












这几天,在巴黎举办的最大科技活动VivaTech上,OpenAI再次带来了许多惊喜。
从展示的模型智能进化路线图中,可以确定的是,今年OpenAI一定会发布新一代旗舰模型。
而且,大概率不会以GPT-5命名,演示中将其称之为「GPT Next」。

那么,OpenAI究竟会在2024年哪个月发布,爆料人Flowers掐指一算——可能在11月。

以GPT-3和GPT-4的发布时间等轴划分
这是OpenAI开发者体验负责人Romain Huet在长达38分钟的演讲中,向外界传达的一个重要的信息。

演讲现场,Huet主要讲了三件事:
- OpenAI是如何走到今天的
- 旗舰模型GPT-4o
- OpenAI的下一步和前景

若说整场演讲中,最令人印象深刻的,依旧还是GPT-4o。
Huet现场用ChatGPT Mac版程序,让GPT-4o向在场的400多位观众打招呼。
甚至还要求让它用法语,更热情地问好,通过呈现不同的语音语调,展现出GPT-4o强大的语音能力。
即便在打招呼过程中,Huet也可以随时打断对话,与人类真正交流互动的方式几乎无异。
另外,Huet还让GPT-4o实时将英语翻译成法语,引得台下公众一阵鼓掌欢呼。

更让人惊掉下巴的是,Huet打开摄像头,向GPT-4o展示了一张凯旋门和巴黎铁塔的草图,它准确识别出巴黎的标志性地标。

接下来,他又向其展示了一张地图,并询问如何从凡尔赛门导航到草图中的地方。

没想到,ChatGPT不假思索地提供了详细的火车路线,而且包括换乘和停靠站的具体信息。
,时长01:23
有网友表示,「他们30分钟的演示直接扼杀了数十家初创公司」。

除此以外,Romain Huet的精彩演讲,还有哪些亮点?
「全能」GPT-4o惊艳全场
先来看看最新的第二趴,Huet主要强调了旗舰模型GPT-4o的三个重点。
首先它是「多模态」的,几乎没有延迟,堪称为一个真正的「全能模型」(omni model)。

其次,在大模型竞技场中,经过盲测后的GPT-4o,取得了最新的SOTA。

最后,GPT-4o的API价格还是GPT-4 Turbo的一半,而速率大大提升的2倍。

接下来,Huet显示做了一个文章开篇介绍的GPT-4o演示。
作为ChatGPT的基操,读代码、debug这个环节也是必不可少的。Huet本人也做了现场直播演示,让GPT-4o加持的ChatGPT Mac版去修复bug。
他将一段复制给ChatGPT,然后先让其首先简单地描述下代码的内容:
代码是一个名为Discover的React组件,它渲染一个Discover卡片组件网格,每个卡片的数据从trips.json文件中获取。

然后,Huet将自己的屏幕分享给ChatGPT,并询问能否让这个页面更具响应性。

接下来,就是ChatGPT放大招的时候了。
你可以使用Tailwind CSS的响应式设计功能,根据屏幕大小调整网格中的列数。这是修改网格布局的快速方法。Div的颜色和布局方案,设置网格列数为1,从0到4列。
不过,Huet表示,其实我就是在使用Tailwind去处理,继续问道,「那么你能告诉我属性是什么吗」?
ChatGPT答道,「对于Tailwind,你可以调整网格响应列,以使网格响应」。
以下是设置方法:网格列数将根据当前屏幕大小进行控制。所以你不需要太多列来填充网格,这是大多数响应设计的经验法则。默认情况下设置1列,小屏幕设置2列.
Huet表示,「我明白了。所以我应该在小屏幕上设置一列,对吗?然后随着屏幕变大,增加列数」?

ChatGPT确认道,「没错。你可以根据不同的屏幕尺寸调整列数。例如,默认情况下设置一列,sm:-grid-cols-2设置小屏幕及更大屏幕为两列,md:-grid-cols-3设置中等屏幕及更大屏幕为三列,等等」。
最后,Huet按着ChatGPT要求修改过后,再让其看看是否正确。
ChatGPT给出了回答,「完美」!
这些演示,向所有人展示了GPT-4o相较于以往模型,展现出的强大能力,能够在编码问题上实时查看屏幕,帮你解决问题。
而且,GPT-4o生成文本的速度,完全碾压了GPT-4 Turbo。

