
struct EventData {
EventData(int fd, int epoll_fd) : fd_(fd), epoll_fd_(epoll_fd){};
int fd_{0};
int epoll_fd_{0};
int cid_{MyCoroutine::kInvalidRoutineId};
MyCoroutine::Schedule *schedule_{nullptr};
};
void EchoDeal(const std::string req_message, std::string &resp_message) { resp_message = req_message; }
void handlerClient(EventData *event_data) {
auto releaseConn = [&event_data]() {
ClearEvent(event_data->epoll_fd_, event_data->fd_);
delete event_data; // 释放内存
};
while (true) {
ssize_t ret = 0;
Codec codec;
string *req_message{nullptr};
string resp_message;
while (true) { // 读操作
ret = read(event_data->fd_, codec.Data(), codec.Len());
if (ret == 0) {
perror("peer close connection");
releaseConn();
return;
}
if (ret < 0) {
if (EINTR == errno) continue; // 被中断,可以重启读操作
if (EAGAIN == errno or EWOULDBLOCK == errno) {
MyCoroutine::CoroutineYield(*event_data->schedule_); // 让出cpu,切换到主协程,等待下一次数据可读
continue;
}
perror("read failed");
releaseConn();
return;
}
codec.DeCode(ret); // 解析请求数据
req_message = codec.GetMessage();
if (req_message) { // 解析出一个完整的请求
break;
}
}
// 执行到这里说明已经读取到一个完整的请求
EchoDeal(*req_message, resp_message); // 业务handler的封装,这样协程的调用就对业务逻辑函数EchoDeal透明
delete req_message;
Packet pkt;
codec.EnCode(resp_message, pkt);
ModToWriteEvent(event_data->epoll_fd_, event_data->fd_, event_data); // 监听可写事件。
size_t sendLen = 0;
while (sendLen != pkt.UseLen()) { // 写操作
ret = write(event_data->fd_, pkt.Data() + sendLen, pkt.UseLen() - sendLen);
if (ret < 0) {
if (EINTR == errno) continue; // 被中断,可以重启写操作
if (EAGAIN == errno or EWOULDBLOCK == errno) {
MyCoroutine::CoroutineYield(*event_data->schedule_); // 让出cpu,切换到主协程,等待下一次数据可写
continue;
}
perror("write failed");
releaseConn();
return;
}
sendLen += ret;
}
ModToReadEvent(event_data->epoll_fd_, event_data->fd_, event_data); // 监听可读事件。
}
}
void usage() {
cout << "EpollReactorSingleProcessCoroutine -ip 0.0.0.0 -port 1688 -d" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << " -d,--d dynamic epoll time out" << endl;
cout << endl;
}
int main(int argc, char *argv[]) {
string ip;
int64_t port;
bool is_dynamic_time_out{false};
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::BoolOpt(&is_dynamic_time_out, "d");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
int sock_fd = CreateListenSocket(ip, port, false);
if (sock_fd < 0) {
return -1;
}
epoll_event events[2048];
int epoll_fd = epoll_create(1);
if (epoll_fd < 0) {
perror("epoll_create failed");
return -1;
}
cout << "is_dynamic_time_out = " << is_dynamic_time_out << endl;
EventData event_data(sock_fd, epoll_fd);
SetNotBlock(sock_fd);
AddReadEvent(epoll_fd, sock_fd, &event_data);
MyCoroutine::Schedule schedule;
MyCoroutine::ScheduleInit(schedule, 5000); // 协程池初始化
int msec = -1;
while (true) {
int num = epoll_wait(epoll_fd, events, 2048, msec);
if (num < 0) {
perror("epoll_wait failed");
continue;
} else if (num == 0) { // 没有事件了,下次调用epoll_wait大概率被挂起
sleep(0); // 这里直接sleep(0)让出cpu,大概率被挂起,这里主动让出cpu,可以减少一次epoll_wait的调用
msec = -1; // 大概率被挂起,故这里超时时间设置为-1
continue;
}
if (is_dynamic_time_out) msec = 0; // 下次大概率还有事件,故msec设置为0
for (int i = 0; i < num; i++) {
EventData *event_data = (EventData *)events[i].data.ptr;
if (event_data->fd_ == sock_fd) {
LoopAccept(sock_fd, 2048, [epoll_fd](int client_fd) {
EventData *event_data = new EventData(client_fd, epoll_fd);
SetNotBlock(client_fd);
AddReadEvent(epoll_fd, client_fd, event_data); // 监听可读事件
});
continue;
}
if (event_data->cid_ == MyCoroutine::kInvalidRoutineId) { // 第一次事件,则创建协程
