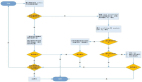
一、为什么 GPU 推荐模型训练框架是刚需
1. PCG 算力集群缺点

最开始的时候,腾讯 PCG 所有的推荐模型训练都是使用 CPU。但随着业务的深入,以及深度学习模型的发展,PCG 算力集群在做下一代推荐模型时会遇到各种问题:
- 首先,系统网络带宽小,不稳定。
- 另外,很多推荐模型都很大,我们要考虑用多机多卡还是单机多卡,这就涉及到硬件的选型。
- 第三,云上分配到的 CPU 型号不能保证,有时会有一些 AMD 的 CPU,有时也会是一些英特尔的 CPU,这对于参数服务器架构也是非常不利的,如果 CPU 型号老旧,就会导致性能瓶颈,影响整体训练框架的性能。
- 第四,云容器非独占,整个机器的 IO 网络都是共享的,因此可能导致整体训练框架不稳定。
上述问题表明整个参数服务器已难以支持大参数量的推荐模型。因此需要改用 GPU,且只能用单机多卡的方式训练非常大的模型。

我们遇到的问题主要包括,传统网络带宽小,不稳定,InfiniBand 价格昂贵,而且要改造机房。另外,如果在设计 GPU 训练的时候采用多机多卡,就会涉及到要把哪些机器换下来,加上一些支持 InfiniBand 网卡。也需要对机房进行 switch 的改造,所以也会导致 GPU 的机器改造成本非常的昂贵,这就决定了整个技术架构要采用单机多卡这样一个硬件选型。

另外一个问题是 CPU 型号老,如果用多机多卡也会导致训练集群每个节点的性能都不稳定。这是因为 GPU 在容器中是共享的,因此不能确保每一个 GPU affiliate 到特定的 CPU。如果多机多卡,CPU 调度分配会给上层的 K8s 的调度集群带来非常大的压力,也会导致出现很多 GPU 碎片。
2. 业务,上游生态

接下来从硬件现状、业务以及上游生态的角度来看一下我们的技术目标。首先确定一个大目标,就是单机多卡去训练一个非常大的模型,这个大模型的量级是几 TB 到 10 TB。
另一个目标是尽量利用硬件的一些特性,利用硬件的整个机器不单只是 SSD、host memory,还有网卡,来提高模型训练的大小上限。
整个架构要满足离线训练以及在线训练。这是因为离线训练是用来追模型的,而在线训练是实时更新模型。所以我们的架构也要考虑如何快速上线、快速部署。
关于 GPU 硬件加速器的选型,要考虑 GPU 的供货问题,所以我们在整个架构设计上也要考虑到不能仅支持 GPU,还要支持 XPU。
MLP 的架构选型,我们选择了 TensorFlow,但是整个框架可以快速切换到 PyTorch,目前也正在做这样的事情。
同时,还要考虑兼容老的参数服务器技术方案,能够从 CPU 的训练和推理快速迁移到 GPU,降低迁移成本。出于这样的考虑,要兼容参数服务器。
以上就是我们根据目标进行的技术选型。
二、GPU 推荐模型训练框架怎么做才最高效
1. GPU 训练的数据结构

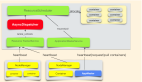
接下来介绍 GPU 推荐模型训练框架的设计。首先要明确数据结构。我们的大目标是单机多卡,因此肯定要有 SSD,然后是 host memory 和 GPU,这几个层级与传统的 GPU 训练框架非常相似。我们也采用了三级缓存的设计,但是考虑到最下层是对象存储,是用来存模型的,还有样本的输入,存储空间非常大,可以有几 TB,甚至上百 TB 。因为其存在远端,读写速度只有几 GB 到几百 MB 的量级。我们需要考虑将读写的过程跟训练的过程进行分离。
我们尽可能将读写分离,因此要把样本以及模型落盘到 SSD,SSD 的性能只有几到十几 GB 每秒,所以也需要对 SSD 读写以及它的训练过程进行分离。
另外是 host memory。Host memory 跟 GPU 的 HBM 读写速度已经有几十 GB 每秒,所以在此处设计上会有一个快速的快交换。
GPU 的 HBM 容量有几十 GB,可以以块的形式刷进 HBM,然后 HBM 再以 batch 的形式进行训练。
数据结构整体分了四级,如上图所示,图中颜色与左侧存储的地方对应。首先是对应不同 DataSet,会有很多数据,我们会把所有的数据分成不同的 group,不同的 group 又细分到不同的 PASS,一个 PASS 又会包括多个 batch。这样分块就刚好满足了模型的读写性能以及不同的硬件特性。
2. GPU 训练整体架构

