












往期在文章《介绍Innodb的锁机制》中提到过关于记录锁,但是没有详细展开描述。本片文章简单聊一聊。
数据库的行级锁,随着锁的细粒度不同,拥有不同的命名。
- 记录锁(Record Lock)指的是对索引记录的锁定。
- 间隙锁(Gap Lock)则是对索引记录之间的间隙进行锁定。
而Next-Key Lock则是记录锁和间隙锁的融合,同时锁定索引记录和间隙。其范围为左开右闭。
什么是Record Lock
记录锁,即Record Lock,是针对索引记录而言的锁定。例如,执行以下语句:SELECT c1 FROM t WHERE c1 = 10 FOR UPDATE; 会对满足条件c1=10的记录进行锁定,以防止其他任何事务插入、更新或删除具有相同c1值的行。

什么是Gap Lock
间隙锁,即Gap Lock,指的是针对索引记录之间的间隙,或者是在第一个索引记录之前或最后一个索引记录之后的空隙上的锁定。
在这里,所谓的“间隙”是指InnoDB索引数据结构中可供插入新值的位置。
当你使用SELECT…FOR UPDATE语句锁定一组行时,InnoDB可以创建锁,应用于索引中的实际值以及它们之间的间隙。例如,如果你选择更新所有大于10的值,间隙锁将阻止另一个事务插入新的大于10的值。
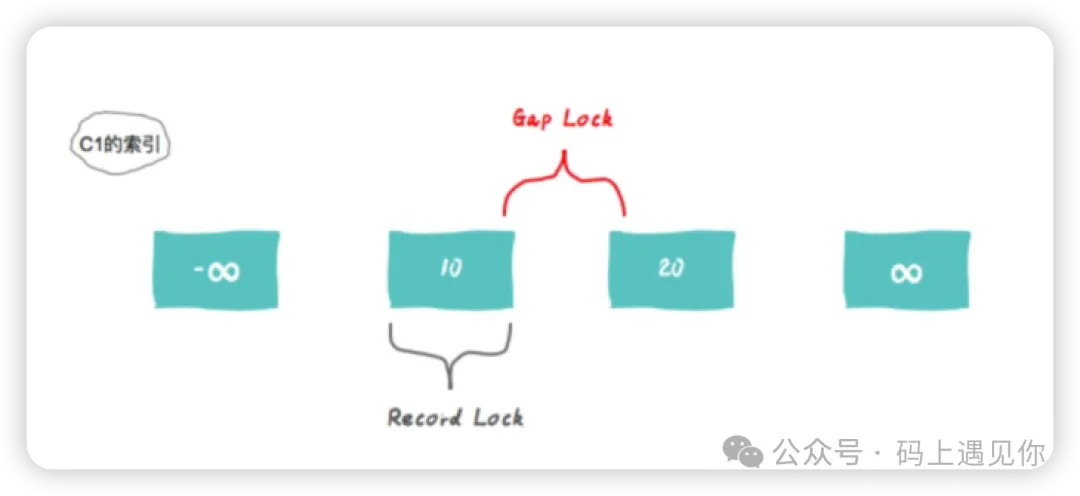
(实际会锁到+∞,这里为了演示什么是gap简化了一下)
由于锁的存在可能影响数据库的并发性,因此间隙锁只在Repeatable Reads(可重复读)这种隔离级别下才会发挥作用。
在Repeatable Reads隔离级别下,针对锁定的读操作(例如select ... for update、lock in share mode)、update操作和delete操作,会执行以下加锁操作:
- 对于具有唯一搜索条件的唯一索引,InnoDB仅锁定找到的索引记录,而不锁定间隙。
- 对于其他搜索条件,InnoDB会锁定扫描的索引范围,并使用间隙锁或next-key锁来阻止其他事务插入范围内的间隙。
换句话说,在处理**SELECT FOR UPDATE、LOCK IN SHARE MODE、UPDATE和DELETE**等语句时,除了对具有唯一搜索条件的唯一索引外,还会获取间隙锁或next-key锁,即锁定其扫描的范围。
什么是Next-Key Lock
Next-Key锁是指索引记录上的记录锁和索引记录之间间隙上的间隙锁的结合。