event_data->schedule_ = &schedule;
event_data->cid_ = MyCoroutine::CoroutineCreate(schedule, handlerClient, event_data); // 创建协程
MyCoroutine::CoroutineResumeById(schedule, event_data->cid_);
} else {
MyCoroutine::CoroutineResumeById(schedule, event_data->cid_); // 唤醒之前主动让出cpu的协程
}
}
}
return 0;
}在main函数中,我们创建了一个大小为5000的协程池。在处理客户端的请求时会单独创建一个协程来为客户端服务,在协程中如果遇到读写暂不可用,则会退出当前协程的执行,切换回主协程中执行,等到读写可用时再唤醒协程的执行。
(6) EpollReactorProcessPoolMS
Reactor并发模型还有一种变种,它将客户端连接的接受放在单独的MainReactor中,MainReactor再将客户端连接移交给SubReactor进行读写操作的处理。使用单独的线程来接受客户端连接可以更快地为新的客户端提供服务,因为同时处理的客户端连接数更多,从而提高了请求处理的并发度,从而更好地利用了CPU。Reactor-MS模型的交互简图如下所示。

我们使用了进程池的方式来实现Reactor-MS模型,相关的代码如下:
#include <arpa/inet.h>
#include <assert.h>
#include <fcntl.h>
#include <netinet/in.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include <sys/socket.h>
#include <unistd.h>
#include <algorithm>
#include <iostream>
#include <vector>
#include "../../common/cmdline.h"
#include "../../common/conn.hpp"
#include "../../common/epollctl.hpp"
using namespace std;
using namespace MyEcho;
void mainReactor(string ip, int64_t port, bool is_main_read, int64_t sub_reactor_count) {
vector<int> client_unix_sockets;
for (int i = 0; i < sub_reactor_count; i++) {
int fd = CreateClientUnixSocket("./unix.sock." + to_string(i));
assert(fd > 0);
client_unix_sockets.push_back(fd);
}
int index = 0;
int sock_fd = CreateListenSocket(ip, port, true);
assert(sock_fd > 0);
epoll_event events[2048];
int epoll_fd = epoll_create(1);
assert(epoll_fd > 0);
Conn conn(sock_fd, epoll_fd, true);
SetNotBlock(sock_fd);
AddReadEvent(&conn);
auto getClientUnixSocketFd = [&index, &client_unix_sockets, sub_reactor_count]() {
index++;
index %= sub_reactor_count;
return client_unix_sockets[index];
};
while (true) {
int num = epoll_wait(epoll_fd, events, 2048, -1);
if (num < 0) {
perror("epoll_wait failed");
continue;
}
for (int i = 0; i < num; i++) {
Conn *conn = (Conn *)events[i].data.ptr;
if (conn->Fd() == sock_fd) { // 有客户端的连接到来了
LoopAccept(sock_fd, 2048, [is_main_read, epoll_fd, getClientUnixSocketFd](int client_fd) {
SetNotBlock(client_fd);
if (is_main_read) {
Conn *conn = new Conn(client_fd, epoll_fd, true);
AddReadEvent(conn); // 在mainReactor线程中监听可读事件
} else {
SendFd(getClientUnixSocketFd(), client_fd);
close(client_fd);
}
});
continue;
}
// 客户端有数据可读,则把连接迁移到subReactor线程中管理
ClearEvent(conn, false);
SendFd(getClientUnixSocketFd(), conn->Fd());
close(conn->Fd());
delete conn;
}
}
}
void subReactor(int server_unix_socket, int64_t sub_reactor_count) {
epoll_event events[2048];
int epoll_fd = epoll_create(1);
if (epoll_fd < 0) {
perror("epoll_create failed");
return;
}
Conn conn(server_unix_socket, epoll_fd, true);
SetNotBlock(server_unix_socket);
AddReadEvent(&conn);
while (true) {
int num = epoll_wait(epoll_fd, events, 2048, -1);
if (num < 0) {
perror("epoll_wait failed");
continue;
}
for (int i = 0; i < num; i++) {
Conn *conn = (Conn *)events[i].data.ptr;
auto releaseConn = [&conn]() {
ClearEvent(conn);
delete conn;
};
if (conn->Fd() == server_unix_socket) {
// 接受从mainReactor过来的连接
LoopAccept(server_unix_socket, 1024, [epoll_fd](int main_reactor_client_fd) {
Conn *conn = new Conn(main_reactor_client_fd, epoll_fd, true);
conn->SetUnixSocket();
AddReadEvent(conn);
cout << "accept mainReactor unix_socet connect. pid = " << getpid() << endl;
});
continue;
}
if (conn->IsUnixSocket()) {
int client_fd = 0;
// 接收从mainReactor传递过来的客户端连接fd
if (0 == RecvFd(conn->Fd(), client_fd)) {
