Llama3是Meta提供的一个开源大模型,包含8B和 70B两种参数规模,涵盖预训练和指令调优的变体。这个开源模型推出已经有一段时间,并且在许多标准测试中展示了其卓越的性能。特别是Llama3 8B,其具备小尺寸和高质量的输出使其成为边缘设备或者移动设备上实现LLM的完美选择。但是Llama3也还有许多缺陷,因此,在场景应用中,有时候还需要对其进行微调,以提升中文能力、场景应用的专业度等。

目前有许多团队在做微调工具,他们的贡献提高了我们的效率、减少失误。比较优秀的例如:
- MLX-LM
- PyReft
- litgpt
- LLaMA-Factory
本文主要介绍如何使用这几个工具进行微调,以及如何在Ollama中安装运行微调后的模型。
一、MLX-LM
MLX团队一直在不懈地努力改进MLX-LM库在模型微调工具方面的能力。使用MLX-LM微调llama3十分简单。
可以参考相关例子:https://github.com/ml-explore/mlx-examples/tree/main/llms/llama
大致步骤如下:
1.准备训练数据
glaiveai/glaive-function-calling-v2是一个专门用于训练大语言模型处理函数调用方面的数据集。我们可以下载这个数据集,并将数据转换为适合Llama3对话的格式,并保存到"/data"目录下。
数据下载地址:https://huggingface.co/datasets/glaiveai/glaive-function-calling-v2
数据格式转换的脚本如下:
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments,BitsAndBytesConfig
from datasets import load_dataset
import json
model_name ="meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
dataset = load_dataset("glaiveai/glaive-function-calling-v2",split="train")
def cleanup(input_string):
arguments_index = input_string.find('"arguments"')
if arguments_index == -1:
return input_string
start_quote = input_string.find("'", arguments_index)
if start_quote == -1:
return input_string
end_quote = input_string.rfind("'")
if end_quote == -1 or end_quote <= start_quote:
return input_string
arguments_value = input_string[start_quote+1:end_quote]
output_string = input_string[:start_quote] + arguments_value + input_string[end_quote+1:]
return output_string
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example['system'])):
messages = [
{
"role": "system",
"content": example['system'][i][len("SYSTEM:"):].strip(),
},
]
conversations = example['chat'][i].split("<|endoftext|>")
for message in conversations:
continue_outer = False
message = message.strip()
if message:
if "USER:" in message:
user_content = message.split("ASSISTANT:")[0].strip()
messages.append({"role": "user", "content": user_content[5:].strip()})
if "ASSISTANT:" in message:
assistant_content = message.split("ASSISTANT:")[1].strip()
if "<functioncall>" in assistant_content:
text = assistant_content.replace("<functioncall>","").strip()
json_str = cleanup(text)
try:
data = json.loads(json_str)
except json.JSONDecodeError as e:
print(f"0 - Failed to decode JSON: {json_str} - {assistant_content}")
continue_outer = True
break
new_func_text = "<functioncall> "+ json_str
messages.append({"role": "assistant", "content": new_func_text})
else:
messages.append({"role": "assistant", "content": assistant_content})
elif message.startswith("FUNCTION RESPONSE:"):
function_response = message[18:].strip()
if "ASSISTANT:" in function_response:
function_content, assistant_content = function_response.split("ASSISTANT:")
try:
data = json.loads(function_content.strip())
except json.JSONDecodeError as e:
print(f"1 - Failed to decode JSON: {function_content}")
continue_outer = True
break
messages.append({"role": "user", "content": function_content.strip()})
messages.append({"role": "assistant", "content": assistant_content.strip()})
else:
try:
data = json.loads(function_response.strip())
except json.JSONDecodeError as e:
print(f"2 - Failed to decode JSON: {function_response}")
continue_outer = True
break
messages.append({"role": "user", "content": function_response.strip()})
elif message.startswith("ASSISTANT:"):
assistant_content = message.split("ASSISTANT:")[1].strip()
if "<functioncall>" in assistant_content:
text = assistant_content.replace("<functioncall>","").strip()
json_str = cleanup(text)
try:
data = json.loads(json_str)
except json.JSONDecodeError as e:
print(f"3 - Failed to decode JSON: {json_str} - {assistant_content}")
continue_outer = True
break
new_func_text = "<functioncall> "+ json_str
messages.append({"role": "assistant", "content": new_func_text})
if continue_outer:
continue
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)
output_texts.append(text)
del example['system']
del example['chat']
return {"text": output_texts}
dataset = dataset.map(formatting_prompts_func, batched=True)2.安装mlx-lm包
pip install mlx-lm这个库为微调LLM提供了一个友好的用户交互方式,省去了许多麻烦,并实现更好的效果。
3.创建LoRA配置
通过配置LoRA来微调Llama3 8B模型。更改一些关键参数以优化性能:
- 使用fp16代替qlora,以避免由于量化和解量化而导致的潜在性能下降。
- 将lora_layers设置为32,并使用全线性层,以获得与全微调相媲美的结果。
以下是lora_config.yaml文件的示例:
# The path to the local model directory or Hugging Face repo.
model: "meta-llama/Meta-Llama-3-8B-Instruct"
# Whether or not to train (boolean)
train: true
# Directory with {train, valid, test}.jsonl files
data: "data"
# The PRNG seed
seed: 0
# Number of layers to fine-tune
lora_layers: 32
# Minibatch size.
batch_size: 1
# Iterations to train for.
iters: 6000
# Number of validation batches, -1 uses the entire validation set.
val_batches: 25
# Adam learning rate.
learning_rate: 1e-6
# Number of training steps between loss reporting.
steps_per_report: 10
# Number of training steps between validations.
steps_per_eval: 200
# Load path to resume training with the given adapter weights.
resume_adapter_file: null
# Save/load path for the trained adapter weights.
adapter_path: "adapters"
# Save the model every N iterations.
save_every: 1000
# Evaluate on the test set after training
test: false
# Number of test set batches, -1 uses the entire test set.
test_batches: 100
# Maximum sequence length.
max_seq_length: 8192
# Use gradient checkpointing to reduce memory use.
grad_checkpoint: true
# LoRA parameters can only be specified in a config file
lora_parameters:
# The layer keys to apply LoRA to.
# These will be applied for the last lora_layers
keys: ['mlp.gate_proj', 'mlp.down_proj', 'self_attn.q_proj', 'mlp.up_proj', 'self_attn.o_proj','self_attn.v_proj', 'self_attn.k_proj']
rank: 128
alpha: 256
scale: 10.0
dropout: 0.05
# Schedule can only be specified in a config file, uncomment to use.
# lr_schedule:
# name: cosine_decay
# warmup: 100 # 0 for no warmup
# warmup_init: 1e-7 # 0 if not specified
# arguments: [1e-6, 1000, 1e-7] # passed to scheduler4.执行微调
在数据准备和LoRA配置就绪后,就可以开始微调Llama3 8B了,只需要运行以下命令。
mlx_lm.lora --config lora_config.yaml5.模型融合发布
LoRa模型是无法单独完成推理的,需要和原生Llama结合才能运行。因为它freeze了原来的模型,单独加了一些层,后续的训练都在这些层上做,所以需要进行模型融合。
可以使用mlx_lm.fuse将训练过的适配器与原始的Llama3 8B模型以HF格式融合:
mlx_lm.fuse --model meta-llama/Meta-Llama-3-8B-Instruct二、PyReft
项目源码:https://github.com/stanfordnlp/pyreft
ReFT方法的出发点是基于干预模型可解释性的概念,该概念强调改变表示而不是权重。这个概念基于线性表示假设,该假设指出概念被编码在神经网络的线性子空间中。
PyReFT是一个基于ReFT方法的库,支持通过可训练的干预来调整内部语言模型的表示。PyReFT具有更少的微调参数和更强的鲁棒性,可以提高微调效率、降低微调成本,同时也为研究自适应参数的可解释性打开了大门。
PyReft支持:
- 微调发布在HuggingFace上任何预训练大模型
- 可配置ReFT超参数
- 轻松将微调后的结果分享到HuggingFace
1.安装依赖库
使用Pip安装最新版本的transformers以支持llama3。此外,还需要安装bitsandbytes库。
!pip install -q git+https://github.com/huggingface/transformers
!pip install -q bitsandbytes2.安装或导入pyreft
安装Pyreft库。如果已经安装则将导入pyreft。
try:
import pyreft
except ModuleNotFoundError:
!pip install git+https://github.com/stanfordnlp/pyreft.git3.加载模型
在加载模型之前需要确保登陆到huggingface,以便于访问Llama3模型,可以使用下面的代码片段:
from huggingface_hub import notebook_login
notebook_login()接下来就是设置用于训练的提示词模板。由于我们将使用基础模型,因此需要添加特殊的标记,以便模型能够学会停止并且不继续生成文本。下面的代码片段用于执行加载模型和标记器。
