单服务器设置
在单服务器设置中,所有内容都运行在一台服务器上。这包括网页应用程序、数据库、缓存等。
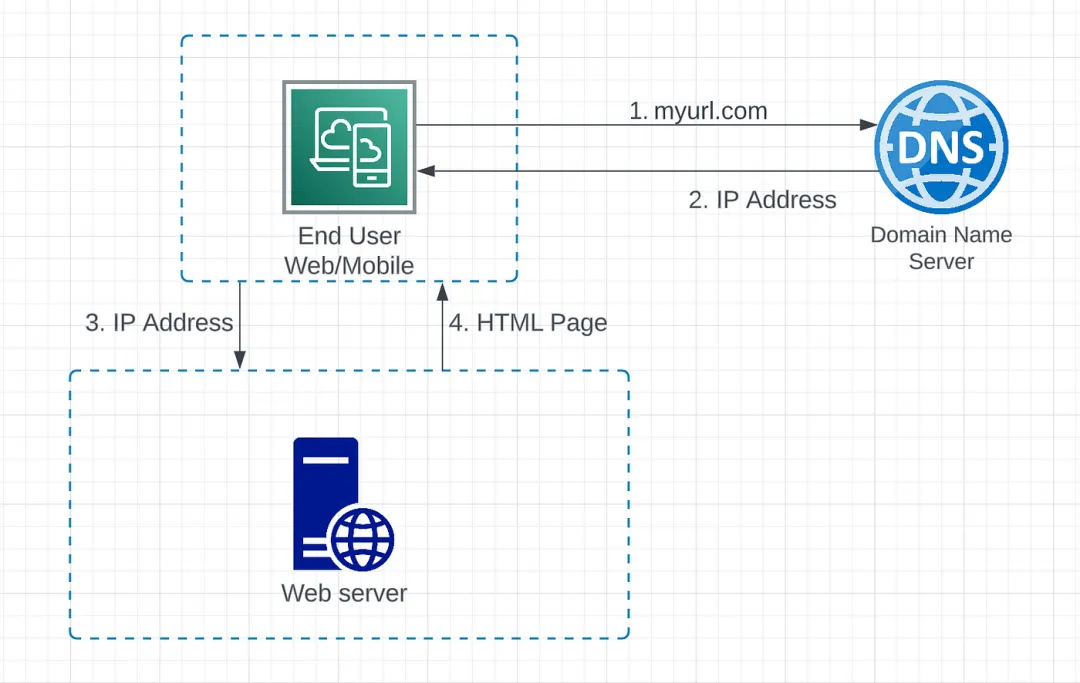
图1.1 请求流程
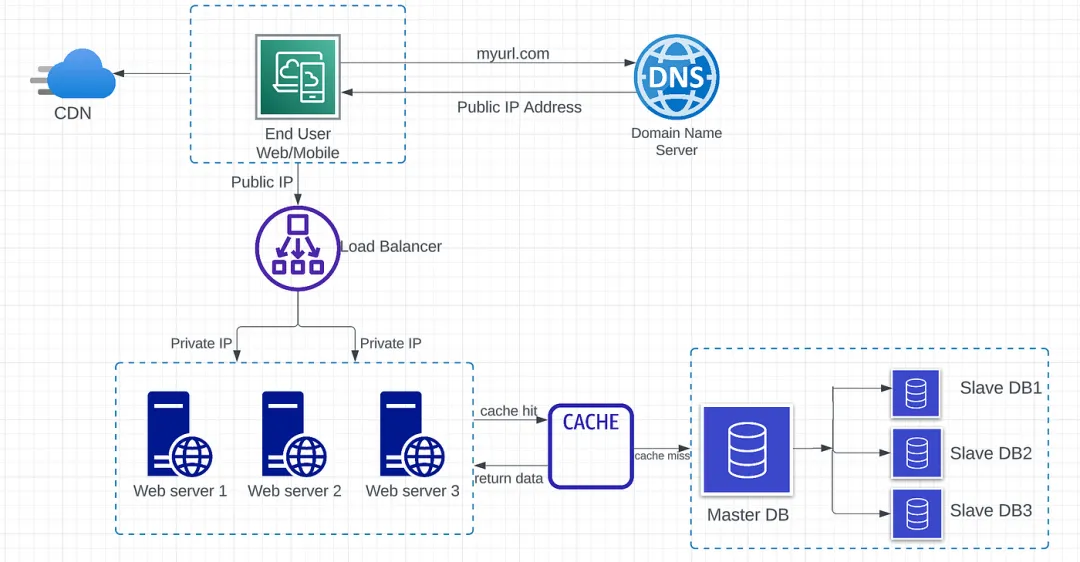
- 最终用户通过域名(myurl.com)访问网站。请求发送到 DNS,将域名映射到 IP 地址。
- IP 地址返回给网页浏览器或移动应用程序。
- HTTP 请求直接发送到 web 服务器。
- Web 服务器然后将请求的资源返回给客户端。在上图中,返回 HTML 页面进行渲染。
图中使用的组件定义如下:
- Web 服务器:一台能够通过互联网向最终用户提供网页内容的计算机系统。它包括网页服务器软件和网站组件文件,如 HTML 文档、图像、CSS 样式表、JavaScript 文件等。
- Web 客户端(Web/移动):用于通过 HTTP 连接到 Web 服务器的客户端应用程序。通常是一个网页浏览器或 Web 应用程序,用于显示从服务器接收的网页并允许用户与 Web 服务器进行交互。
- 域名系统(DNS):充当互联网的电话簿。人们通过域名(google.com)访问信息,但 Web 服务器使用互联网协议(IP)地址进行交互。DNS 将域名转换为 IP 地址,以便浏览器可以加载互联网资源。互联网中的每个设备都有唯一的 IP 地址,其他机器使用该地址查找设备。通常,DNS 是由第三方提供的付费服务,不由 Web 服务器托管。
将数据库与 Web 服务器分离
随着用户数量的增长,为了更独立地扩展,第一步是将数据库与 Web 服务器分离。