ChatGPT为Sora视频配音,梦幻联动
见识过GPT-4o的厉害之后,Huet还现场演示了一段ChatGPT和Sora梦幻联动的例子。
首先是准备工作——输入Prompt,坐等Sora把视频生成出来,再配上背景音,一段「巴黎之旅」的视频就做好了。
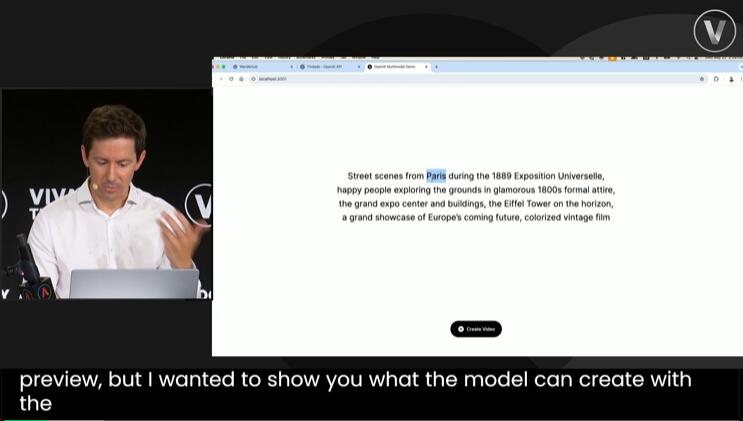
接下来,再让ChatGPT根据视频中的关键帧,生成一段介绍。
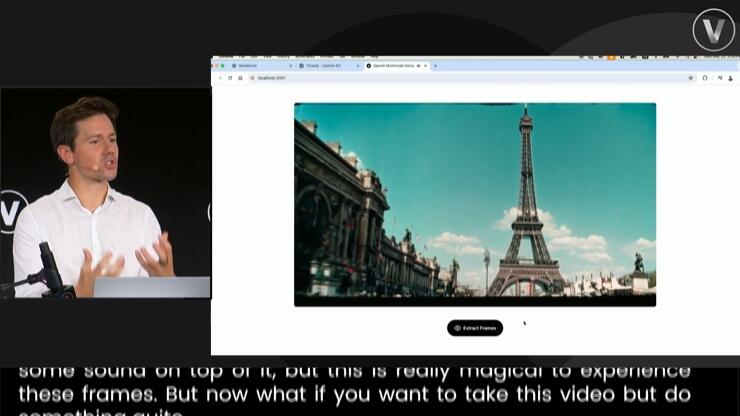
其中,给到模型的系统提示是这样的:
你是位历史教授。你将看到一系列连续的图片,它们是一部历史纪录片的一部分。你的任务是用一种引人入胜且富有信息性的方式描述画面中的场景。
请为一位语速适中的解说员编写一份脚本,讲述时间不应超过45秒。
请将脚本分为2-4个小段落。不要添加任何前缀或描述,仅包括要讲述的文字。

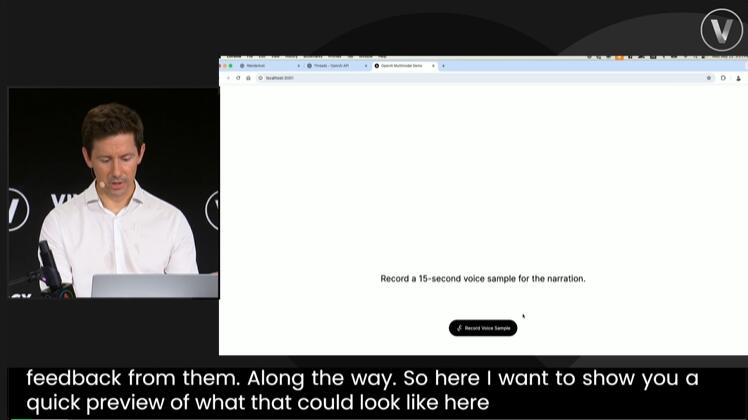
如果想让视频更加生动,则可以进一步利用OpenAI的「Voice Engine」模型(语音引擎)把之前的文字介绍变成真人配音。
接下来,首先需要向ChatGPT发送了一段录制好的语音片段。
我非常高兴自己站在VivaTech的舞台上,并见到了一些非常棒的创始人和开发者。我很期待向他们展示一些现场demo,以及如何真正地将OpenAI的技术和模型应用到他们自己的产品和业务中。
然后ChatGPT基于Huet的语音内容,然后为Sora预先生成的一段巴黎历史介绍视频,进行了「原声」配音。
这时,不仅可以用音频源语言,还可以选择法语、西班牙语、日语等多种语言,而且音色保持不变。
配好音的视频,可以针对目标语群体进行分享,而且,还能为其配上字幕。
网友称,「OpenAI这个案例向我们展示了,将Sora视频发送给ChatGPT获取脚本,并利用「语音引擎」为其配音,最后将所有模态内容整合到一起」。

