kube-proxy是任何 Kubernetes 部署中的关键组件。它的作用是将流向服务(通过集群 IP 和节点端口)的流量负载均衡到正确的后端pod。kube-proxy可以运行在三种模式之一,每种模式都使用不同的数据平面技术来实现:userspace、iptables 或 IPVS。
userspace 模式非常旧且慢,绝对不推荐!但是,应该如何权衡选择 iptables 还是 IPVS 模式呢?在本文中,我们将比较这两种模式,在实际的微服务环境中衡量它们的性能,并解释在何种情况下你可能会选择其中一种。
首先,我们将简要介绍这两种模式的背景,然后深入测试和结果……

背景:iptables 代理模式
iptables 是一个 Linux 内核功能,旨在成为一个高效的防火墙,具有足够的灵活性来处理各种常见的数据包操作和过滤需求。它允许将灵活的规则序列附加到内核数据包处理管道中的各个钩子上。在 iptables 模式下,kube-proxy将规则附加到 “NAT pre-routing” 钩子上,以实现其 NAT 和负载均衡功能。这种方式可行,简单,使用成熟的内核功能,并且与其他使用 iptables 进行过滤的程序(例如 Calico)能够很好地兼容。
然而,kube-proxy 编程 iptables 规则的方式意味着它名义上是一个 O(n) 风格的算法,其中 n 大致与集群规模成正比(更准确地说,是与服务的数量和每个服务背后的后端 pod 数量成正比)。
背景:IPVS 代理模式
IPVS 是一个专门为负载均衡设计的 Linux 内核功能。在 IPVS 模式下,kube-proxy通过编程 IPVS 负载均衡器来代替使用 iptables。它同样使用成熟的内核功能,且 IPVS 专为负载均衡大量服务而设计;它拥有优化的 API 和查找例程,而不是一系列顺序规则。
结果是,在 IPVS 模式下,kube-proxy 的连接处理具有名义上的 O(1) 计算复杂度。换句话说,在大多数情况下,它的连接处理性能将保持恒定,而不受集群规模的影响。
此外,作为一个专用的负载均衡器,IPVS 拥有多种不同的调度算法,如轮询、最短期望延迟、最少连接数和各种哈希方法。相比之下,iptables 中的 kube-proxy 使用的是随机的等成本选择算法。
IPVS 的一个潜在缺点是,通过 IPVS 处理的数据包在 iptables 过滤钩子中的路径与正常情况下的数据包非常不同。如果计划将 IPVS 与其他使用 iptables 的程序一起使用,则需要研究它们是否能够预期地协同工作。(别担心,Calico 早在很久以前就已经与 IPVS kube-proxy 兼容了!)
性能比较
好的,从名义上来说,kube-proxy在 iptables 模式下的连接处理是 O(n) 复杂度,而在 IPVS 模式下是 O(1) 复杂度。但在实际微服务环境中,这意味着什么呢?
在大多数情况下,涉及应用程序和微服务时,kube-proxy性能有两个关键属性可能是您关心的:
- 对往返响应时间的影响:当一个微服务向另一个微服务发出 API 调用时,平均而言第一个微服务发送请求并从第二个微服务接收响应需要多长时间?