假设一个索引包含值10、11、13和20。此索引可能的next-key锁包括以下区间:
(-∞, 10]
(10, 11]
(11, 13]
(13, 20]
(20, ∞ ]对于最后一个间隙,∞并不是一个真正的索引记录,因此,实际上,这个next-key锁只锁定最大索引值之后的间隙。
因此,Next-Key锁的范围都是左开右闭的。
与Gap Lock一样,Next-Key Lock只有在InnoDB的可重复读(RR)隔离级别中才会生效。
谈谈MySQL加锁机制
根据丁奇大佬《MySQL实战45讲》中的总结,加锁规则可以归纳为两个“原则”、两个“优化”和一个“bug”:
- 原则 1:加锁的基本单位是next-key lock,形成一个前开后闭的区间。
- 原则 2:只有查找过程中访问到的对象才会被加锁。
- 优化 1:对于索引上的等值查询,当给唯一索引加锁时,next-key lock会退化为行锁。
- 优化 2:对于索引上的等值查询,在向右遍历时,且最后一个值不满足等值条件时,next-key lock会退化为间隙锁。
- 一个bug:唯一索引上的范围查询会一直访问到不满足条件的第一个值为止。
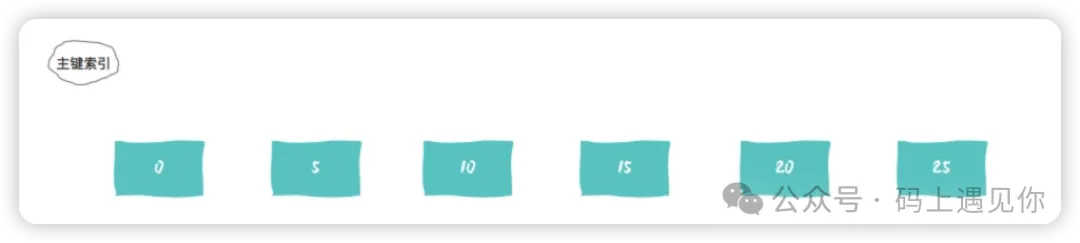
当我们执行update t set d=d+1 where id = 7的时候,由于表 t 中没有 id=7 的记录,所以:
- 根据原则 1,加锁单位是 next-key lock,session A 加锁范围就是 (5,10];
- 根据优化 2,这是一个等值查询 (id=7),而 id=10 不满足查询条件,next-key lock 退化成间隙锁,因此最终加锁的范围是 (5,10)。
当我们执行select * from t where id>=10 and id<11 for update的时候:
- 根据原则 1,加锁单位是 next-key lock,会给 (5,10]加上 next-key lock,范围查找就往后继续找,找到 id=15 这一行停下来
- 根据优化 1,主键 id 上的等值条件,退化成行锁,只加了 id=10 这一行的行锁。
- 根据原则 2,访问到的都要加锁,因此需要加 next-key lock(10,15]。因此最终加的是行锁 id=10 和 next-key lock(10,15]。
当执行 select * from t where id>10 and id<=15 for update 时:
- 根据原则 1,加锁单位是 next-key lock,会给 (10,15] 加上 next-key lock,并且由于 id 是唯一键,所以应该循环判断到 id=15 这一行就停止。
- 但是,InnoDB 实际上会往前扫描到第一个不满足条件的行,即 id=20。由于这是一个范围扫描,因此索引 id 上的 (15,20] 这个 next-key lock 也会被锁上。
假如,数据库表中当前有以下记录:
当执行 select id from t where c=5 lock in share mode 时:
- 根据原则 1,加锁单位是 next-key lock,因此会给 (0,5] 加上 next-key lock。需要注意的是,c 是普通索引,因此不能立即停止于 c=5 这一条记录,需要向右遍历,直到找到 c=10 才放弃。
- 根据原则 2,访问到的都要加锁,因此要给 (5,10] 加上 next-key lock。
- 根据优化 2:等值判断,向右遍历,最后一个值不满足 c=5 这个等值条件,因此退化成间隙锁 (5,10)。
- 根据原则 2,只有访问到的对象才会加锁。由于这个查询使用了覆盖索引,不需要访问主键索引,所以在主键索引上没有加任何锁。
当执行 select * from t where c>=10 and c<11 for update 时:
- 根据原则 1,加锁单位是 next-key lock,会给 (5,10] 加上 next-key lock,并继续向后查找,直到找到 id=15 这一行停止。
- 根据原则 2,访问到的都要加锁,因此需要加 next-key lock (10,15]。
- 由于索引 c 是非唯一索引,没有优化规则,也就是说不会退化为行锁,因此最终 session A 加的锁是,索引 c 上的 (5,10] 和 (10,15] 这两个 next-key lock。
结语
以上,我们介绍了InnoDB中的锁机制,一共有三种锁,分别是Record Lock、Gap Lock和Next-Key Lock。
Record Lock表示记录锁,锁的是索引记录。Gap Lock是间隙锁,说的是索引记录之间的间隙。Next-Key Lock是Record Lock和Gap Lock的组合,同时锁索引记录和间隙。他的范围是左开右闭的。
InnoDB的RR级别中,加锁的基本单位是 next-key lock,只要扫描到的数据都会加锁。唯一索引上的范围查询会访问到不满足条件的第一个值为止。
同时,为了提升性能和并发度,也有两个优化点:
- 索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁。
- 索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁。
关于锁的介绍,就是这么多了,但是其实,RR的隔离级别引入的这些锁,虽然一定程度上可解决很多如幻读这样的问题,但是也会带来一些副作用,比如并发度降低、容易导致死锁等。


















