一、腾讯大数据处理套件
TBDS的全称是腾讯大数据处理套件,它是一个基于 Hadoop 生态以及 MPP 生态的大数据平台。我们主要有以下的四种应用场景:大数据的批流的处理,云原生的数据湖,湖仓一体,以及国产化的数据中台。

下面是我们的一些客户,大家可以看到种类非常多,有金融类的、产业类的,还有传媒以及政府。不同用户的业务场景差别非常大,数据规模、集群规模的差别也非常大。他们对于大数据如何使用,对于数据服务的要求也非常的不一样。

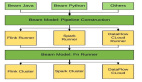
下图是金融场景的一个典型的技术方案:业务数据通过实时链路和离线链路进入大数据平台。在大数据平台中有两种类型的集群。第一类是事件中心集群,也可以叫实时计算中心集群;经过 Kafka、Flink数据处理之后再进入 Hive和 Elasticsearch,然后对外围的系统提供数据服务。另一类是离线计算集群,主要负责数据的批处理。

整个大数据平台是基于 Hadoop生态搭建的;得益于 Hadoop生态的繁荣,基本上每种特定的需求都可以找到合适的计算存储组件来满足。
除了 Hadoop,我们还提供基于 MPP的技术方案,它对于中小体量的客户更加合适。基于 MPP的来搭建数据平台,实时链路以及离线链路的数据都进入 MPP,然后来统一加工处理,最后也是由 MPP统一对外提供数据服务。

Hadoop还是 MPP?这两个生态之间的对比,其实业界已经讨论非常多了。随着各自的发展,我相信相关的讨论也会一直持续下去。例如对 Iceberg这样的数据湖表格式的支持,目前无论是 Spark还是 ClickHouse,都在做军备竞赛,现在的结论过两三个月可能就过时了。

但是有一点是肯定的,没有一个单独的生态,能够解决所有用户的所有问题。这种情况会持续很长的一段时间。即便现在已经是 2024 年了,很多客户他们的数据平台已经持续建设了很长的一段时间,多种集群、多种类型、多种版本的大数据系统,它们的共存是我们会经常遇到的一个问题。所以必然我们会遇到这么一个问题:如何来处理数据孤岛--不同的系统之间的数据该如何互通。
二、如何处理数据孤岛
我们都知道,如果是要做数据迁移、做 ETL,是一件成本非常高的事情。有的时候可以接受,但有的时候是很难去承担这样的成本的。

目前其实已经有一个可以跑通的技术方案,就是利用 Hive Metastore 作为统一的元数据中心。在图的右边是 MPP 的服务,在使用外表的模式下,它们可以使用 Hive Metastore 作为数据来源。左边是 Hadoop 生态下的计算引擎,它们基本上都会默认使用 Hive Metastore 作为它们的元数据服务。
在这样一个统一的元数据服务的情况下,再加上支持如 Iceberg 这样的表格式,提供统一的元数据的格式,基本上问题可以得到解决。这也是目前很多私有化场景下湖仓一体、湖上建仓的技术基础。
在上面的方案中,Hive Metastore 是绝对的核心,然而 Hive Metastore 本身还是有很多的局限性的。首先 Hive Metastore 是一个单纯的元数据技术和服务,基本上没有任何的治理能力。其次它的元数据模型完全是关系型的数据库模型,对于像 Message、Topic、文件,以及 AI 模型这类半结构化、非结构化的数据基本是不匹配的。而且它的服务设计也没有考虑到要承担如此重要的任务,所以有很明显的单点瓶颈。

在一个多集群的场景下面,它的方案会非常的复杂,但至少它还是可以跑的。那么数据孤岛看上去是有方案了,但是权限怎么办?Hadoop,还有 Hive Metastore,它本身也有一套比较简陋的权限模型,但是基本没有计算引擎来使用它,更别说 MPP 引擎了。

因此,如果没有一个统一的权限中心,单个资源的授权就需要在每一个子系统上面再重复地授权一遍,步骤非常繁琐,并且很容易出错。在 Hadoop生态下,Ranger是一个权限中心,它的机制是有点像 OPA (open policy agent),整个权限策略被 Manager统一的管理,然后各个计算引擎使用各自的 Plugin 进行授权。但是它的权限模型存在一定的问题。最重要的问题是它顶层设计的概念并不是以数据来划分的,而是以服务组件来划分的,不同的组件,如果要访问同样的数据,那么需要重复的授权,而且这只是当前 Hadoop生态的一个方案,MPP生态基本是没有权限管理。

我们其实也看到主流的云厂商基本提供了相关的产品来解决数据孤岛以及权限孤岛的问题。这样的解决方案一般都会被包装成为数据湖产品的一部分,例如 AWS的 Lake Formation,Databricks的 Unity Catalog,此外 Microsoft和 Google也有自己的产品。但是对于这样的商业公司所主导的产品,他们也有自己的局限性。

首先是对于计算引擎的支持比较少,也缺少私有云、尤其是非云化环境的部署方案。并且它们对于云厂商本身的依赖程度非常深。

因此,我们需要一个更加统一、更加清晰、同时也更加开放的产品,来更好地解决数据孤岛以及权限孤岛的问题。腾讯云和Datastrato一起,基于 Gravitino 的开源社区来合作,希望能够解决这样的问题。

三、Gravitino 能做什么
我来简单的介绍一下 Gravitino,它是一个使用 Apache License v2.0许可证的开源统一元数据服务,全面支持公有云、私有云以及非云环境的部署。它可以为多种的数据源提供统一的元数据视图,并且提供了标准的 SDK,可以开放的支持多种计算引擎的接入。

