先来唠唠
 图片
图片
今天刷脉脉的时候, 发现百度副总裁璩静一个人竟然占了前三的两个热榜, 对于她的离职你怎么看?
言归正传, 本文的重点还是分享面经干货
今天分享的是一位朋友在腾讯互娱的面经, 他本人目前已经是收到offer了, 让我们来看看这个难度如何:
 图片
图片
面试题详解
Go接口
接口在Golang中扮演着连接不同类型之间的桥梁,它定义了一组方法的集合,而不关心具体的实现。接口的作用主要体现在以下几个方面:
多态性:
接口允许不同的类型实现相同的方法,从而实现多态性。这意味着我们可以使用接口类型来处理不同的对象,而不需要关心具体的类型。
package main
import "fmt"
type Animal interface {
Sound() string
}
type Dog struct{}
func (d Dog) Sound() string {
return "Woof!"
}
type Cat struct{}
func (c Cat) Sound() string {
return "Meow!"
}
func main() {
animals := []Animal{Dog{}, Cat{}}
for _, animal := range animals {
fmt.Println(animal.Sound())
}
}在上面的示例中,我们定义了一个Animal接口,它包含了一个Sound()方法。然后,我们实现了Dog和Cat两个结构体,分别实现了Sound()方法。通过将Dog和Cat类型赋值给Animal接口类型,我们可以在循环中调用Sound()方法,而不需要关心具体的类型。这就体现了接口的多态性,不同的类型可以实现相同的接口方法。
解耦合:
接口可以将抽象与实现分离,降低代码之间的耦合度。通过定义接口,我们可以将实现细节隐藏起来,只暴露必要的方法,从而提高代码的可维护性和可读性。
package main
import "fmt"
type Printer interface {
Print(string)
}
type ConsolePrinter struct{}
func (cp ConsolePrinter) Print(message string) {
fmt.Println(message)
}
type FilePrinter struct{}
func (fp FilePrinter) Print(message string) {
// 将消息写入文件
fmt.Println("Writing message to file:", message)
}
func main() {
printer := ConsolePrinter{}
printer.Print("Hello, World!")
printer = FilePrinter{}
printer.Print("Hello, World!")
}在上面的示例中,我们定义了一个Printer接口,它包含了一个Print()方法。然后,我们实现了ConsolePrinter和FilePrinter两个结构体,分别实现了Print()方法。通过将不同的结构体赋值给Printer接口类型的变量,我们可以在主函数中调用Print()方法,而不需要关心具体的实现。这样,我们可以根据需要轻松地切换不同的打印方式,实现了解耦合。
可扩展性:
package main
import "fmt"
type Shape interface {
Area() float64
}
type Rectangle struct {
Width float64
Height float64
}
func (r Rectangle) Area() float64 {
return r.Width * r.Height
}
type Circle struct {
Radius float64
}
func (c Circle) Area() float64 {
return 3.14 * c.Radius * c.Radius
}
func main() {
shapes := []Shape{Rectangle{Width: 5, Height: 10}, Circle{Radius: 3}}
for _, shape := range shapes {
fmt.Println("Area:", shape.Area())
}
}在上面的示例中,我们定义了一个Shape接口,它包含了一个Area()方法。然后,我们实现了Rectangle和Circle两个结构体,分别实现了Area()方法。通过将不同的结构体赋值给Shape接口类型的切片,我们可以在循环中调用Area()方法,而不需要关心具体的类型。这样,当我们需要添加新的形状时,只需要实现Shape接口的Area()方法即可,而不需要修改已有的代码。这就实现了代码的可扩展性。
接口的应用场景
- API设计:接口在API设计中起到了至关重要的作用。通过定义接口,我们可以规范API的输入和输出,提高代码的可读性和可维护性。
- 单元测试:接口在单元测试中也扮演着重要的角色。通过使用接口,我们可以轻松地替换被测试对象的实现,从而实现对被测代码的独立测试。
- 插件系统:接口可以用于实现插件系统,通过定义一组接口,不同的插件可以实现这些接口,并在程序运行时动态加载和使用插件。
- 依赖注入:接口在依赖注入中也有广泛的应用。通过定义接口,我们可以将依赖对象的创建和管理交给外部容器,从而实现松耦合的代码结构。
空结构体的用途
不包含任何字段的结构体,就叫做空结构体。
空结构体的特点:
- 零内存占用
- 地址都相同
- 无状态
空结构体的使用场景
- 实现set集合
在 Go 语言中,虽然没有内置 Set 集合类型,但是我们可以利用 map 类型来实现一个 Set 集合。由于 map 的 key 具有唯一性,我们可以将元素存储为 key,而 value 没有实际作用,为了节省内存,我们可以使用空结构体作为 value 的值。
package main
import "fmt"
type Set[K comparable] map[K]struct{}
func (s Set[K]) Add(val K) {
s[val] = struct{}{}
}
func (s Set[K]) Remove(val K) {
delete(s, val)
}
func (s Set[K]) Contains(val K) bool {
_, ok := s[val]
return ok
}
func main() {
set := Set[string]{}
set.Add("程序员")
fmt.Println(set.Contains("程序员")) // true
set.Remove("程序员")
fmt.Println(set.Contains("程序员")) // false
}- 用于通道信号
空结构体常用于 Goroutine 之间的信号传递,尤其是不关心通道中传递的具体数据,只需要一个触发信号时。例如,我们可以使用空结构体通道来通知一个 Goroutine 停止工作:
package main
import (
"fmt"
"time"
)
func main() {
quit := make(chan struct{})
go func() {
// 模拟工作
fmt.Println("工作中...")
