












本文经自动驾驶之心公众号授权转载,转载请联系出处。
昨天面试被问到了是否做过长尾相关的问题,所以就想着简单总结一下。
自动驾驶长尾问题是指自动驾驶汽车中的边缘情况,即发生概率较低的可能场景。感知的长尾问题是当前限制单车智能自动驾驶车辆运行设计域的主要原因之一。自动驾驶的底层架构和大部分技术问题已经被解决,剩下的5%的长尾问题,逐渐成了制约自动驾驶发展的关键。这些问题包括各种零碎的场景、极端的情况和无法预测的人类行为。
自动驾驶中的边缘场景
长尾”是指自动驾驶汽车 (AV) 中的边缘情况,边缘情况是发生概率较低的可能场景。这些罕见的事件因为出现率较低且比较特殊,因此在数据集中经常被遗漏。虽然人类天生擅长处理边缘情况,但人工智能却不是这样。可能引起边缘场景的因素有:带有突起的卡车或者异形车辆、车辆急转弯、在拥挤的人群中行驶、乱穿马路的行人、极端天气或极差光照条件、打伞的人,人在车后搬箱子、树倒在路中央等等。
例子:
- 放透明薄膜在车前,透明物体是否可以被识别,车辆是否会减速
- 激光雷达公司Aeye就做了一次挑战,自动驾驶如何处理一个漂浮在路中央的气球。L4级无人驾驶汽车往往偏向避免碰撞,在这种情况下,它们会采取规避动作或者踩刹车,来避免不必要的事故。而气球是个软性的物体,可以直接无障碍的通过。
解决长尾问题的方法
合成数据是个大概念,而感知数据(nerf, camera/sensor sim)只是其中一个比较出圈的分支。在业界,合成数据在longtail behavior sim早已成为标准答案。合成数据,或者说sparse signal upsampling是解决长尾问题的第一性解法之一。长尾能力是模型泛化能力与数据内含信息量的乘积。
特斯拉解决方案:
用合成数据(synthetic data)生成边缘场景来扩充数据集
数据引擎的原理:首先,检测现有模型中的不准确之处,随后将此类案例添加到其单元测试中。它还收集更多类似案例的数据来重新训练模型。这种迭代方法允许它捕获尽可能多的边缘情况。制作边缘案例的主要挑战是收集和标注边缘情况的成本比较高,再一个就是收集行为有可能非常危险甚至无法实现。
NVIDIA解决方案:
NVIDIA 最近提出了一种名为“模仿训练”的战略方法(下图)。在这种方法中,真实世界中的系统故障案例在模拟环境中被重现,然后将它们用作自动驾驶汽车的训练数据。重复此循环,直到模型的性能收敛。
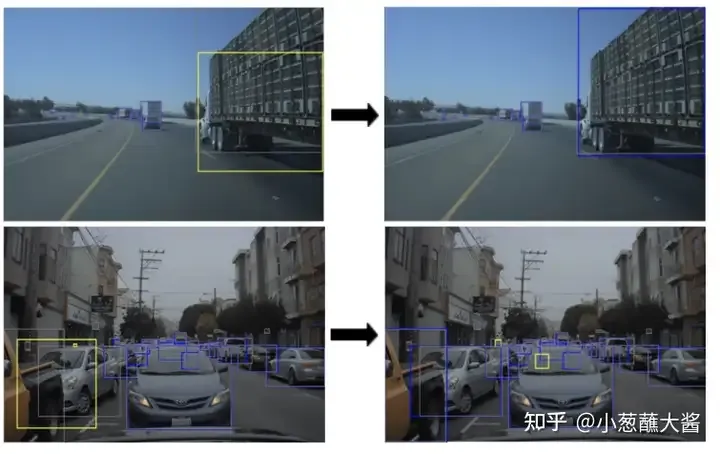
以下真实场景中由于卡车高度过高(上)、车辆凸出部分遮挡后车(下)导致模型输出时车框丢失,成为边缘场景,过NVIDIA改进后的模型可以在此边缘情况下生成正确的边界框:
一些思考:
Q:合成数据是否有价值?
A: 这里的价值分为两种 , 第一种是测试有效性, 即在生成的场景中测试 是否能发现探测算法中的一些不足, 第二种是训练有效性, 即生成的场景用于算法的训练是否也能够有效提升性能。
Q: 如何使用虚拟数据提升性能?虚拟数据真的有必要添加到训练集中去吗?添加进去了是否会产生性能回退?
A: 这些问题都难以回答, 于是产生了很多不一样的提高训练精度的方案:
- 混合训练:在真实数据中添加不同比例的虚拟数据, 以求性能提升,
- Transfer Learning:使用真实数据预训练好的模型,然后Freeze 某些layer, 再添加混合数据进行训练。
- Imitation Learning:针对性设计一些模型失误的场景, 并由此产生一些数据,进而逐步提升模型的性能, 这一点也是非常自然的。在实际的数据采集和模型训练中, 也是针对性采集一些补充数据, 进而提升性能。
一些扩展:
为了彻底评估 AI 系统的稳健性,单元测试必须包括一般情况和边缘情况。然而,某些边缘案例可能无法从现有的真实世界数据集中获得。为此,人工智能从业者可以使用合成数据进行测试。
一个例子是ParallelEye-CS,这是一种用于测试自动驾驶汽车视觉智能的合成数据集。与使用真实世界数据相比,创建合成数据的好处是可以对每个图像的场景进行多维度控制。
合成数据将作为生产 AV 模型中边缘情况的可行解决方案。它用边缘案例补充现实世界的数据集,确保 AV 即使在异常事件下也能保持稳健。它也比真实世界的数据更具可扩展性,更不容易出错,并且更便宜。






