Conn *conn = new Conn(client_fd, epoll_fd, true);
AddReadEvent(conn);
}
continue;
}
// 执行到这里就是真正的客户端的读写事件
if (events[i].events & EPOLLIN) { // 可读
if (not conn->Read()) { // 执行非阻塞读
releaseConn();
continue;
}
if (conn->OneMessage()) { // 判断是否要触发写事件
conn->EnCode();
ModToWriteEvent(conn); // 修改成只监控可写事件
}
}
if (events[i].events & EPOLLOUT) { // 可写
if (not conn->Write()) { // 执行非阻塞写
releaseConn();
continue;
}
if (conn->FinishWrite()) { // 完成了请求的应答写,则可以释放连接
conn->Reset();
ModToReadEvent(conn); // 修改成只监控可读事件
}
}
}
}
}
void createServerUnixSocket(vector<int> &server_unix_sockets, int64_t sub_reactor_count) {
for (int i = 0; i < sub_reactor_count; i++) {
string path = "./unix.sock." + to_string(i);
remove(path.c_str());
int server_unix_socket = CreateListenUnixSocket(path);
assert(server_unix_socket > 0);
server_unix_sockets.push_back(server_unix_socket);
}
}
void createSubReactor(vector<int> &server_unix_sockets, int64_t sub_reactor_count) {
for (int i = 0; i < sub_reactor_count; i++) {
pid_t pid = fork();
assert(pid != -1);
if (pid == 0) { // 子进程
int fd = server_unix_sockets[i];
// 关闭不需要的fd,避免fd泄漏
for_each(server_unix_sockets.begin(), server_unix_sockets.end(), [fd](int server_unix_socket_fd) {
if (server_unix_socket_fd != fd) {
close(server_unix_socket_fd);
}
});
cout << "subReactor pid = " << getpid() << endl;
subReactor(fd, sub_reactor_count);
exit(0);
}
}
}
void createMainReactor(string ip, int64_t port, bool is_main_read, int64_t sub_reactor_count,
int64_t main_reactor_count) {
for (int i = 0; i < main_reactor_count; i++) {
pid_t pid = fork();
assert(pid != -1);
if (pid == 0) { // 子进程
cout << "mainReactor pid = " << getpid() << endl;
mainReactor(ip, port, is_main_read, sub_reactor_count);
exit(0);
}
}
}
void usage() {
cout << "EpollReactorProcessPoolMS -ip 0.0.0.0 -port 1688 -main 3 -sub 8 -mainread" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << " -main,--main mainReactor count" << endl;
cout << " -sub,--sub subReactor count" << endl;
cout << " -mainread,--mainread mainReactor read" << endl;
cout << endl;
}
int main(int argc, char *argv[]) {
string ip;
int64_t port;
int64_t main_reactor_count;
int64_t sub_reactor_count;
bool is_main_read;
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::Int64OptRequired(&main_reactor_count, "main");
CmdLine::Int64OptRequired(&sub_reactor_count, "sub");
CmdLine::BoolOpt(&is_main_read, "mainread");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
main_reactor_count = main_reactor_count > GetNProcs() ? GetNProcs() : main_reactor_count;
sub_reactor_count = sub_reactor_count > GetNProcs() ? GetNProcs() : sub_reactor_count;
vector<int> server_unix_sockets;
createServerUnixSocket(server_unix_sockets, sub_reactor_count);
createSubReactor(server_unix_sockets, sub_reactor_count); // 创建SubReactor进程
// 不再需要这些fd,需要及时关闭,避免fd泄漏
for_each(server_unix_sockets.begin(), server_unix_sockets.end(), [](int fd) { close(fd); });
createMainReactor(ip, port, is_main_read, sub_reactor_count, main_reactor_count); // 创建MainRector进程
while (true) sleep(1); // 主进程陷入死循环
return 0;
}在main函数中,先在unix socket上开启监听,每个SubReactor进程通过epoll监听各自的unix socket上的事件。每个MainReactor进程则会连接上每个SubReactor进程监听的unix socket,并通过这些unix socket以轮询的方式,给不同的SubReactor进程传递客户端连接。
(7) EpollReactorProcessPoolCoroutine
Reactor-单进程协程池的并发模型存在进程池的版本。相关的代码如下:
#include <arpa/inet.h>
#include <assert.h>
#include <fcntl.h>
#include <netinet/in.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include <sys/socket.h>
#include <unistd.h>
