













在机器学习和数据科学领域,模型的可解释性一直是研究者和实践者关注的焦点。随着深度学习和集成方法等复杂模型的广泛应用,理解模型的决策过程变得尤为重要。可解释人工智能(Explainable AI ,XAI)通过提高模型的透明度,帮助建立对机器学习模型的信任和信心。
XAI是一套工具和框架,用于理解和解释机器学习模型如何做出决策。其中,Python中的SHAP(SHapley Additive exPlanations)库是一个非常有用的工具。SHAP库能够量化特征对单个预测及整体预测的贡献,并提供美观且易于使用的可视化功能。
接下来,我们将概括介绍下SHAP库的基础知识,以理解在Scikit-learn中构建的回归和分类模型的预测。
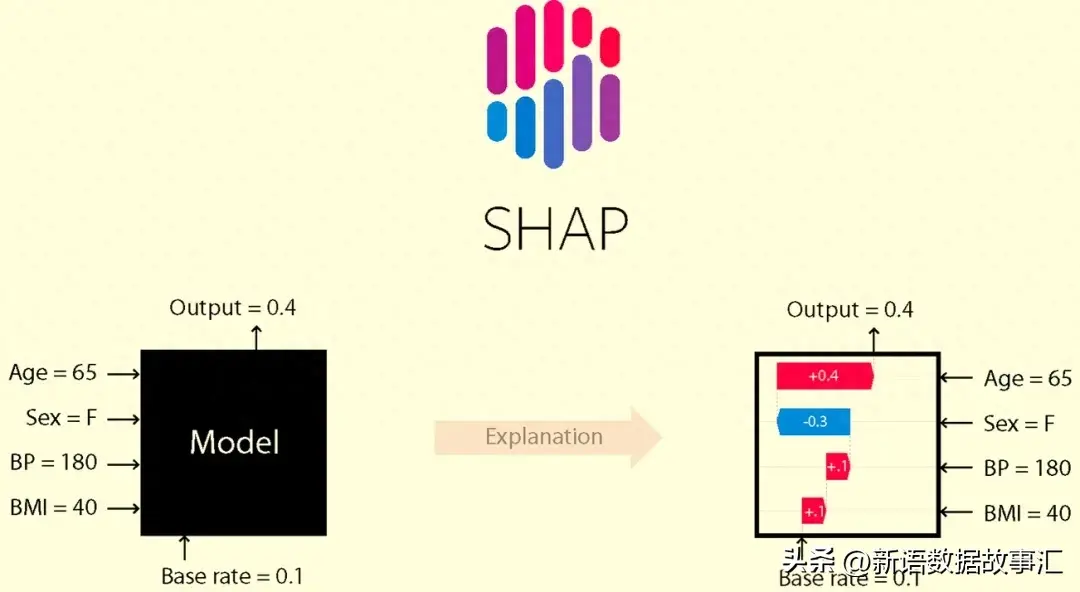
SHAP 和SHAP values
SHAP(SHapley Additive Explanations)是一种解释任何机器学习模型输出的博弈论方法。它利用经典的博弈论Shapley值及其相关扩展,将最优的信用分配与局部解释相结合(详细信息和引用请参阅相关论文:https://github.com/shap/shap#citations)。
SHAP values帮助我们量化特征对预测的贡献。SHAP值越接近于零,表示该特征对预测的贡献越小;而SHAP值远离零,表示该特征对预测的贡献越大。
安装shap 包:
我们看下面的示例:如何在回归问题中获取特征的SHAP值。我们将从加载库和示例数据开始,然后快速构建一个模型来预测糖尿病的进展情况:
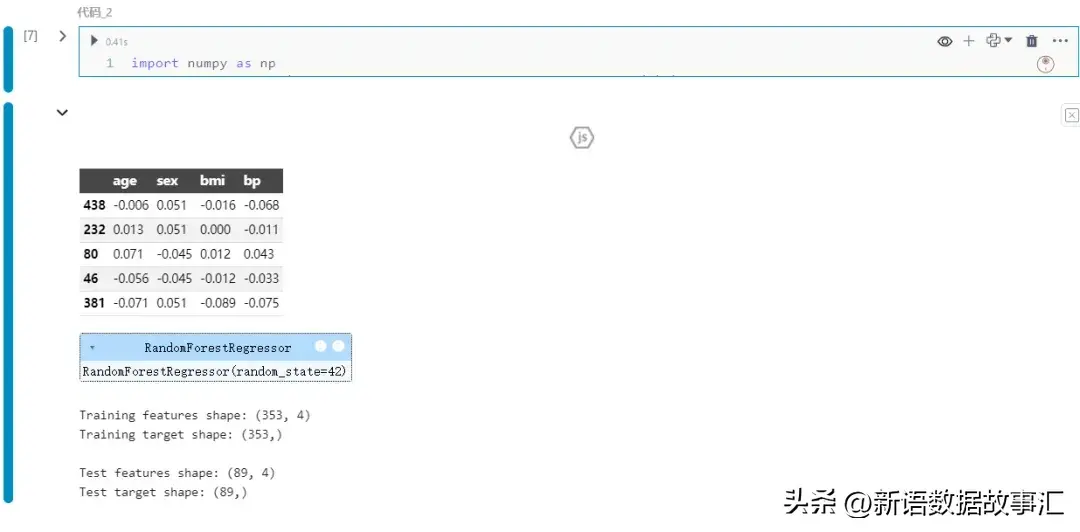
一种常见的获取SHAP值的方法是使用Explainer对象。接下来创建一个Explainer对象,并为测试数据提取shap_test值:

shap_test的长度为89,因为它包含了每个测试实例的记录。从查看第一个测试记录中,我们可以看到它包含三个属性:
shap_test[0].base_values:目标的基准值
shap_test[0].data:每个特征的值
shap_test[0].values:每个对象的SHAP值
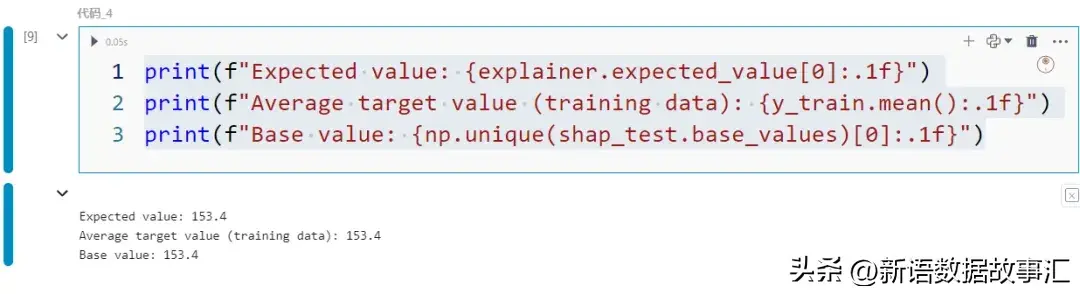
- 基准值:基准值(shap_test.base_values),也称为期望值(explainer.expected_value),是训练数据中目标值的平均值。
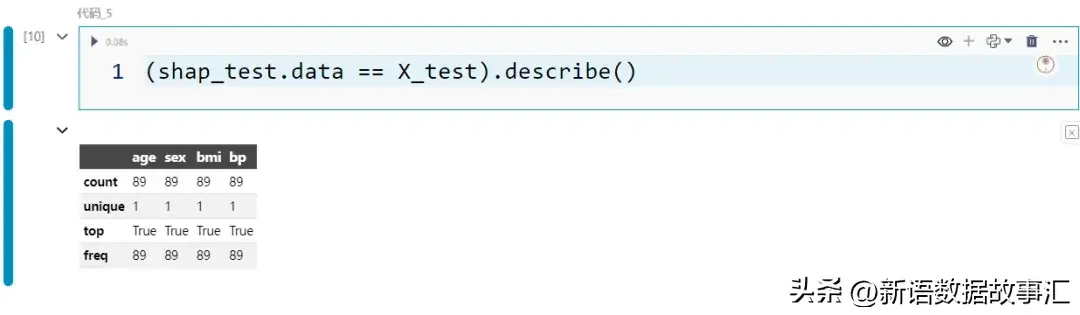
- shap_test.data 包含与 X_test 相同的值
- values:shap_test 最重要的属性是 values 属性,因为我们可以通过它访问 SHAP 值。让我们将 SHAP 值转换为 DataFrame,以便于操作:

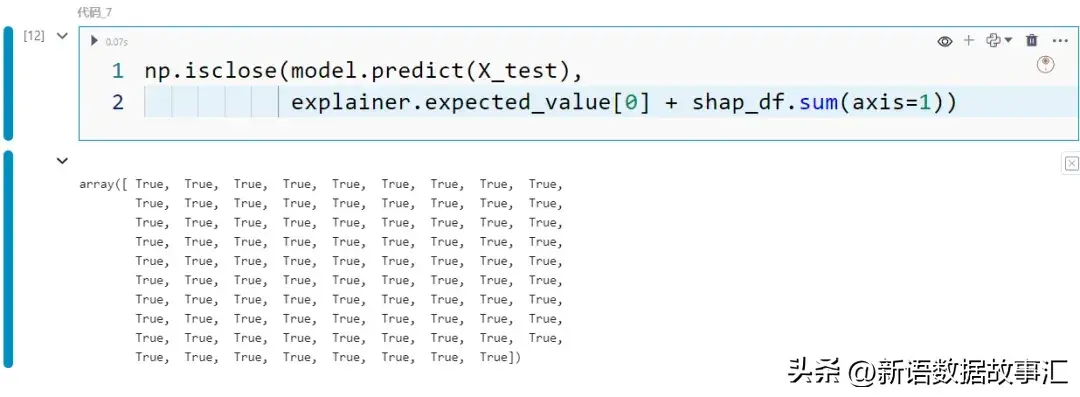
可以看到每条记录中每个特征的 SHAP 值。如果将这些 SHAP 值加到期望值上,就会得到预测值:

现在我们已经有了 SHAP 值,可以进行自定义可视化,如下图所示,以理解特征的贡献:

左侧子图显示了每个特征的平均绝对 SHAP 值,而右侧子图显示了各特征的 SHAP 值分布。从这些图中可以看出,bmi 在所使用的4个特征中贡献最大。
Shap 内置图表
虽然我们可以使用 SHAP 值构建自己的可视化图表,但 shap 包提供了内置的华丽可视化图表。在本节中,我们将熟悉其中几种选择的可视化图表。我们将查看两种主要类型的图表:
- 全局:可视化特征的整体贡献。这种类型的图表显示了特征在整个数据集上的汇总贡献。
- 局部:显示特定实例中特征贡献的图表。这有助于我们深入了解单个预测。
- 条形图/全局:对于之前显示的左侧子图,有一个等效的内置函数,只需几个按键即可调用:

这个简单但有用的图表显示了特征贡献的强度。该图基于特征的平均绝对 SHAP 值而生成:shap_df.apply(np.abs).mean()。特征按照从上到下的顺序排列,具有最高平均绝对 SHAP 值的特征显示在顶部。
- 总结图/全局:另一个有用的图是总结图:

以下是解释这张图的指南:
- 图的横轴显示了特征的 SHAP 值分布。每个点代表数据集中的一个记录。例如,我们可以看到对于 BMI 特征,点的分布相当散乱,几乎没有点位于 0 附近,而对于年龄特征,点更加集中地分布在 0 附近。
- 点的颜色显示了特征值。这个额外的维度允许我们看到随着特征值的变化,SHAP 值如何变化。换句话说,我们可以看到关系的方向。例如,我们可以看到当 BMI 较高时(由热粉色点表示)SHAP 值倾向于较高,并且当 BMI 较低时(由蓝色点表示)SHAP 值倾向于较低。还有一些紫色点散布在整个光谱中。
- 热力图/全局:热力图是另一种可视化 SHAP 值的方式。与将 SHAP 值聚合到平均值不同,我们看到以颜色编码的个体值。特征绘制在 y 轴上,记录绘制在 x 轴上:

这个热力图的顶部还补充了每个记录的预测值(即 f(x))的线图。
- Force plot/全局:这个交互式图表允许我们通过记录查看 SHAP 值的构成。
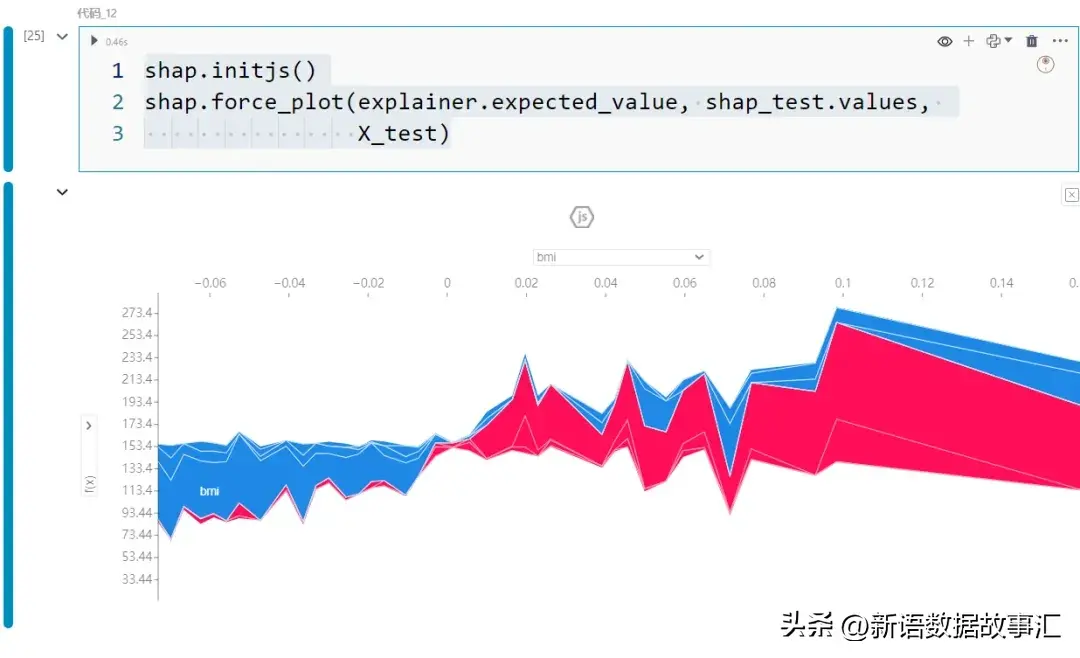
就像热力图一样,x 轴显示每个记录。正的 SHAP 值显示为红色,负的 SHAP 值显示为蓝色。例如,由于第一个记录的红色贡献比蓝色贡献多,因此该记录的预测值将高于期望值。
交互性允许我们改变两个轴。例如,y 轴显示预测值 f(x),x 轴根据输出(预测)值排序,如上面的快照所示。