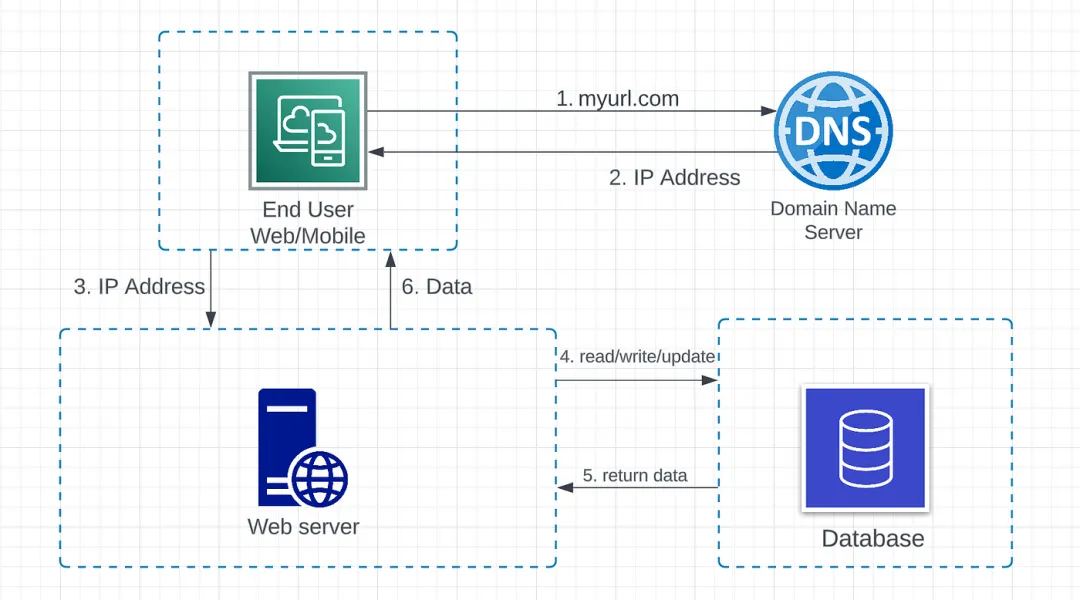
图1.2 请求流程
- 最终用户通过域名(myurl.com)访问网站。请求发送到 DNS,将域名映射到 IP 地址。
- IP 地址返回给网页浏览器或移动应用程序。
- HTTP 请求直接发送到 web 服务器。
- Web 服务器向数据库服务器发送请求,执行读取、写入或更新数据操作。
- 数据从数据库服务器返回到 web 服务器。
- 数据在 web 服务器中处理,最终返回给 Web 客户端。
图中新增的组件定义如下:
- 数据库:存储在计算机系统中的结构化或非结构化信息集合。数据库的选择取决于存储的信息类型。数据库可以从传统关系型数据库到非关系型数据库等各种类型。
- 传统关系型数据库:以表、行和列的方式结构化信息。关系型数据库能够通过连接表之间的关系来建立链接,这使得理解和获取有关各种数据点关系的见解变得容易。常见的传统数据库有 MySQL、Oracle 数据库、PostgreSQL 等。
- 非关系型数据库:也称为 NoSQL 数据库,使用针对存储的数据类型的特定要求进行优化的存储模型。它可以进一步分为多种不同的类别,如键值存储、图形存储、列存储、文档存储等。一些常见的例子包括 Cassandra、MongoDB、Neo4j 等。
扩展 Web 服务器
随着用户基数的增长和流量的增加,扩展 Web 服务器的能力变得至关重要。扩展的方式有两种,即垂直扩展和水平扩展。在垂直扩展中,通过向同一台服务器添加更多 CPU、RAM 等来“扩展”,而在水平扩展中,通过向资源池中添加更多服务器来“扩展”。