训练流程如上图所示。因为一些硬件特性的原因,我们会把训练过程以及数据读写过程进行分离。当开始训练时,首先会预先下载非常多的数据,将一个 group 的数据下载下来,然后进行预处理,处理完一个 group 之后会把 group 放到 host memory 里面,然后把单个 PASS 以整块的方式 flash 到 GPU 的 HBM 里面。因为 GPU 的 HBM 已经有很多个 batch 了,GPU 的流式处理器访问 global memory 的时候读写速度也会比较快,所以我们在整个过程里面就可以在 PASS 放到 HBM 以后,以 batch 进行每一轮的同步训练。图中可以看到,compute 就是 forward-backward 同步训练,处理完全部 group 以后,会进行模型导出。
模型的数据下载和预处理等每个阶段都是可以并发的,所以我们可以做到多级流水线的并发,将硬件资源的带宽打满。每一个 compute 的过程,forward 和 backward 都会涉及到 GPU。因为推荐模型训练的计算任务都是 memory bound 的,所以我们会将每一个访存的瓶颈列出来。因为每一次 forward backward 都是一个 batch,所以 global memory 的访存也是一个瓶颈。到预处理阶段,因为多级缓存的设计,所以涉及到 CPU 的瓶颈以及 CPU IO 读取的瓶颈。还有一些业务上线的考量,没有显存访存的限制,这些限制很大程度上决定着大模型训练框架的性能。后面还会详细介绍相关优化。

下载数据过程中的优化手段比较杂,难成体系。首先因为下载会涉及到网络,因此会用到 DPDK 这样的网络优化库。在网络访问中,可能要通过 TCP 的手段去访问远端的一些东西,所以也会用到 Google 的 BBR 拥塞控制算法去优化网络窗口,从而优化下载速度。第三个是 DMA,网卡每下载一批数据,就可以用更少的 CPU 去完成这一下载动作。第四是落盘,在计算过程中,以及 group 交换的过程中需要用到这样的一个优化手段,因为每一个 SSD 盘的带宽是有限的,假如一台机器配备多个 SSD 盘,然后每多个 SSD 盘可以通过 LVM 虚拟出来,这样多个盘就可以并行访问了,即可加快数据下载的速度。第五是 direct IO,因为我们不需要做太多的 cache IO,所以可以直接用 direct IO 去完成 group 落盘的操作。最后是数据结构的一些优化,例如我们采用了 Parquet 列存,这样既可减少 IO 的一些 linux kernel 内核的终端操作,也可以把数据变成一个平整的大块,更利于对数据进行并发处理。
3. 各阶段优化详细介绍

下面介绍预处理阶段的优化。首先我们会把每一次每一个 group 所用到的去重之后的 key 先捞出来,将这些 key 里的 feature 变成 CSR 格式,这两点非常重要,因为 CSR 格式可以减少访存的 cache miss rate。另外,可以通过去重的 keys,对所需要的数据进行预处理,这样就可以实现整块 flash 到 GPU memory 的高效操作。
在前文对数据结构的介绍中提到,整体是一个三块的结构,其大小是从下往上递减的,那么其内部数据结构是怎样的呢?一个 group 会先预处理,然后落盘,与训练过程是分离的,所以它会把每一个 key 要用到的 embedding Vector 以及它的 optimizer state 先提取出来落盘,然后我们会把它变成一个 sample,一个 sample 变成一个 CSR 的数据,然后多个 CSR 的 sample 会变成一个 CSR 的 batch,放到 PASS 里。每一个 CSR 会存在 PASS 里面,由多个 PASS 组成一个 group。因为整个过程中要尽量节省 host memory,所以会先把它落盘到 SSD。

