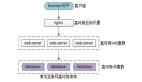
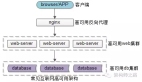
在分析互联网业务发展的特点时,我们注意到一个明显的趋势:系统的复杂性不断增加。这种复杂性主要体现在系统数量的增加以及不同系统由不同团队开发。如果各团队采用不同的开发框架和技术,会引发诸多问题,如技术人员间缺乏共同语言、技术掌握需要大量人力资源、团队间人员流动困难等。
为了解决这些问题,互联网公司通常会选择统一的技术方向和开发框架。例如,Java领域的SSH、SpringMVC、Play,Ruby的Ruby on Rails,PHP的ThinkPHP,以及Python的Django等。这种做法不仅提升了团队的协作效率,也优化了组织资源的配置。
在选择框架时,通行的原则是优先考虑成熟的框架,避免盲目追新。成熟的框架有几个明显优点:首先,文档资料完善,大部分问题都能通过搜索解决;其次,由于使用者众多,招聘时也更易找到合适的人才;最后,成熟的框架通常更稳定,适合长期使用,这对企业的持续发展非常重要。
Web 服务器
开发框架虽然关键于业务功能的实现,但要让这些功能真正运作并服务于用户,服务器的角色是不可或缺的。
考虑到开发一个成熟的 Web 服务器所需的高昂成本,以及市场上已有众多成熟的开源 Web 服务器,互联网行业普遍采用现成的解决方案。这意味着选择一个流行的开源服务器通常足以满足需求。大型公司可能会根据自己的业务需求对开源服务器进行二次开发,如淘宝开发的 Tengine,但大多数公司只需深入理解开源服务器的机制,并通过优化设置和调整配置来满足业务需求。
选择服务器时,需要考虑到开发语言的兼容性。例如,Java通常使用Tomcat、JBoss或Resin;而PHP和Python则常用Nginx。当然,选择Apache可以说是最保险的做法,因为它支持各种语言。
对于Apache的性能问题,实际上没有必要过早担心。一般来说,只有当业务规模扩大到Apache难以支持时,才需要考虑替换,那时候资源将更为充足,包括资金、人力和时间。
容器
近年来,容器技术尤其是Docker,已经在互联网行业中变得极为流行。例如,腾讯的Docker应用已经扩展到万台规模的实践,而新浪微博也在其红包服务中实施了大规模的Docker集群。
相比之下,传统的虚拟化技术如虚拟机,尽管解决了跨平台问题,但由于其庞大且启动慢,资源占用高的特性,其在互联网行业的应用并未广泛。Docker的容器技术虽不具备跨平台能力,但其快速启动和极低的资源占用使其迅速获得了广泛应用,容器技术被视为技术发展的未来主流。
Docker的影响远超传统的虚拟化或容器技术:
运维方式将彻底改变:Docker的快速启动和低资源占用特性,使得基于Docker的自动化和智能化运维将成为新的运维标准。
设计模式将发生根本变化:Docker低成本启动新容器的特性,将促进设计思维向“微服务”方向发展。例如,传统网站的登录、注册、页面访问和搜索等功能通常集成于一体。引入容器技术后,这些功能可以从一开始就以服务化的方式进行设计,从而避免随着访问量增大而需要对系统进行重构的问题。
服务层技术
随着互联网业务的持续发展,业务系统的数量和复杂度呈现上升趋势。例如,为了支持一个A业务系统的运行,可能需要与B、C、D、E等多达十几个其他系统进行协作。从数学角度看,系统间的依赖关系呈指数级增长。例如,3个系统之间可能存在3条相互关联的路径,而6个系统之间则有15条路径。
服务层的核心目标是减少这些系统间的复杂度。以下是配置中心的主要优点和功能:
- 集中管理配置:
- 当系统数量较少时,各个系统通常独立管理自己的配置。但随着系统数量的增加,这种分散管理方式可能导致上线新功能或处理线上问题时效率低下,因为这需要多个系统的协作以及大量的配置检查和沟通协调。
- 个别系统独立管理配置时,通常通过文本编辑器进行修改,这样容易发生错误,例如将IP地址中的数字0误输入为字母O,这类错误肉眼难以识别,但通过程序检查则相对容易发现。
- 配置中心的实现目的:
- 实现配置中心主要是为了解决上述问题,提高操作效率,并使所有配置集中在一个地方,便于检查和协作。
- 配置中心还可以通过程序化规则(如正则表达式)进行检查,有效避免常见的配置错误,比如检查数值范围、IP地址、URL地址等。
- 配置的备份与恢复:
- 配置中心不仅作为配置的集中地,还相当于对系统配置的一种备份。在遇到硬件故障如整机磁盘损坏或主板故障时,如果没有配置中心,恢复工作将非常耗时且容易出错,需要逐个通过Vim等工具编辑配置文件。有了配置中心,可以迅速搭建新环境并恢复业务运行。
通过配置中心,互联网公司能够有效应对日益增长的系统复杂性,提升整体运维效率。
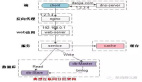
下面是配置中心简单的设计,其中通过“系统标识 + host + port”来标识唯一一个系统运行实例是常见的设计方法。
 图片
图片
服务中心
当系统数量较少时,系统间的互相调用通常是直接在各自系统的配置文件中记录的。但随着系统数量的增加,这种直接配置的方法开始显现出其局限性。
例如,如果A系统开发了一个新的Y接口来替代现有的X接口,并且希望十个依赖于X接口的系统切换到Y接口,那么这涉及到的十个系统可能需要在几十甚至上百台机器上修改配置并重启,这个过程的效率非常低。
此外,如果A系统有20台机器,其中5台机器出现故障,其他系统如果通过域名访问A系统,在域名缓存失效之前,仍然可能访问到这些故障的机器。如果其他系统是通过IP地址来访问A系统,那么每当A系统增加或删除机器时,所有依赖的系统都需要在多台机器上同步这些更改,这种协调工作的负担也是巨大的。
为了解决跨系统依赖中的配置和调度问题,服务中心应运而生。服务中心的实现通常有两种形式:服务名字系统和服务总线系统。
服务名字系统(Service Name System)
这个概念类似于DNS(域名系统)。正如DNS的主要功能是将域名解析为IP地址,因为IP地址难以记忆,而域名相对容易记忆。服务名字系统的目的是将服务名称解析为“主机+端口+接口名称”。和DNS相似,服务名字系统的核心功能是解析,而实际的请求仍然由请求方发起。
基本的设计如下:

服务总线系统(Service Bus System)
看到这个翻译,相信你可能立刻联想到计算机的总线。没错,两者的本质也是基本类似的。
相比服务名字系统,服务总线系统更进一步了:由总线系统完成调用,服务请求方都不需要直接和服务提供方交互了。
基本的设计如下
 图片
图片
“服务名字系统”和“服务总线系统”简单对比如下表所示。
 图片
图片
消息队列
互联网业务的一个特点是“快”,这就要求很多业务处理采用异步的方式。例如,大 V 发布一条微博后,系统需要发消息给关注的用户,我们不可能等到所有消息都发送给关注用户后再告诉大 V 说微博发布成功了,只能先让大 V 发布微博,然后再发消息给关注用户。
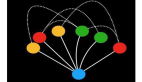
传统的异步通知方式是由消息生产者直接调用消息消费者提供的接口进行通知的,但当业务变得庞大,子系统数量增多时,这样做会导致系统间交互非常复杂和难以管理,因为系统间互相依赖和调用,整个系统的结构就像一张蜘蛛网,如下图所示。
 图片
图片
消息队列就是为了实现这种跨系统异步通知的中间件系统。消息队列既可以“一对一”通知,也可以“一对多”广播。以微博为例,可以清晰地看到异步通知的实现和作用,如下图所示
 图片
图片
对比之前的复杂的蜘蛛网架构,采用消息队列系统后的改变非常显著:
结构变化:原本的网状结构变为了更清晰的线性结构,使得整体架构更加条理化。
解耦生产与消费:消息的生产者与消费者之间实现了解耦,简化了实现过程。
扩展性提高:增加新的消费者时,对消息生产者没有任何影响,这大大便利了系统的扩展。
高性能与高可用性:消息队列系统能够实现高可用和高性能,减少了在各个子系统中重复建设的需要,从而降低了工作量。
业务集中:各个子系统可以集中精力于业务本身,简化了技术实现。
尽管消息队列的基础功能相对简单,但要实现高性能、高可用性、消息的时序性和事务性则较为复杂。市面上已有许多成熟的开源解决方案如RocketMQ、Kafka、ActiveMQ等,这些通常足以满足基本需求。然而,如果业务对消息的可靠性、顺序和事务性有更高要求,就需要深入了解并可能修改这些开源方案,以避免潜在的问题。
虽然开源方案使用方便,但一旦需要修改就可能变得复杂。因此,许多公司选择自行开发消息队列系统,这虽然重复了一些工作,但能更好地适应公司的具体业务需求,实现快速的定制开发。
今天我为你讲了互联网架构模板中的开发层和服务层技术,希望对你有所帮助。