尽管垂直扩展在性质上更加简单,但它也有自己的局限性。其中一些限制包括硬件限制(无法向单个服务器添加无限制的内存和 CPU),而且存在单点故障,这可能是一个巨大的缺点。因此,在大规模应用程序的情况下,使用水平扩展可能是更好的选择,通过负载均衡器将流量分布到多个服务器上。
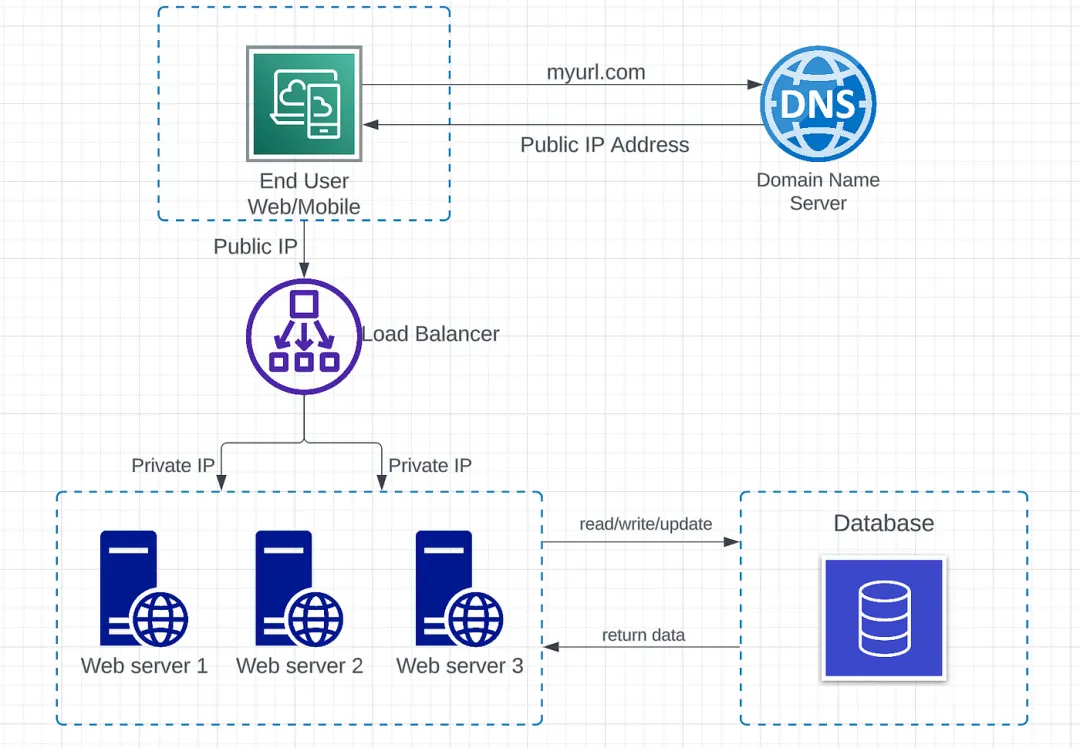
负载均衡器:负载均衡器充当流量管理器,位于服务器前面,将客户端请求路由到能够满足这些请求的所有服务器上,以最大化速度和容量利用率。负载均衡器的一些主要责任包括:
- 高效地将客户端请求或网络负载分布到多个服务器上。
- 仅将请求发送到在线的服务器,确保高可用性和可靠性。
- 根据需求灵活添加或移除服务器。
用户直接连接到负载均衡器的公共 IP。在此架构中,无法使用公共 IP 访问 Web 服务器。负载均衡器使用私有 IP 与不同的服务器进行通信。私有 IP 仅用于在同一网络内进行通信。
一些常见的负载均衡算法:
- 轮询法(Round Robin)— 顺序分发请求。
- 最少连接法(Least Connections)— 发送到当前连接最少的服务器。
- 最少时间法(Least Time)— 发送到响应最快且连接最少的服务器。
- 哈希法(Hash)— 根据您定义的键(如客户端 IP 地址、URL 等)进行分发。
数据可用性和复制
扩展的最关键方面之一是增强数据的可用性和可靠性。数据复制是实现这一目标的重要方式,它通过在不同服务器上创建和维护数据库的副本来实现。
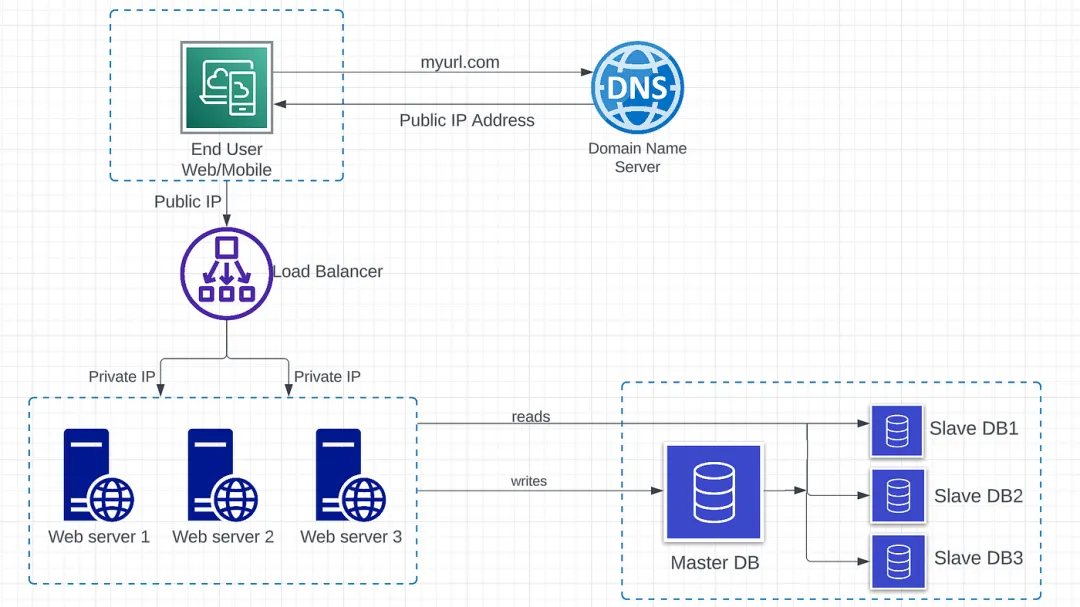