#include <iostream>
#include "../../common/cmdline.h"
#include "../../common/coroutine.h"
#include "../../common/epollctl.hpp"
using namespace std;
using namespace MyEcho;
struct EventData {
EventData(int fd, int epoll_fd) : fd_(fd), epoll_fd_(epoll_fd){};
int fd_{0};
int epoll_fd_{0};
int cid_{MyCoroutine::kInvalidRoutineId};
MyCoroutine::Schedule *schedule_{nullptr};
};
void EchoDeal(const std::string req_message, std::string &resp_message) { resp_message = req_message; }
void handlerClient(EventData *event_data) {
auto releaseConn = [&event_data]() {
ClearEvent(event_data->epoll_fd_, event_data->fd_);
delete event_data; // 释放内存
};
while (true) {
ssize_t ret = 0;
Codec codec;
string *req_message{nullptr};
string resp_message;
while (true) { // 读操作
ret = read(event_data->fd_, codec.Data(), codec.Len()); // 一次最多读取100字节
if (ret == 0) {
perror("peer close connection");
releaseConn();
return;
}
if (ret < 0) {
if (EINTR == errno) continue; // 被中断,可以重启读操作
if (EAGAIN == errno or EWOULDBLOCK == errno) {
MyCoroutine::CoroutineYield(*event_data->schedule_); // 让出cpu,切换到主协程,等待下一次数据可读
continue;
}
perror("read failed");
releaseConn();
return;
}
codec.DeCode(ret); // 解析请求数据
req_message = codec.GetMessage();
if (req_message) { // 解析出一个完整的请求
break;
}
}
// 执行到这里说明已经读取到一个完整的请求
EchoDeal(*req_message, resp_message); // 业务handler的封装,这样协程的调用就对业务逻辑函数EchoDeal透明
delete req_message;
Packet pkt;
codec.EnCode(resp_message, pkt);
ModToWriteEvent(event_data->epoll_fd_, event_data->fd_, event_data); // 监听可写事件。
size_t sendLen = 0;
while (sendLen != pkt.UseLen()) { // 写操作
ret = write(event_data->fd_, pkt.Data() + sendLen, pkt.UseLen() - sendLen);
if (ret < 0) {
if (EINTR == errno) continue; // 被中断,可以重启写操作
if (EAGAIN == errno or EWOULDBLOCK == errno) {
MyCoroutine::CoroutineYield(*event_data->schedule_); // 让出cpu,切换到主协程,等待下一次数据可写
continue;
}
perror("write failed");
releaseConn();
return;
}
sendLen += ret;
}
ModToReadEvent(event_data->epoll_fd_, event_data->fd_, event_data); // 监听可读事件。
}
}
int handler(string ip, int64_t port) {
int sock_fd = CreateListenSocket(ip, port, true);
if (sock_fd < 0) {
return -1;
}
epoll_event events[2048];
int epoll_fd = epoll_create(1);
if (epoll_fd < 0) {
perror("epoll_create failed");
return -1;
}
EventData event_data(sock_fd, epoll_fd);
SetNotBlock(sock_fd);
AddReadEvent(epoll_fd, sock_fd, &event_data);
MyCoroutine::Schedule schedule;
MyCoroutine::ScheduleInit(schedule, 5000); // 协程池初始化
int msec = -1;
while (true) {
int num = epoll_wait(epoll_fd, events, 2048, msec);
if (num < 0) {
perror("epoll_wait failed");
continue;
} else if (num == 0) { // 没有事件了,下次调用epoll_wait大概率被挂起
sleep(0); // 这里直接sleep(0)让出cpu,大概率被挂起,这里主动让出cpu,可以减少一次epoll_wait的调用
msec = -1; // 大概率被挂起,故这里超时时间设置为-1
continue;
}
msec = 0; // 下次大概率还有事件,故msec设置为0
for (int i = 0; i < num; i++) {
EventData *event_data = (EventData *)events[i].data.ptr;
if (event_data->fd_ == sock_fd) {
LoopAccept(sock_fd, 2048, [epoll_fd](int client_fd) {
EventData *event_data = new EventData(client_fd, epoll_fd);
SetNotBlock(client_fd);
AddReadEvent(epoll_fd, client_fd, event_data); // 监听可读事件
});
continue;
}
if (event_data->cid_ == MyCoroutine::kInvalidRoutineId) { // 第一次事件,则创建协程
event_data->schedule_ = &schedule;
event_data->cid_ = MyCoroutine::CoroutineCreate(schedule, handlerClient, event_data); // 创建协程
MyCoroutine::CoroutineResumeById(schedule, event_data->cid_);
} else {
MyCoroutine::CoroutineResumeById(schedule, event_data->cid_); // 唤醒之前主动让出cpu的协程
}
}
}
return 0;
