共享内存处理起来有些棘手,因为它被存储(banked)在 32 个独立的内存存储中。如果不小心,这可能会导致所谓的 bank 冲突,即同一内存 bank 被要求同时提供多个不同的内存片段,导致请求被串行化,这可能会不成比例地减慢内核的速度 - 而 wgmma 和 mma 指令所需的寄存器布局会受到这些 bank 冲突的影响。解决方法是使用各种交错模式重新排列共享内存,以避免这些冲突。
#define NUM_WORKERS16// This kernel uses 16 workers in parallel per block, to help issue instructions more quickly.
using namespace kittens;// this kernel only handles headdim=64 for simplicity. Also n should be a multiple of 256 here.
__global__ voidattend_ker64(int n,const bf16* __restrict__ __q__,const bf16* __restrict__ __k__,const bf16* __restrict__ __v__, bf16* __o__){
auto warpid = kittens::warpid();
auto block_start = blockIdx.x*(n*64);const bf16 *_q = __q__ + block_start,*_k = __k__ + block_start,*_v = __v__ + block_start;
bf16 *_o = __o__ + block_start;
extern __shared__ alignment_dummy __shm[];// this is the CUDA shared memory
shared_allocator al((int*)&__shm[0]);// K and V live in shared memory -- this is about all that will fit.
st_bf_1x4<ducks::st_layout::swizzle>(&k_smem)[NUM_WORKERS]= al.allocate<st_bf_1x4<ducks::st_layout::swizzle>,NUM_WORKERS>();
st_bf_1x4<ducks::st_layout::swizzle>(&v_smem)[NUM_WORKERS]= al.allocate<st_bf_1x4<ducks::st_layout::swizzle>,NUM_WORKERS>();// Initialize all of the register tiles.
rt_bf_1x4<> q_reg, k_reg, v_reg;// v_reg need to be swapped into col_l
rt_fl_1x1<> att_block;
rt_bf_1x1<> att_block_mma;
rt_fl_1x4<> o_reg;
rt_fl_1x1<>::col_vec max_vec_last, max_vec;// these are column vectors for the attention block
rt_fl_1x1<>::col_vec norm_vec_last, norm_vec;// these are column vectors for the attention block
int qo_blocks = n /(q_reg.rows*NUM_WORKERS), kv_blocks = n /(q_reg.rows*NUM_WORKERS);for(auto q_blk =0; q_blk < qo_blocks; q_blk++){// each warp loads its own Q tile of 16x64, and then multiplies by 1/sqrt(d)load(q_reg, _q +(q_blk*NUM_WORKERS+ warpid)*q_reg.num_elements, q_reg.cols);mul(q_reg, q_reg,__float2bfloat16(0.125f));// temperature adjustment// zero flash attention L, M, and O registers.neg_infty(max_vec);// zero registers for the Q chunkzero(norm_vec);zero(o_reg);// iterate over k, v for these q's that have been loadedfor(auto kv_idx =0; kv_idx < kv_blocks; kv_idx++){// each warp loads its own chunk of k, v into shared memoryload(v_smem[warpid], _v +(kv_idx*NUM_WORKERS+ warpid)*q_reg.num_elements, q_reg.cols);load(k_smem[warpid], _k +(kv_idx*NUM_WORKERS+ warpid)*q_reg.num_elements, q_reg.cols);__syncthreads();// we need to make sure all memory is loaded before we can begin the compute phase// now each warp goes through all of the subtiles, loads them, and then does the flash attention internal alg.for(int subtile =0; subtile <NUM_WORKERS; subtile++){load(k_reg, k_smem[subtile]);// load k from shared into registerszero(att_block);// zero 16x16 attention tilemma_ABt(att_block, q_reg, k_reg, att_block);// Q@K.Tcopy(norm_vec_last, norm_vec);copy(max_vec_last, max_vec);row_max(max_vec, att_block, max_vec);// accumulate onto the max_vecsub_row(att_block, att_block, max_vec);// subtract max from attention -- now all <=0exp(att_block, att_block);// exponentiate the block in-place.sub(max_vec_last, max_vec_last, max_vec);// subtract new max from old max to find the new normalization.exp(max_vec_last, max_vec_last);// exponentiate this vector -- this is what we need to normalize by.mul(norm_vec, norm_vec, max_vec_last);// and the norm vec is now normalized.row_sum(norm_vec, att_block, norm_vec);// accumulate the new attention block onto the now-rescaled norm_vecdiv_row(att_block, att_block, norm_vec);// now the attention block is correctly normalizedmul(norm_vec_last, norm_vec_last, max_vec_last);// normalize the previous norm vec according to the new maxdiv(norm_vec_last, norm_vec_last, norm_vec);// normalize the previous norm vec according to the new normcopy(att_block_mma, att_block);// convert to bf16 for mma_ABload(v_reg, v_smem[subtile]);// load v from shared into registers.
rt_bf_1x4<ducks::rt_layout::col>&v_reg_col =swap_layout_inplace(v_reg);// this is a reference and the call has invalidated v_regmul_row(o_reg, o_reg, norm_vec_last);// normalize o_reg in advance of mma_AB'ing onto itmma_AB(o_reg, att_block_mma, v_reg_col, o_reg);// mfma onto o_reg with the local attention@V matmul.}__syncthreads();// we need to make sure all warps are done before we can start loading the next kv chunk}store(_o +(q_blk*NUM_WORKERS+ warpid)*q_reg.num_elements, o_reg, q_reg.cols);// write out o. compiler has an issue with register usage if d is made constexpr q_reg.rows :/}}
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
69.
70.
71.
72.
73.
74.
75.
76.
77.
78.
79.
80.
81.
82.
83.
84.
85.
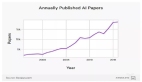
总共大约有 60 行 CUDA 代码,硬件利用率为 75%,虽然非常密集,但大部分复杂性在于算法,而不是混合模式或寄存器布局。














 图片
图片 图片
图片 图片
图片 图片
图片 图片
图片 图片
图片 图片
图片