在图1.4中,我们可以看到原始(主)数据库和副本(从)数据库之间的主从关系。
- 主数据库:仅支持来自 Web 服务器的写入操作。所有修改数据的操作,如插入、删除、更新,都必须发送到主数据库。如果主数据库下线,一个从数据库将被提升为新的主数据库。
- 从数据库:仅支持来自 Web 服务器的读取操作。通常情况下,从数据库比主数据库多,因为读取和写入的比例总是更高。如果从数据库下线,一个新的从数据库将取代旧的从数据库。
数据复制的优势:
- 更好的性能 — 允许更多查询并行处理。
- 可靠性 — 数据在多个服务器上复制。我们不需要担心数据丢失。
- 高可用性 — 如果一个数据服务器下线,您可以从另一个数据库访问存储的数据。
一些其他常见的数据复制类型:
- 主-主复制 — 对任何主数据库进行的更改会复制到配置中的其他主数据库。
- 快照复制 — 在特定时间点创建整个数据库的副本,然后将快照复制到一个或多个目的地。
讨论了 Web 层和数据层之后,我们将简要介绍对改善负载/响应时间起着关键作用的两个其他概念:缓存和内容传递网络(CDN)。
缓存
缓存是一个临时存储区,用于在内存中存储昂贵响应的结果或频繁访问的数据。
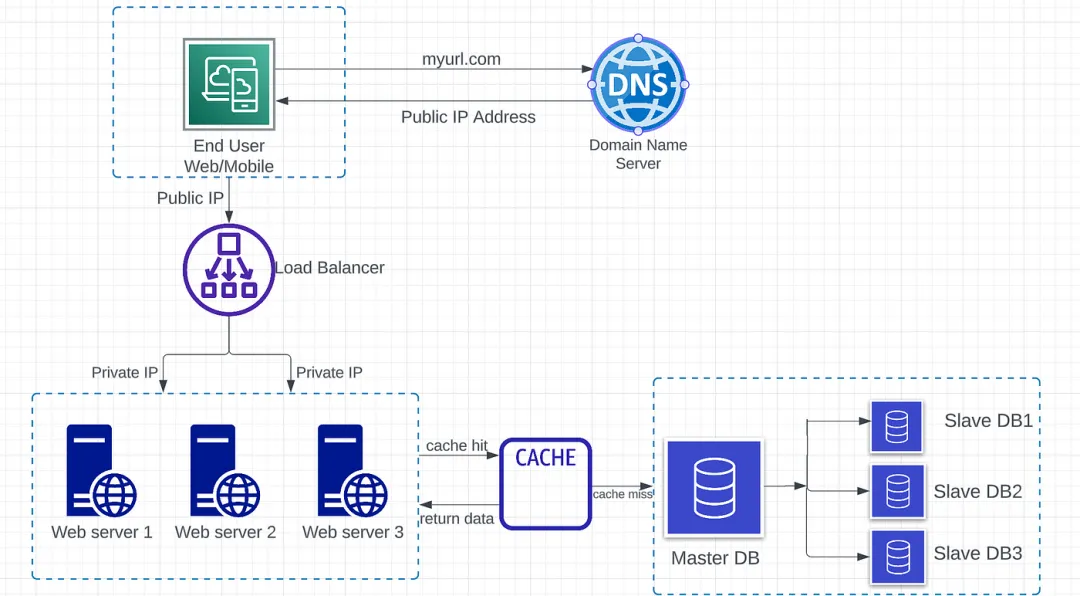
- 缓存命中 — Web 服务器从缓存中请求数据。如果数据存在于缓存中,则为缓存命中。在这种情况下,无需向数据库服务器发出网络调用。
- 缓存未命中 — Web 服务器从缓存中请求数据。如果缓存中不包含数据,则为缓存未命中。此时,需要从数据库获取数据,然后将数据保存到缓存中。
使用缓存的一些关键考虑因素:
- 数据读取频率高于修改频率。