- 对总 CPU 使用率的影响:在运行微服务时,包括用户空间和内核/系统使用在内的主机总 CPU 使用率是多少?这包括了支持微服务所需的所有进程,包括 kube-proxy。
为了说明这一点,我们在一个专用节点上运行了一个clinet微服务pod,每秒生成 1000 个请求,发送到由 10 个service微服务pod支持的 Kubernetes 服务。然后,我们在iptables和IPVS模式下,在客户端节点上测量了性能,使用了各种数量的 Kubernetes 服务,每个服务有10个pod支持,最多达到 10,000 个服务(即 100,000 个服务后端)。对于微服务,我们使用golang编写的简单测试工具作为我们的客户端微服务,并使用标准NGINX作为服务器微服务的后端pods。
往返响应时间
在考虑往返响应时间时,理解连接和请求之间的区别非常重要。通常,大多数微服务将使用持久连接或“keepalive”连接,这意味着每个连接会在多个请求之间重复使用,而不是每个请求都需要新建一个连接。这一点很重要,因为大多数新连接都需要在网络上进行三次握手(这需要时间),并且在 Linux 网络栈内进行更多处理(这也需要一点时间和 CPU 资源)。
为了说明这些差异,我们在有和没有 keepalive 连接的情况下进行了测试。对于 keepalive 连接,我们使用了 NGINX 的默认配置,该配置会将每个连接保持活跃状态以供最多 100 个请求重复使用。请参见下图,注意响应时间越低越好。
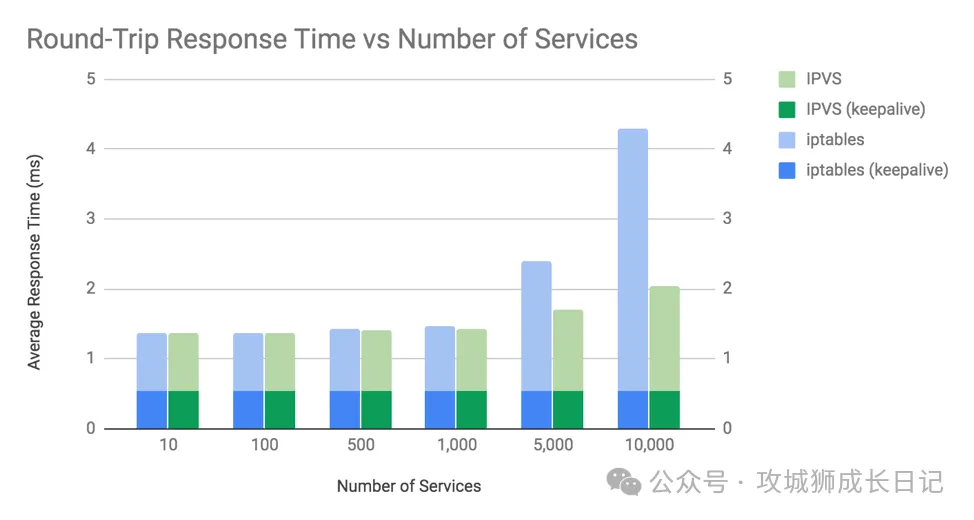
图表显示了两个关键点:
- 在超过 1,000 个服务(10,000 个后端 pod)之前,iptables 和 IPVS 之间的平均往返响应时间差异微不足道。
- 平均往返响应时间的差异仅在不使用 keepalive 连接时才明显。也就是说,当每个请求都使用新连接时,差异才会显现。
对于 iptables 和 IPVS 模式,kube-proxy 的响应时间开销与建立连接有关,而不是与连接上的数据包或请求数量有关。这是因为 Linux 使用连接跟踪(conntrack),能够非常高效地将数据包匹配到现有连接。如果数据包在 conntrack 中被匹配到,就不需要通过 kube-proxy 的 iptables 或 IPVS 规则来决定如何处理它。
值得注意的是,在这个例子中,“服务器”微服务使用的是 NGINX pod 提供一个小的静态响应体。许多微服务需要做的工作远不止这些,这将导致相应更高的响应时间,这意味着 kube-proxy 处理的时间差在这种图表中将占据更小的百分比。
最后有一个奇怪现象需要解释:为什么在 10,000 个服务时,非 keepalive 连接的响应时间在 IPVS 模式下变得更慢,即使 IPVS 中新连接的处理复杂度是 O(1)?要真正深入了解这一点,我们需要进行更多的挖掘,但其中一个因素是整个系统由于主机上增加的 CPU 使用而变得更慢。这也引出了下一个话题。
总CPU使用率
为了说明总 CPU 使用率,下面的图表集中在不使用持久/keepalive 连接的最坏情况下,此时 kube-proxy 连接处理的开销影响最大。
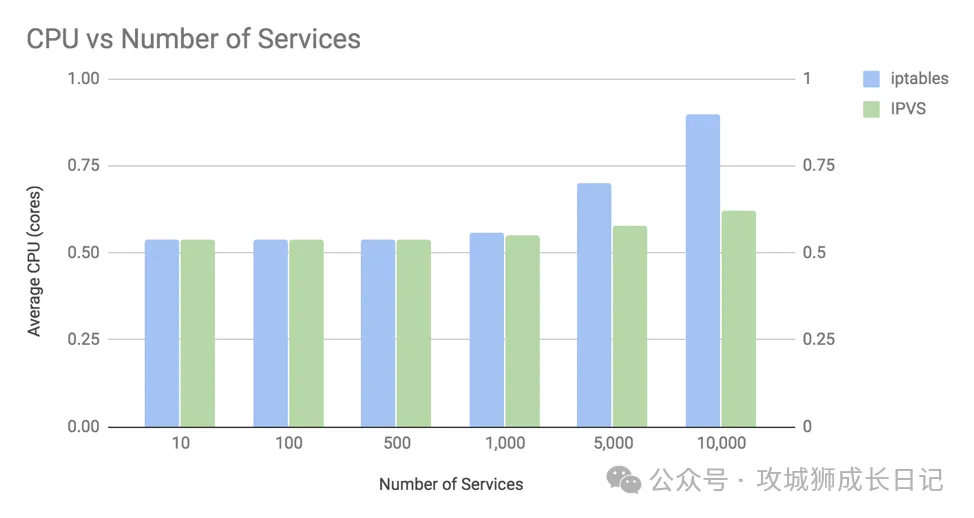
图表显示了两个关键点:
- 在超过 1,000 个服务(10,000 个后端 pod)之前,iptables 和 IPVS 之间的 CPU 使用率差异相对不显著。
- 在 10,000 个服务(100,000 个后端 pod)时,iptables 的 CPU 增加约为一个内核的 35%,而 IPVS 增加约为一个内核的 8%。