}
void usage() {
cout << "EpollReactorProcessPoolCoroutine -ip 0.0.0.0 -port 1688 -poolsize 8" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << " -poolsize,--poolsize pool size" << endl;
cout << endl;
}
int main(int argc, char *argv[]) {
string ip;
int64_t port;
int64_t pool_size;
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::Int64OptRequired(&pool_size, "poolsize");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
pool_size = pool_size > GetNProcs() ? GetNProcs() : pool_size;
for (int i = 0; i < pool_size; i++) {
pid_t pid = fork();
assert(pid != -1);
if (0 == pid) {
handler(ip, port); // 子进程陷入死循环,处理客户端请求
exit(0);
}
}
while (true) sleep(1); // 父进程陷入死循环
return 0;
}在main函数中,创建了多个子进程,每个子进程都运行着一个Reactor-协程池的并发模型。
(8) EpollReactorThreadPool
Reactor的并发模型,存在着线程池的版本。相关的代码如下:
#include <arpa/inet.h>
#include <assert.h>
#include <fcntl.h>
#include <netinet/in.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include <sys/socket.h>
#include <unistd.h>
#include <iostream>
#include <thread>
#include "../../common/cmdline.h"
#include "../../common/conn.hpp"
#include "../../common/epollctl.hpp"
using namespace std;
using namespace MyEcho;
void handler(string ip, int64_t port) {
int sock_fd = CreateListenSocket(ip, port, true);
if (sock_fd < 0) {
return;
}
epoll_event events[2048];
int epoll_fd = epoll_create(1);
if (epoll_fd < 0) {
perror("epoll_create failed");
return;
}
Conn conn(sock_fd, epoll_fd, true);
SetNotBlock(sock_fd);
AddReadEvent(&conn);
while (true) {
int num = epoll_wait(epoll_fd, events, 2048, -1);
if (num < 0) {
perror("epoll_wait failed");
continue;
}
for (int i = 0; i < num; i++) {
Conn *conn = (Conn *)events[i].data.ptr;
if (conn->Fd() == sock_fd) {
LoopAccept(sock_fd, 2048, [epoll_fd](int client_fd) {
Conn *conn = new Conn(client_fd, epoll_fd, true);
SetNotBlock(client_fd);
AddReadEvent(conn); // 监听可读事件
});
continue;
}
auto releaseConn = [&conn]() {
ClearEvent(conn);
delete conn;
};
if (events[i].events & EPOLLIN) { // 可读
if (not conn->Read()) { // 执行读失败
releaseConn();
continue;
}
if (conn->OneMessage()) { // 判断是否要触发写事件
conn->EnCode();
ModToWriteEvent(conn); // 修改成只监控可写事件
}
}
if (events[i].events & EPOLLOUT) { // 可写
if (not conn->Write()) { // 执行写失败
releaseConn();
continue;
}
if (conn->FinishWrite()) { // 完成了请求的应答写,则可以释放连接
conn->Reset();
ModToReadEvent(conn); // 修改成只监控可读事件
}
}
}
}
}
void usage() {
cout << "EpollReactorThreadPool -ip 0.0.0.0 -port 1688 -poolsize 8" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << " -poolsize,--poolsize pool size" << endl;
cout << endl;
}
int main(int argc, char *argv[]) {
string ip;
int64_t port;
int64_t pool_size;
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::Int64OptRequired(&pool_size, "poolsize");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
pool_size = pool_size > GetNProcs() ? GetNProcs() : pool_size;
for (int i = 0; i < pool_size; i++) {
std::thread(handler, ip, port).detach(); // 这里需要调用detach,让创建的线程独立运行
}
while (true) sleep(1); // 主线程陷入死循环
return 0;
}在main函数中,创建了多个子进程,每个线程都运行着一个Reactor的并发模型。
(9) EpollReactorThreadPoolHSHA
Reactor并发模型除了存在Reactor-MS的变种之外,还存在Reactor-HSHA的变种。我们实现的Reactor-HSHA模型简图如下图所示。

我们使用了线程池的方式来实现Reactor-HSHA的模型,相关的代码如下:
#include <arpa/inet.h>
#include <fcntl.h>
#include <netinet/in.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include <sys/socket.h>
#include <unistd.h>
#include <condition_variable>
#include <iostream>
#include <mutex>
#include <queue>
#include <thread>