import torch, transformers, pyreft
device = "cuda"
prompt_no_input_template = """<|begin_of_text|><|start_header_id|>user<|end_header_id|>%s<|eot_id|><|start_header_id|>assistant<|end_header_id|>"""
model_name_or_path = "meta-llama/Meta-Llama-3-8B"
model = transformers.AutoModelForCausalLM.from_pretrained(
model_name_or_path, torch_dtype=torch.bfloat16, device_map=device, trust_remote_code=True)
# # get tokenizer
tokenizer = transformers.AutoTokenizer.from_pretrained(
model_name_or_path, model_max_length=2048,
padding_side="right", use_fast=False)
tokenizer.pad_token = tokenizer.eos_token接着,设置pyreft配置,然后使用pyreft.get_reft_model()方法准备好模型。
# get reft model
reft_config = pyreft.ReftConfig(representations={
"layer": 8, "component": "block_output",
"low_rank_dimension": 4,
"intervention": pyreft.LoreftIntervention(embed_dim=model.config.hidden_size,
low_rank_dimension=4)})
reft_model = pyreft.get_reft_model(model, reft_config)
reft_model.set_device("cuda")
reft_model.print_trainable_parameters()4.准备数据集
下面以OpenHermes—2.5数据集为例。由于Reft Trainer的数据需要采用特定格式,因此我们使用:
pyreft.make_last_position_supervised_data_module()来准备数据。
dataset_name = "teknium/OpenHermes-2.5"
from datasets import load_dataset
dataset = load_dataset(dataset_name, split="train")
dataset = dataset.select(range(10_000))
data_module = pyreft.make_last_position_supervised_data_module(
tokenizer, model, [prompt_no_input_template % row["conversations"][0]["value"] for row in dataset],
[row["conversations"][1]["value"] for row in dataset])5.执行训练
为pyreft.ReftTrainerForCausalLM()设置训练参数。可以根据自己的使用情况和计算资源进行更改。下面的代码参数设置只训练1个epoch。
# train
training_args = transformers.TrainingArguments(
per_device_train_batch_size = 4,
gradient_accumulation_steps = 8,
warmup_steps = 100,
num_train_epochs = 1,
learning_rate = 5e-4,
bf16 = True,
logging_steps = 1,
optim = "paged_adamw_32bit",
weight_decay = 0.0,
lr_scheduler_type = "cosine",
output_dir = "outputs",
report_to=[]
)
trainer = pyreft.ReftTrainerForCausalLM(model=reft_model, tokenizer=tokenizer, args=training_args, **data_module)
_ = trainer.train()训练完成后,将干预块保存到reft_to_share目录中。
reft_model.save(
save_directory="./reft_to_share",
)6.发布与推理
模型微调训练完成后要进行推理。需要加载基本模型,并通过合并干预块来准备reft模型。然后将reft模型转移到cuda。
import torch, transformers, pyreft
device = "cuda"
model_name_or_path = "meta-llama/Meta-Llama-3-8B"
model = transformers.AutoModelForCausalLM.from_pretrained(
model_name_or_path, torch_dtype=torch.bfloat16, device_map=device)
reft_model = pyreft.ReftModel.load(
"Syed-Hasan-8503/Llama-3-openhermes-reft", model, from_huggingface_hub=True
)
reft_model.set_device("cuda")接着进行推理测试:
instruction = "A rectangular garden has a length of 25 feet and a width of 15 feet. If you want to build a fence around the entire garden, how many feet of fencing will you need?"