有两个主要因素影响这种 CPU 使用模式。第一个因素是,默认情况下,kube-proxy 每 30 秒重新编程一次内核中的所有服务。这解释了为什么即使 IPVS 的新连接处理名义上是 O(1) 复杂度,IPVS 模式下的 CPU 也会略有增加。此外,较早版本内核中重新编程 iptables 的 API 速度比现在慢得多。因此,如果您在 iptables 模式下使用旧版内核,CPU 增长将比图表中显示的更高。
第二个因素是 kube-proxy 使用 iptables 或 IPVS 处理新连接所需的时间。对于 iptables,这在名义上是 O(n) 复杂度。在大量服务的情况下,这对 CPU 使用有显著影响。例如,在 10,000 个服务(100,000 个后端 pod)时,iptables 每个新连接执行约 20,000 条规则。不过,请记住,在这个图表中,我们展示的是每个请求都使用新连接的最坏情况。如果我们使用 NGINX 默认的每个连接 100 次 keepalive 请求,那么 kube-proxy 的 iptables 规则执行频率将减少 100 倍,从而大大降低使用 iptables 而非 IPVS 的 CPU 影响,接近一个内核的 2%。
值得注意的是,在这个例子中,“客户端”微服务简单地丢弃了从“服务器”微服务接收到的每个响应。一个实际的微服务需要做的工作远不止这些,这将增加图表中的基础 CPU 使用率,但不会改变与服务数量相关的 CPU 增加的绝对值。
结论
在显著超过 1,000 个服务的规模下,kube-proxy 的 IPVS 模式可以提供一些不错的性能提升。具体效果可能有所不同,但一般来说,对于使用持久“keepalive”连接风格的微服务,且运行在现代内核上的情况下,这些性能提升可能相对有限。对于不使用持久连接的微服务,或者在较旧内核上运行时,切换到 IPVS 模式可能会带来显著的收益。
除了性能方面的考虑外,如果您需要比 kube-proxy 的 iptables 模式的随机负载均衡更复杂的负载均衡调度算法,也应该考虑使用 IPVS 模式。
如果您不确定 IPVS 是否会对您有利,那么坚持使用 kube-proxy 的 iptables 模式。它已经经过大量的生产环境验证,尽管并不完美,但可以说它作为默认选择是有原因的。
比较 kube-proxy 和 Calico 对 iptables 的使用
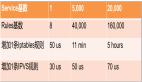
在本文中,我们看到 kube-proxy 使用 iptables 在非常大规模时会导致性能影响。我有时会被问到,为什么 Calico 没有遇到同样的挑战。答案是 Calico 对 iptables 的使用与 kube-proxy 有显著不同。kube-proxy 使用了一条非常长的规则链,其长度大致与集群规模成正比,而 Calico 使用的是非常短且优化的规则链,并广泛使用 ipsets,其查找时间复杂度为 O(1),不受其大小影响。为了更好地理解这一点,下面的图表显示了在集群中的节点平均托管 30 个 pod,且集群中的每个 pod 平均适用 3 个网络策略的情况下,每个连接由 kube-proxy 和 Calico 执行的 iptables 规则的平均数量。

即使在完全扩展的集群中运行,拥有 10,000 个服务和 100,000 个后端 pod 时,Calico 每个连接执行的 iptables 规则数量大致与 kube-proxy 在拥有 20 个服务和 200 个后端 pod 时执行的规则数量相同。换句话说,Calico 对 iptables 的使用是可扩展的!