押注GPT大模型,多模态智能体是重点
接下来,OpenAI下一步大动作会是什么?
Huet称我们未来将大力投资这四个领域。

首先是文本智能。
目前,GPT-4、GPT-4o虽是全球最优秀的模型,但它们更像是一到二年级的学生,时不时会犯错误。
「我认为,也许一两年后,这些模型将无法与今天的样子辨认」。
Huet继续称,今年OpenAI将计划在下一代模型上更好地推动这一界限,并提供像逐步函数一样的推理改进。
也就是,如下这张传遍全网的路线图。

第二,OpenAI要确保模型始终更便宜、更快。
因为,在OpenAI看来,并非每个用例都需要最高水平的智能。

与此同时,OpenAI还希望确保当开发者想要扩展时,能够提供不同的模型来满足所有的需求。
在一些真实的工作流中,部分子流程,可能需要更小参数规模的模型,或者对延迟更敏感的模型。

第二个投资领域的最后一部分,OpenAI也是希望能够帮助开发者,运行异步工作负载。
比如,几周前,推出的批处理API。这是一种非常便捷的方式,可以将你的所有请求批量发送到OpenAI。
这意味着,对于不需要立即响应的任务,还将能够再享受50%的折扣。

第三,OpenAI还将投资自定义模型。
在未来,不同的组织可能有不同的工作方式,更需要一个可以深入了解自身业务的模型。因此,OpenAI未来将会提供一系列微调的产品,包括简单微调API、提供团队帮助,以及让OpenAI为其训练模型。

这里,Huet举了两个和OpenAI合作的公司,Harvey和SK telecom。

而对于第四个OpenAI投资的领域,那便是「多模态智能体」。
「我非常确信,在未来,智能体可能是软件,以及我们与计算机交互方式发生的最大变化」。

现场,Huet还引用了美国著名程序员Paul Graham曾说过的话。
通常,28岁的程序员比22岁的程序员更具生产力,因为他们拥有更多的经验。但显然,22岁的程序员现在和28岁的程序员一样优秀,因为他们使用Al时更得心应手。

Huet通过举例Devin在实际中帮助开发者解决代码问题,以及其他案例,去说明智能体真的是当今重要的应用之一。

用例翻倍,GPT-4开创无限可能
演讲开篇,Huet主要回顾了OpenAI至今已取得的成就。
一开始,他再次重申了,「我们是一家研究型公司,OpenAI的使命是打造有益于全人类的AGI」。

而目前,全球已经有超300万开发者使用OpenAI API正创造一些有趣的事情。

92%的财富500强让ChatGPT加入工作流,而还有1亿的活跃用户,开发者们已经打造了300万GPTs。
总之,OpenAI在AI采用率上,是全球领先的。

ChatGPT发布之初是静默的,却没想到,给世界带来了翻天覆地的变化
其实,ChatGPT之前,OpenAI早在2020年打造了GPT-3模型,并为开发者提供了尝试利用LLM去构建应用的体验。
可以看到,GPT-3的用例已经非常广泛,包括编程助手、代码审查、搜索和信息检索、内容创造等等。
下图中右边展示的是,Huet的个人用例——角色扮演游戏。

直到2023年GPT-4诞生,开创了一个全新的纪元。
新模型可以开创尽可能多的无限想象,从GPT-3的8个用例到GPT-4的13个用例,几乎实现了翻倍增长。
它不仅推理能力得到了大幅提升,还可以像人类一样,利用「工具」完成多项任务。
如今,这些能力已经得到许多公司的采用,比如下图中右侧Spotify为用户创建的独特的清晨播放列表。

OpenAI在上周推出的GPT-4o,就像一个魔法层,给GPT-4用例加满buff。
得益于实时跨音频、文本、视觉的能力,GPT-4o能够让我们以前所未有的方式进行交互。

站在OpenAI巨人的肩膀上,众多初创公司已经在客户服务、知识助手、语音服务、内容生成、智能体领域挖掘出的应用,遍地开花。

演讲最后,Huet表示,我们的目标不是让你在OpenAI身上花更多的钱,而是用OpenAI建造更多。



