#include "../../common/cmdline.h"
#include "../../common/conn.hpp"
#include "../../common/epollctl.hpp"
using namespace std;
using namespace MyEcho;
std::mutex Mutex;
std::condition_variable Cond;
std::queue<Conn *> Queue;
void pushInQueue(Conn *conn) {
{
std::unique_lock<std::mutex> locker(Mutex);
Queue.push(conn);
}
Cond.notify_one();
}
Conn *getQueueData() {
std::unique_lock<std::mutex> locker(Mutex);
Cond.wait(locker, []() -> bool { return Queue.size() > 0; });
Conn *conn = Queue.front();
Queue.pop();
return conn;
}
void workerHandler(bool is_direct) {
while (true) {
Conn *conn = getQueueData();
conn->EnCode();
if (is_direct) { // 直接把数据发送给客户端,而不是通过I/O线程来发送
bool success = true;
while (not conn->FinishWrite()) {
if (not conn->Write()) {
success = false;
break;
}
}
if (not success) {
ClearEvent(conn);
delete conn;
} else {
conn->Reset();
ReStartReadEvent(conn); // 修改成只监控可读事件,携带oneshot选项
}
} else {
ModToWriteEvent(conn); // 监听写事件,数据通过I/O线程来发送
}
}
}
void ioHandler(string ip, int64_t port) {
int sock_fd = CreateListenSocket(ip, port, true);
if (sock_fd < 0) {
return;
}
epoll_event events[2048];
int epoll_fd = epoll_create(1);
if (epoll_fd < 0) {
perror("epoll_create failed");
return;
}
Conn conn(sock_fd, epoll_fd, true);
SetNotBlock(sock_fd);
AddReadEvent(&conn);
int msec = -1;
while (true) {
int num = epoll_wait(epoll_fd, events, 2048, msec);
if (num < 0) {
perror("epoll_wait failed");
continue;
}
for (int i = 0; i < num; i++) {
Conn *conn = (Conn *)events[i].data.ptr;
if (conn->Fd() == sock_fd) {
LoopAccept(sock_fd, 2048, [epoll_fd](int client_fd) {
Conn *conn = new Conn(client_fd, epoll_fd, true);
SetNotBlock(client_fd);
AddReadEvent(conn, false, true); // 监听可读事件,开启oneshot
});
continue;
}
auto releaseConn = [&conn]() {
ClearEvent(conn);
delete conn;
};
if (events[i].events & EPOLLIN) { // 可读
if (not conn->Read()) { // 执行非阻塞read
releaseConn();
continue;
}
if (conn->OneMessage()) {
pushInQueue(conn); // 入共享输入队列,有锁
} else {
ReStartReadEvent(conn); // 还没收到完整的请求,则重新启动可读事件的监听,携带oneshot选项
}
}
if (events[i].events & EPOLLOUT) { // 可写
if (not conn->Write()) { // 执行非阻塞write
releaseConn();
continue;
}
if (conn->FinishWrite()) { // 完成了请求的应答写,则可以释放连接close
conn->Reset();
ReStartReadEvent(conn); // 修改成只监控可读事件,携带oneshot选项
}
}
}
}
}
void usage() {
cout << "EpollReactorThreadPoolHSHA -ip 0.0.0.0 -port 1688 -io 3 -worker 8 -direct" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << " -io,--io io thread count" << endl;
cout << " -worker,--worker worker thread count" << endl;
cout << " -direct,--direct direct send response data by worker thread" << endl;
cout << endl;
}
int main(int argc, char *argv[]) {
string ip;
int64_t port;
int64_t io_count;
int64_t worker_count;
bool is_direct;
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::Int64OptRequired(&io_count, "io");
CmdLine::Int64OptRequired(&worker_count, "worker");
CmdLine::BoolOpt(&is_direct, "direct");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
cout << "is_direct=" << is_direct << endl;
io_count = io_count > GetNProcs() ? GetNProcs() : io_count;
worker_count = worker_count > GetNProcs() ? GetNProcs() : worker_count;
for (int i = 0; i < worker_count; i++) { // 创建worker线程
std::thread(workerHandler, is_direct).detach(); // 这里需要调用detach,让创建的线程独立运行
}
for (int i = 0; i < io_count; i++) { // 创建io线程
std::thread(ioHandler, ip, port).detach(); // 这里需要调用detach,让创建的线程独立运行
}
while (true) sleep(1); // 主线程陷入死循环
return 0;
}在main函数中,先后创建了woker线程和io线程,io线程和worker线程通过内存队列加条件变量来通讯。