# tokenize and prepare the input
prompt = prompt_no_input_template % instruction
prompt = tokenizer(prompt, return_tensors="pt").to(device)
base_unit_location = prompt["input_ids"].shape[-1] - 1 # last position
_, reft_response = reft_model.generate(
prompt, unit_locations={"sources->base": (None, [[[base_unit_location]]])},
intervene_on_prompt=True, max_new_tokens=512, do_sample=True,
eos_token_id=tokenizer.eos_token_id, early_stopping=True
)
print(tokenizer.decode(reft_response[0], skip_special_tokens=True))三、litgpt
源代码:https://github.com/Lightning-AI/litgpt

LitGPT是一个可以用于微调预训练模型的命令行工具,支持20多个LLM的评估、部署。它为世界上最强大的开源大型语言模型(LLM)提供了高度优化的训练配方。
1.安装
pip install 'litgpt[all]'2.评估测试
选择一个模型并执行:下载、对话、微调、预训练以及部署等。
# ligpt [action] [model]
litgpt download meta-llama/Meta-Llama-3-8B-Instruct
litgpt chat meta-llama/Meta-Llama-3-8B-Instruct
litgpt finetune meta-llama/Meta-Llama-3-8B-Instruct
litgpt pretrain meta-llama/Meta-Llama-3-8B-Instruct
litgpt serve meta-llama/Meta-Llama-3-8B-Instruct例如:使用微软的phi-2进行对话评估。
# 1) Download a pretrained model
litgpt download --repo_id microsoft/phi-2
# 2) Chat with the model
litgpt chat \
--checkpoint_dir checkpoints/microsoft/phi-2
>> Prompt: What do Llamas eat?3.微调模型
下面是在phi-2基础上进行微调的命令。
# 1) Download a pretrained model
litgpt download --repo_id microsoft/phi-2
# 2) Finetune the model
curl -L https://huggingface.co/datasets/ksaw008/finance_alpaca/resolve/main/finance_alpaca.json -o my_custom_dataset.json
litgpt finetune \
--checkpoint_dir checkpoints/microsoft/phi-2 \
--data JSON \
--data.json_path my_custom_dataset.json \
--data.val_split_fraction 0.1 \
--out_dir out/custom-model
# 3) Chat with the model
litgpt chat \
--checkpoint_dir out/custom-model/final除此外,还可以基于自己的数据进行训练。详细参考GitHub。
4.部署
通过下面的部署命令,启动模型服务。
# locate the checkpoint to your finetuned or pretrained model and call the `serve` command:
litgpt serve --checkpoint_dir path/to/your/checkpoint/microsoft/phi-2
# Alternative: if you haven't finetuned, download any checkpoint to deploy it:
litgpt download --repo_id microsoft/phi-2
litgpt serve --checkpoint_dir checkpoints/microsoft/phi-2通过Http API访问服务。
# Use the server (in a separate session)
import requests, json
response = requests.post(
"http://127.0.0.1:8000/predict",
json={"prompt": "Fix typos in the following sentence: Exampel input"}
)
print(response.json()["output"])四、LLaMA-Factory
源代码:https://github.com/hiyouga/LLaMA-Factory/

LLaMA-Factory 是一个开源项目,它提供了一套全面的工具和脚本,用于微调、部署和基准测试LLaMA模型。
LLaMA-Factory 提供以下功能,使得我们可以轻松地使用LLaMA模型:
- 数据预处理和标记化的脚本
- 用于微调 LLaMA 模型的训练流程
- 使用经过训练的模型生成文本的推理脚本
- 评估模型性能的基准测试工具
- 用于交互式测试的 Gradio Web UI
使用LLaMA-Factory 进行微调的步骤如下:
1.数据准备
LLaMA-Factory要求训练数据的格式如下:
[
{
"instruction": "What is the capital of France?",
"input": "",
"output": "Paris is the capital of France."
},
...