在开始训练 PASS 全部数据之前,先将 PASS 需要的全部 embedding vector 整块 flash 到 GPU 显存上的 embedding 里面。如上图中红框的部分,就是已经准备好数据了,绿色的 PASS 部分刚好对应上三级缓存中绿色的一块。整块 flash 到 GPU 的 global memory 里面,在 global memory 里面存的一个 PASS 的结构是 CSR 的 batch 以及这个 batch 所要用到的 embedding Vector。这个 embedding 绿色这一块其实是一个 GPU 的 hashtable。这里我们做了一个特异化的处理,传统的 GPU hashtable 有增删查改之类的过程,而我们直接将插入功能去除了,因为我们已经把整块数据处理好了,不再需要 hashtable 的 insert 过程,所以将 insert 去掉,然后把整块的 hashtable 的数据结构准备好,直接 flash 到 global memory 里面。这样性能也会非常好,而且每一次 embedding 只存一个 group 所需要的训练数据,GPU 的显存就只关注这一个 group 数据的 embedding vector 就够了。
只要 SSD 能存得下,那么本地单机多卡就能训练得了多大的模型。例如这样一个架构,虽然单机多卡,总的显存只有 320 GB,但可以训练十几 TB 的模型,这也是我们的框架的优势之一。正如前面介绍的,每一个计算过程里面,我们会把 PASS flash 到 GPU memory,在每一次 forward backward 的过程中会捞一个 batch 进行 forward,然后到 TensorFlow 的一个计算图,再 backward 回来。这中间有一个黄色的箭头,代表 TensorFlow 在 forward backward 时可以用 tape。因为每一个 TensorFlow 的计算都是 batch 数据并行的,所以每一个 TF 的计算图都会虚拟一个小的块,这个块会在 forward backward 之后返回一个梯度,梯度会在一个多卡的 buffer 里面做 reduce 这样一个操作。然后 scatter 到不同的卡上,因为 key 已经对于每一个卡做了哈希,所以在每一个 batch 里面,哪一个 key 在哪一个卡上也是固定。

接下来介绍一下 Compute 过程中的优化手段。空间优化方面,首先 embedding 部分,我们对其空间复杂度进行了优化,主要手段是 Dynamic embedding,就是 key value 指向一个 embedding vector,并且这个 embedding vector 不是定长的,embedding vector Lens 可以从 0 到最大的 Lens 过渡,这样就很容易实现 Dynamic embedding。
第二个优化是 Multiple Hash,即一个 hashtable 可以分解成两个 hashtable,其空间大小也可以从一个 hashtable 变成多个小的 hashtable,这样空间也可以得到优化。
第三是混合精度训练,这个做法比较大众化,但确实是一个比较好的空间优化手段。
计算优化方面,首先是 Unified Hash Table,因为不同的特征会放在不同的 embedding table 里面。通过对 key 进行 rehash,因为 key 的数据特征是 int64,我们用低 48 位去存真实的 key,高 16 位存 hashtable 的 ID,这样就可以把所有特征打散到一个非常大的 hashtable,查找的过程就只要一个 kernel,backward 时候也只要一个 kernel 就可以进行 update,从而节省了 kernel launch 的开销。
第二是 kernel merge,这也是我们最近做的一个比较新的功能。
第三是混合精度,其实不仅是优化空间,因为在 GPU 上面我们有 FP16,FP16 可以用向量化访存,也可以用 half2 这样的子数据结构去做多数据的指令融合。所以这个其实也是有计算优化的。
最后一个是非对称结构的 hash table。

上图是对 unified hash table 的详细介绍。

再详细介绍一下 kernel merge,把相同的一些参数合到一起,这样 pooling 的kernel 开销就可以降低了。另外这些都涉及到 GPU 的一些优化,在此不做详细展开。

我们的业务上需要增量模型、全量模型的分块操作,每天更新一个全量模型,每小时更新一个增量模型,这样就可以快速地进行上线。

模型更新、模型上线的优化手段主要包括,INT 量化、异步 IO 以及腾讯云的 COS 协程队列等。
三、未来展望

最后是对未来工作的展望。首先,因为 GPU 卡供应比较紧张,将来可能无法使用 A100 去做训练,因此需要考虑如何在 A10/T4/P4 上进行训练,或在非英伟达 GPU 上进行训练。第二是推荐大模型与 GPT 的结合。第三是更灵活的架构,例如 PS 以及 embedding 是不是一定要在 GPU 上,甚至 GPU 的训练能不能结合 PS 的架构去做更大。第四是更大规模的训练,我们目前只支持单机多卡,模型级别上限只达到 TB 级,之后要考虑能否支持 PB 级。最后是希望使用更低的硬件配置来训练更大的模型。