(10) EpollReactorThreadPoolMS
这个是最后一个模型,采用线程池的方式来实现Reactor-MS模型,相关的代码如下所示:
#include <arpa/inet.h>
#include <assert.h>
#include <fcntl.h>
#include <netinet/in.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include <sys/socket.h>
#include <unistd.h>
#include <iostream>
#include <thread>
#include "../../common/cmdline.h"
#include "../../common/conn.hpp"
#include "../../common/epollctl.hpp"
using namespace std;
using namespace MyEcho;
int *EpollFd;
int createEpoll() {
int epoll_fd = epoll_create(1);
assert(epoll_fd > 0);
return epoll_fd;
}
void addToSubReactor(int &index, int sub_reactor_count, int client_fd) {
index++;
index %= sub_reactor_count;
// 轮询的方式添加到subReactor线程中
Conn *conn = new Conn(client_fd, EpollFd[index], true);
AddReadEvent(conn); // 监听可读事件
}
void mainReactor(string ip, int64_t port, int64_t sub_reactor_count, bool is_main_read) {
int sock_fd = CreateListenSocket(ip, port, true);
if (sock_fd < 0) {
return;
}
epoll_event events[2048];
int epoll_fd = epoll_create(1);
if (epoll_fd < 0) {
perror("epoll_create failed");
return;
}
int index = 0;
Conn conn(sock_fd, epoll_fd, true);
SetNotBlock(sock_fd);
AddReadEvent(&conn);
while (true) {
int num = epoll_wait(epoll_fd, events, 2048, -1);
if (num < 0) {
perror("epoll_wait failed");
continue;
}
for (int i = 0; i < num; i++) {
Conn *conn = (Conn *)events[i].data.ptr;
if (conn->Fd() == sock_fd) { // 有客户端的连接到来了
LoopAccept(sock_fd, 2048, [&index, is_main_read, epoll_fd, sub_reactor_count](int client_fd) {
SetNotBlock(client_fd);
if (is_main_read) {
Conn *conn = new Conn(client_fd, epoll_fd, true);
AddReadEvent(conn); // 在mainReactor线程中监听可读事件
} else {
addToSubReactor(index, sub_reactor_count, client_fd);
}
});
continue;
}
// 客户端有数据可读,则把连接迁移到subReactor线程中管理
ClearEvent(conn, false);
addToSubReactor(index, sub_reactor_count, conn->Fd());
delete conn;
}
}
}
void subReactor(int thread_id) {
epoll_event events[2048];
int epoll_fd = EpollFd[thread_id];
while (true) {
int num = epoll_wait(epoll_fd, events, 2048, -1);
if (num < 0) {
perror("epoll_wait failed");
continue;
}
for (int i = 0; i < num; i++) {
Conn *conn = (Conn *)events[i].data.ptr;
auto releaseConn = [&conn]() {
ClearEvent(conn);
delete conn;
};
if (events[i].events & EPOLLIN) { // 可读
if (not conn->Read()) { // 执行非阻塞读
releaseConn();
continue;
}
if (conn->OneMessage()) { // 判断是否要触发写事件
conn->EnCode();
ModToWriteEvent(conn); // 修改成只监控可写事件
}
}
if (events[i].events & EPOLLOUT) { // 可写
if (not conn->Write()) { // 执行非阻塞写
releaseConn();
continue;
}
if (conn->FinishWrite()) { // 完成了请求的应答写,则可以释放连接
conn->Reset();
ModToReadEvent(conn); // 修改成只监控可读事件
}
}
}
}
}
void usage() {
cout << "EpollReactorThreadPoolMS -ip 0.0.0.0 -port 1688 -main 3 -sub 8 -mainread" << endl;
cout << "options:" << endl;
cout << " -h,--help print usage" << endl;
cout << " -ip,--ip listen ip" << endl;
cout << " -port,--port listen port" << endl;
cout << " -main,--main mainReactor count" << endl;
cout << " -sub,--sub subReactor count" << endl;
cout << " -mainread,--mainread mainReactor read" << endl;
cout << endl;
}
int main(int argc, char *argv[]) {
string ip;
int64_t port;
int64_t main_reactor_count;
int64_t sub_reactor_count;
bool is_main_read;
CmdLine::StrOptRequired(&ip, "ip");
CmdLine::Int64OptRequired(&port, "port");
CmdLine::Int64OptRequired(&main_reactor_count, "main");
CmdLine::Int64OptRequired(&sub_reactor_count, "sub");
CmdLine::BoolOpt(&is_main_read, "mainread");
CmdLine::SetUsage(usage);
CmdLine::Parse(argc, argv);