]每个 JSON 对象代表一个训练示例,其中包含以下字段:
- instruction:任务指令或提示
- input:任务的附加上下文(可以为空)
- output:目标完成或响应
2.下载安装依赖包
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -r requirements.txt3.执行微调
支持使用Python进行微调也支持图形化界面的方式。
下面是执行python脚本进行微调:
python finetune.py \
--model_name llama-7b \
--data_path data/alpaca_data_tokenized.json \
--output_dir output/llama-7b-alpaca \
--num_train_epochs 3 \
--batch_size 128 \
--learning_rate 2e-5 \
--fp16该脚本将加载预训练的LLaMA模型,准备训练数据集,并使用指定的超参数运行微调脚步。微调后的模型检查点将保存在 中output_dir。
主要参数设置如下:
- model_name:要微调的基础 LLaMA 模型,例如llama-7b
- data_path:标记数据集的路径
- output_dir:保存微调模型的目录
- num_train_epochs:训练周期数
- batch_size:训练的批次大小
- learning_rate:优化器的学习率
- fp16:使用 FP16 混合精度来减少内存使用量
接着使用微调后的结果进行推理测试:
python generate.py \
--model_path output/llama-7b-alpaca \
--prompt "What is the capital of France?"当然,微调过程也可以在可视化界面上进行。首先需要启动GUI界面。
python web_ui.py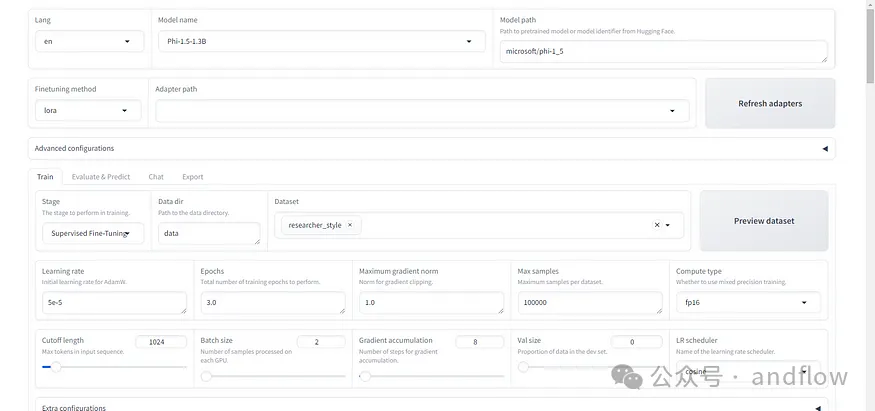
4.基准测试
LLaMA-Factory 包含了基于各种评估数据集进行基准测试的脚本:
benchmark.py例如:
python benchmark.py \
--model_path output/llama-7b-alpaca \
--benchmark_datasets alpaca,hellaswag这个Python命令将加载经过微调的模型并评估其在指定方面的表现。
benchmark_datasets参数指明使用哪些数据集进行评估。评估报告包括:准确度、困惑度和 F1分数等指标。
还可以使用DatasetBuilder实现一个类并将其注册到基准脚本来添加您自己的评估数据集。
如何在Ollama中安装微调后的Llama3模型?
Ollama 是一个开源的大模型管理工具,它提供了丰富的功能,包括模型的训练、部署、监控等。通过Ollama,可以轻松地管理本地的大模型,提高模型的训练速度和部署效率。Ollama支持多种机器学习框架,如TensorFlow、PyTorch等,因此,我们可以根据需要选择合适的框架进行模型训练。
在使用LLaMA-Factory进行微调之后,会生成LoRA文件,如何在Ollama中运行llama3和我们训练出来的LoRA呢?
步骤如下:
1.运行Ollama
直接安装或者通过Docker安装运行Ollama
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama2.GGML格式转换
按照 Ollama modelfile ADAPTER 的说明,Ollama 支持 ggml 格式的 LoRA,所以我们需要把微调生成的 LoRA 转换成ggml格式。为此,我们需要使用到 Llama.cpp 的格式转换脚本:“conver-lora-to-ggml.py”。
例如:
./conver-lora-to-ggml.py /output/llama3_cn_01 llama执行完命令后,将在 /output/llama3_cn_01 下生成 ggml-adapter-model.bin 文件。这个文件就是 Ollama 所需要的ggml格式LoRA文件。
3.在Ollama中创建自定义Llama3模型
使用 ollama 的 modelfile 来创建自定义llama3模型。需要创建一个modefile文件。
我们创建一个llama3.modelfile,其内容如下:
# set the base model
FROM llama3:8b
# set custom parameter values
PARAMETER temperature 1
PARAMETER num_keep 24
PARAMETER stop <|start_header_id|>
PARAMETER stop <|end_header_id|>
PARAMETER stop <|eot_id|>
PARAMETER stop <|reserved_special_token
# set the model template
TEMPLATE """
{{ if .System }}<|
start_header_id
|>system<|
end_header_id
|>
{{ .System }}<|
eot_id
|>{{ end }}{{ if .Prompt }}<|
start_header_id
|>user<|
end_header_id
|>
{{ .Prompt }}<|
eot_id
|>{{ end }}<|
start_header_id
|>assistant<|
end_header_id
|>
{{ .Response }}<|
eot_id
|>
"""
# set the system message
SYSTEM You are llama3 from Meta, customized and hosted @ HY's Blog (https://blog.yanghong.dev).
# set Chinese lora support
ADAPTER /root/.ollama/models/lora/ggml-adapter-model.bin接着使用Ollama命令以及modelfile来创建自定义模型:
ollama create llama3:c01 -f llama3.modelfile查看模型列表:
ollama list运行模型:
ollama run llama3:c01