- 实施良好的过期策略,这很重要,因为延迟的过期策略可能导致缓存中的数据过时,而频繁的过期策略可能会降低缓存的效果,因为这会导致频繁从数据库重新加载数据。
- 为了减少故障,请考虑添加多个缓存服务器,以避免单点故障。
- 必须有一个良好的驱逐策略。一旦缓存已满,为了添加新项目,现有项目应根据驱逐策略进行删除。
缓存的类型:
- 应用程序服务器缓存 — 缓存与应用程序服务器一起存储在内存中。在多 Web 服务器系统中,此架构中的一个缺点是,每个服务器将不知道已缓存请求,因此会产生大量的缓存未命中。
- 分布式缓存 — 每个节点将拥有整个缓存空间的一部分,然后使用一致性哈希函数将每个请求路由到可找到缓存请求的地方。
- 全局缓存 — 您将拥有单个缓存空间,所有节点都将使用此单个空间。
内容传递网络(CDN)
CDN 是一个由地理位置分散的服务器网络,用于传递静态内容,包括图像、视频、CSS、JavaScript 文件等。CDN 由像亚马逊、Akamai 等第三方提供商运行。
使用 CDN 的请求流程:
- 用户通过 URL 请求资源。这些 URL 是由 CDN 提供商提供的。
- 如果 CDN 缓存中没有资源,则从源(如亚马逊 S3)请求。
- 源然后将资源返回给 CDN 服务器。
- CDN 缓存资源并将其返回给用户。该图像将在 TTL(存活时间)过期之前保留在缓存中。
- 当另一个用户请求相同资源时,如果 TTL 尚未过期,则从缓存中获取。
总之,与用户规模的扩展不仅是技术上的挑战,更是现代数字系统的战略必需品。从设计弹性架构到实施有效的扩展策略,我们探讨了确保您的系统可以与用户需求无缝增长的关键要素。