cout << "is_main_read=" << is_main_read << endl;
main_reactor_count = main_reactor_count > GetNProcs() ? GetNProcs() : main_reactor_count;
sub_reactor_count = sub_reactor_count > GetNProcs() ? GetNProcs() : sub_reactor_count;
EpollFd = new int[sub_reactor_count];
for (int i = 0; i < sub_reactor_count; i++) {
EpollFd[i] = createEpoll();
std::thread(subReactor, i).detach(); // 这里需要调用detach,让创建的线程独立运行
}
for (int i = 0; i < main_reactor_count; i++) {
std::thread(mainReactor, ip, port, sub_reactor_count, is_main_read)
.detach(); // 这里需要调用detach,让创建的线程独立运行
}
while (true) sleep(1); // 主线程陷入死循环
return 0;
}在main函数中,先后创建了SubReactor线程和MainReactor线程,SubReactor线程和MainReactor线程直接通过epoll的文件描述符来传递客户端连接的文件描述符。
(11) 性能压测与对比
压测运行环境:云开发机,16核32G的CentOS主机,每个CPU的频率为2.59GHz。(被压测的服务和压测工具都运行在同一台云主机上)。
① IO复用模型对比
第一轮压测命令:BenchMark -ip 0.0.0.0 -port 1688 -thread_count 1 -max_req_count 40 -pkt_size 256 -client_count 2000 -run_time 30 -rate_limit 200000
压测后的性能指标如下表所示:

从上表的数据中,我们可以看出,select函数的性能明显是没有poll函数和epoll函数性能好的,在客户端连接数不多的情况下epoll并没有明显的优势。
第二轮压测命令:BenchMark -ip 0.0.0.0 -port 1688 -thread_count 4 -max_req_count 1000000 -pkt_size 512 -client_count 8000 -run_time 30 -rate_limit 200000。
压测后的性能指标如下表所示:

从上表的数据中,我们可以看出,在大量客户端连接的情况下,poll函数的性能是明显不如epoll函数的。
② EPOLL下LT模式、ET模型和协程池对比
压测命令:BenchMark -ip 0.0.0.0 -port 1688 -thread_count 4 -max_req_count 1000000 -pkt_size 4096 -client_count 250 -run_time 30 -rate_limit 200000
压测后的性能指标如下表所示:
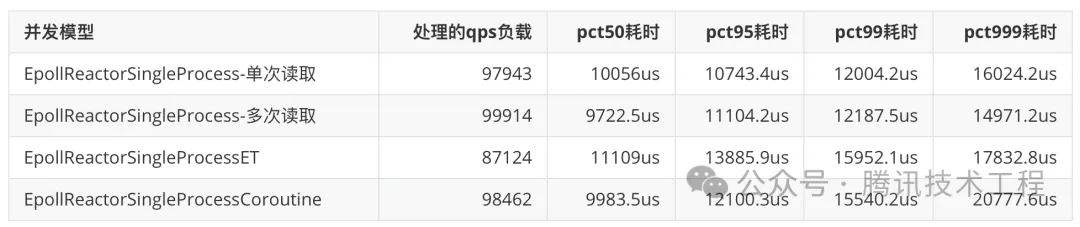
从上表的数据中,我们可以看出,ET模式下的epoll并不比LT模式下的epoll性能高,协程池的并发模型性能和其他的三个并发模型性能差异不大,协程池的并发模型因为多了协程的切换,导致接口耗时会更大。
③ EPOLL下直接写和直接切换写监听对比
压测命令:BenchMark -ip 0.0.0.0 -port 1688 -thread_count 4 -max_req_count 1000000 -pkt_size 512 -client_count 250 -run_time 60 -rate_limit 200000
压测后的性能指标如下表所示:

从上表的数据中,我们可以看出,直接写的方式,比直接切换写监听的性能要高出4%左右,这是因为通常客户端连接大概率的可写的,不用再额外的先切换到写的监听。
④ HSHA模式下worker线程和io线程写应答对比
EpollReactorThreadPoolHSHA使用1个io线程和1个worker线程来运行。
压测命令:BenchMark -ip 0.0.0.0 -port 1688 -thread_count 4 -max_req_count 1000000 -pkt_size 4096 -client_count 250 -run_time 30 -rate_limit 200000
压测后的性能指标如下表所示:

从上表的数据中,我们可以看出,worker线程写,比io线程写的性能要高出25%左右,这也是因为通常客户端连接大概率的可写的,不用再额外的先切换到写的监听。
⑤ MS模式下MainReactor线程是否监听可读事件对比
EpollReactorThreadPoolMS使用1个MainReactor线程和1个SubReactor线程来运行。
- 长连接压测命令:BenchMark -ip 0.0.0.0 -port 1688 -thread_count 4 -max_req_count 1000000 -pkt_size 4096 -client_count 250 -run_time 30 -rate_limit 200000
- 短连接压测命令:BenchMark -ip 0.0.0.0 -port 1688 -thread_count 4 -max_req_count 1 -pkt_size 4096 -client_count 250 -run_time 30 -rate_limit 200000
压测后的性能指标如下表所示:

从上表的数据中,我们可以看出,不在MainReactor线程中监听可读事件性能只是提升了一点点,且不管是在长连接还是短连接的场景下都是如此。
⑥ EPOLL下动态和固定超时时间对比
EpollReactorSingleProcessCoroutine两种不同模式(是否使用动态超时时间)进行了压测。
压测命令: BenchMark -ip 0.0.0.0 -port 1688 -thread_count 4 -max_req_count 1000000 -pkt_size 4096 -client_count 1000 -run_time 60 -rate_limit 200000

从上表的数据中,我们可以看出,在有大量事件时(我们的压测命令可以同时构造最多4000个事件,程序每次最多出来2048个事件),动态超时机制能提升14%的性能。
⑦ EPOLL下进程池或者线程池对比
- 长连接压测命令:BenchMark -ip 0.0.0.0 -port 1688 -thread_count 4 -max_req_count 1000000 -pkt_size 512 -client_count 500 -run_time 60 -rate_limit 1000000
- 短连接压测命令:BenchMark -ip 0.0.0.0 -port 1688 -thread_count 4 -max_req_count 1 -pkt_size 512 -client_count 500 -run_time 60 -rate_limit 1000000

在长连接的场景下,EpollReactorProcessPoolMS的性能是最高的,因为EpollReactorProcessPoolMS模型中是没有锁的且负载更为均衡,其次EpollReactorThreadPool的性能是第二高,EpollReactorThreadPool模型同样是没有锁的,EpollReactorProcessPoolCoroutine模型虽然也没有锁操作,但是有协程上下文切换的成本,所以性能也只是位居第三。
在短连接的场景下,进程池的模型性能总体好于线程池的模型。