- 条形图/局部:现在我们将看一下用于理解个别案例预测的图表。让我们从一个条形图开始:
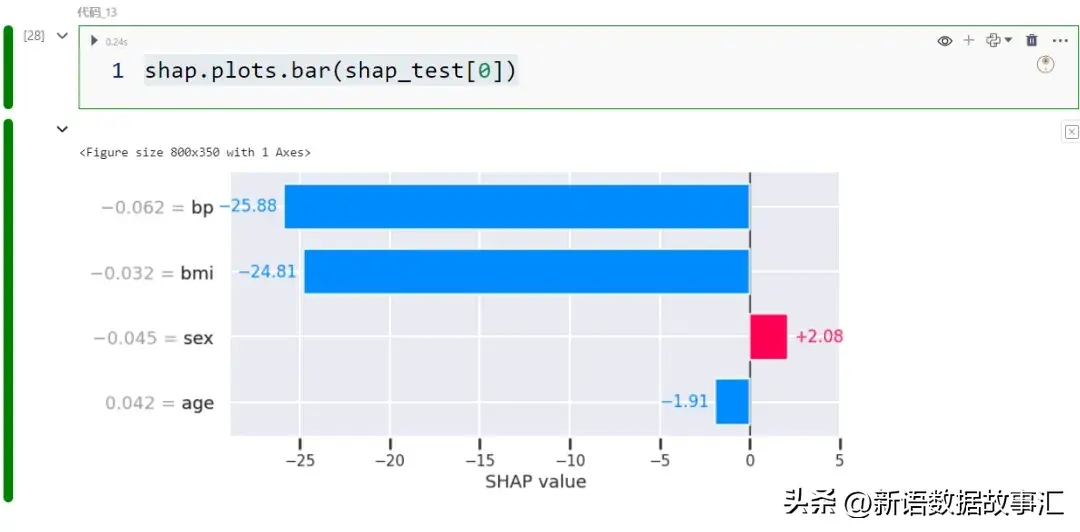
与“ 条形图/全局 ”中完全相同,只是这次我们将数据切片为单个记录。
- Force plot/局部:Force plot是单个记录的强制图。
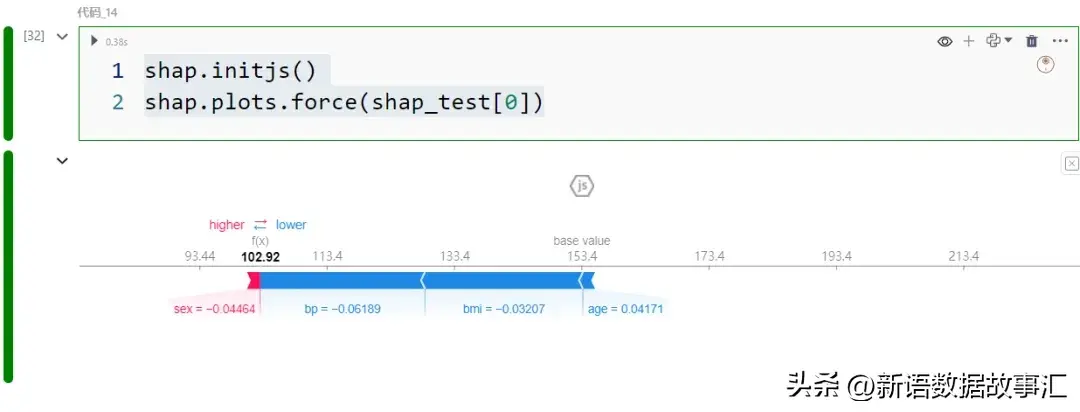
分类模型的SHAP values/图表
上面示例是回归模型,下面我们以分类模型展示SHAP values及可视化:

和回归模型一样的,shap values 值也是包括base_values 和values 值:
我们仔细检查一下将 shap 值之和添加到预期概率是否会给出预测概率:

内置图与回归模型是一致的,比如:

或者瀑布图如下:
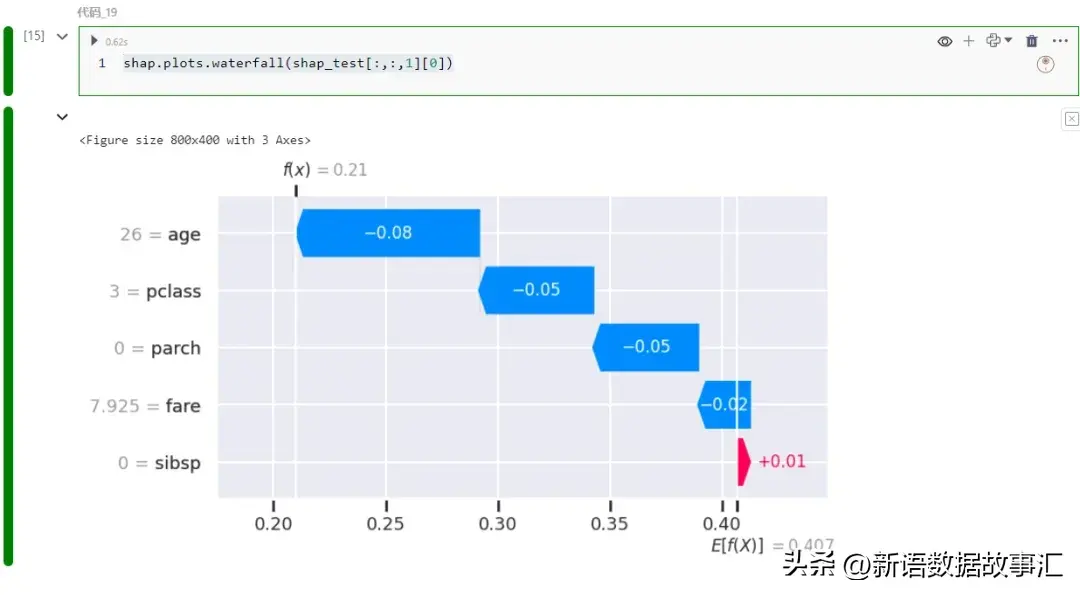
示例
看一个具体的用例。我们将找出模型对幸存者预测最不准确的例子,并尝试理解模型为什么会做出错误的预测:
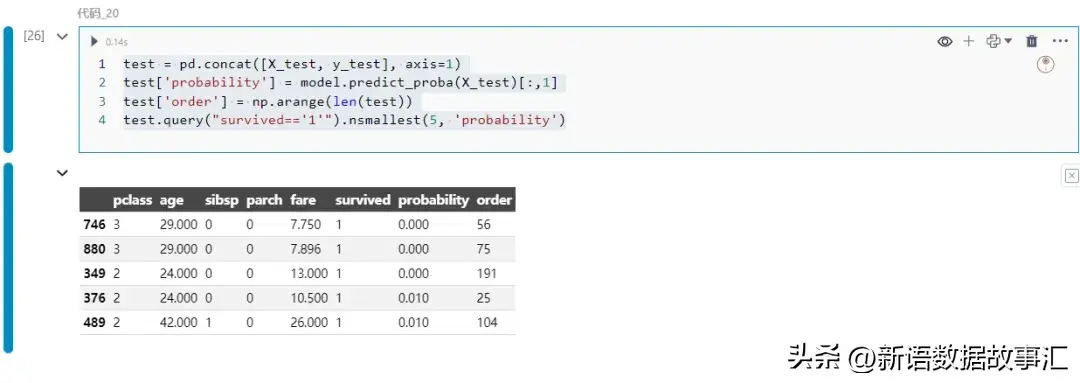
生存概率为第一个记录的746。让我们看看各个特征是如何对这一预测结果产生贡献的:

主要是客舱等级和年龄拉低了预测值。让我们在训练数据中找到类似的例子:
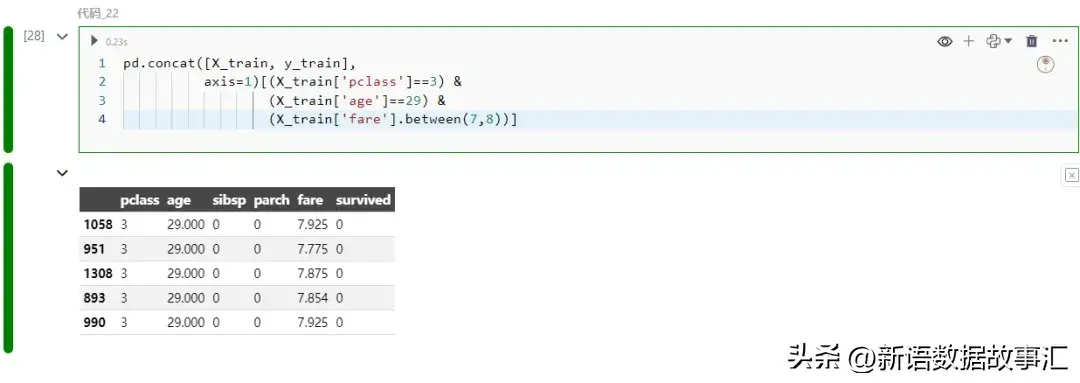
所有类似的训练实例实际上都没有幸存。现在,这就说得通了!这是一个小的分析示例,展示了 SHAP 如何有助于揭示模型为何会做出错误预测。
在机器学习和数据科学中,模型的可解释性一直备受关注。可解释人工智能(XAI)通过提高模型透明度,增强对模型的信任。SHAP库是一个重要工具,通过量化特征对预测的贡献,提供可视化功能。本文介绍了SHAP库的基础知识,以及如何使用它来理解回归和分类模型的预测。通过具体用例,展示了SHAP如何帮助解释模型错误预测。





