此外很重要的一点是,Gravitino提供了一个统一的、开放的权限管控机制。统一指的是统一的授权:对于所有的数据源,可以使用统一的模型和流程来进行授权;开放指的是开放的接入:对于数据源可以使对于各种计算引擎包括 MPP,以及存储,都能接入这样的权限模型,完成权限的管控。

四、Gravitino 的统一权限模型
对于数据系统来说,它的权限设计至关重要。但是现在的大部分企业的数据系统有很多种类型,有 MPP类型,也有一些在线的例如 MySQL、PostgreSQL这样的数据库,以及 Hadoop上的 HDFS、Spark、Hive等的大数据组件。这些的数据系统带来了异构的数据栈,对于目前的一些权限的设计,就很难有统一的权限入口来做统一的管理。
对于企业来说,这样的情况对于它构建自己的数据生态带来了很大的不便。为此,在计算机系统里有这样一句话:没有任何问题不是可以通过加一层来解决的。在去年的时候,我们公司开源了 Gravitino这样一款元数据管理软件,用于解决这种跨数据栈的元数据管理。我为大家主要讲一下 Gravitino的权限模型。

首先我介绍一下权限模型,业界比较常见的权限模型有 ABAC、RBAC等等,但是目前还是以 RBAC为主。Gravitino在这块儿也是采用了 RBAC的权限模型。
首先我们可以看出这张图里有几个概念,第一个概念就是 Metalake。第二个是 Role,第三个是 User。
对于 Metalake 来说,我们可以把它看作是一个组织;一般来说,一个企业就是一个 Metalake,它只有一个组织。在 Metalkae 下面会挂载 Role 以及 User。
Role主要是我们权限模型中用来管理权限的核心概念,它会绑定具体的一些权限。Role是实体的具体的某些权限的集合。在实际的使用的过程中会把 Role授权给 User,Role和 User是多对多的关系,可以去进行比较灵活的绑定。
讲完了权限模型,我介绍一下统一权限的系统架构。Gravitino的权限大概可以分为两部分:第一部分是,它对于自身会有内建的鉴权,主要负责对于自身管理的一部分的元数据进行鉴权,比如说 Metalake 的一些鉴权,比如说自有的一些数据实体的鉴权。同时它还提供了强大的插件机制,用来对接一些外部系统的权限。

目前权限插件会有四类,第一类是 Native Catalog的权限插件,主要用于大数据生态的权限鉴权,这主要是考虑了一些用户,他们不想引入类似于 Ranger这种额外的大数据权限管理组件,进行简便的一些数据权限的管理。
第二类是正就像前面徐潇所说的,在大数据体系当中,Ranger是一个比较主流的权限管理系统。这里会提供 Ranger的 Catalog的权限鉴权的插件,然后通过它来去对大数据的体系进行整体的权限管控。
第三类是对于 MPP、数据库这类系统,它们一般会提供 JDBC 接口。我们会对这样的系统来提供 JDBC Catalog鉴权的插件,来对这样的系统进行权限的管控。
第四类是对于很多的云上的生态,比如 AWS、Azure,它们会有像 IAM这样的权限管理系统。对于这种我们会提供云的 Cloud Catalog的鉴权插件。
整体的来说,Gravitino是通过自建的鉴权机制,以及结合丰富的外部鉴权插件机制,来实现对权限机制的统一。
在这个过程中 Gravitino对外暴露 RESTful的 API接口,然后将用户的各种权限设置的请求,通过自身的逻辑以及模型的转换,通过插件透传给下游的各种不同的数据生态,从而达到让 Gravitino成为权限入口的效果。
接下来可以看这张图,来结合具体的例子给大家分享 Gravitino的授权过程。

可以看到,左边是认证 Server,会支持三种认证服务。第一种是 OAuth的认证,第二种是 Kerberos认证,Kerberos认证在大数据的生态用得会比较多一点;第三种是 IAM 认证,对于云的系统 IAM会使用得比较多。
整体会提供对用户的认证,然后是数据授权的过程。Gravitino 在参与的过程中会有三个角色:第一个角色是Service Admin,它的职责其实比较简单,就是创建 Metalake;第二个角色是 MetalakeAdmin,主要对 Metalake下面的 Role的创建和管理,以及对各种权限的 Role的创建,并把这些 Role和具体的 User进行绑定。第三个角色是普通 User,他可能是新加入的 User,负责具体的数据实体的创建,例如创建 Catalog、数据库、表,然后读取这些表。
在这个过程中,我们可以简单来看一下简单的创建 Catalog和之后创建表的过程。第一步是 Service Admin会去创建 Metalake,之后 Metalake admin会去创建 Role,然后创建需要具体使用的 User,然后去创建 Catalog,然后开通了Catalog的 Manager Role,去把 Catalog Manager Role赋予给 new user。New user就可以具体创建 Catalog,例如可以创建 Hive Catalog,创建 MySQL Catalog。这个时候 Metalake admin可以去创建 Hive的 Schema Manager,把Schema Manager授予给 new user,然后 new user就可以创建 Schema。之后 Metalake admin可以创建Hive Table的 Manager role,再把 Hive Table的 Manager role授予给 new user,就可以具体去去创建 Hive Table。
对于 MySQL也是同样的,会去创建Catalog、Table。当 Hive catalog 以及 MySQLCatalog和 HiveTable都创建完之后,具体的 new user就可以读取这两个表。