time.Sleep(3 * time.Second)
// 关闭退出信号
close(quit)
}()
// 阻塞,等待退出信号被关闭
<-quit
fmt.Println("已收到退出信号,退出中...")
}- 作为方法接收器
有时候我们需要创建一组方法集的实现(一般来说是实现一个接口),但并不需要在这个实现中存储任何数据,这种情况下,我们可以使用空结构体来实现:
type Person interface {
SayHello()
Sleep()
}
type CMY struct{}
func (c CMY) SayHello() {
fmt.Println("你好,世界。")
}
func (c CMY) Sleep() {
fmt.Println("晚安,世界...")
}Go原生支持默认参数或可选参数吗,如何实现
什么是默认参数
默认参数是指在函数调用时,如果没有提供某个参数的值,那么使用函数定义中指定的默认值。这种语言特性可以减少代码量,简化函数的使用。
在Go语言中,函数不支持默认参数。这意味着如果我们想要设置默认值,那么就需要手动在函数内部进行处理。
例如,下面是一个函数用于计算两个整数的和:
func Add(a int, b int) int {
return a + b
}如果我们希望b参数有一个默认值,例如为0,那么可以在函数内部进行处理:
func AddWithDefault(a int, b int) int {
if b == 0 {
b = 0
}
return a + b
}上面的代码中,如果b参数没有提供值,那么默认为0。通过这种方式,我们就实现了函数的默认参数功能。
需要注意的是,这种处理方式虽然可以实现默认参数的效果,但会增加代码复杂度和维护难度,因此在Go语言中不被推荐使用。
什么是可选参数
可选参数是指在函数调用时,可以省略一些参数的值,从而让函数更加灵活。这种语言特性可以让函数更加易用,提高代码的可读性。
在Go语言中,函数同样不支持可选参数。但是,我们可以使用可变参数来模拟可选参数的效果。
下面是一个函数用于计算任意个整数的和:
func Add(nums ...int) int {
sum := 0
for _, num := range nums {
sum += num
}
return sum
}上面的代码中,我们使用...int类型的可变参数来接收任意个整数,并在函数内部进行求和处理。
如果我们希望b和c参数为可选参数,那么可以将它们放到nums可变参数之后:
func AddWithOptional(a int, nums ...int) int {
sum := a
for _, num := range nums {
sum += num
}
return sum
}上面的代码中,我们首先将a参数赋值给sum变量,然后对可变参数进行求和处理。如果函数调用时省略了nums参数,则sum等于a的值。
需要注意的是,使用可变参数模拟可选参数的效果虽然能够实现函数的灵活性,但也会降低代码的可读性和规范性。因此在Go语言中不被推荐使用。
defer执行顺序
在 Go 中,defer 语句用于延迟(defer)函数的执行,通常用于在函数执行结束前执行一些清理或收尾工作。当函数中存在多个 defer 语句时,它们的执行顺序是“后进先出”(Last In First Out,LIFO)的,即最后一个被延迟的函数最先执行,倒数第二个被延迟的函数次之,以此类推。
在 Go 中,defer 语句中的函数在执行时会被压入一个栈中,当函数执行结束时,这些被延迟的函数会按照后进先出的顺序执行。这意味着在函数中的 defer 语句中的函数会在函数执行结束前执行,包括在 return 语句之前执行。
协程之间信息如何同步
协程(Goroutine)之间的信息同步通常通过通道(Channel)来实现。通道是 Go 语言中用于协程之间通信的重要机制,可以安全地在不同协程之间传递数据,实现协程之间的信息同步。
一些常见的方法来实现协程之间的信息同步:
- 使用无缓冲通道:无缓冲通道是一种同步通道,发送和接收操作会在数据准备好之前被阻塞。通过无缓冲通道,可以实现协程之间的同步通信,确保数据的正确传递。
- 使用带缓冲通道:带缓冲通道允许在通道中存储一定数量的元素,发送操作只有在通道已满时才会被阻塞。通过带缓冲通道,可以实现异步通信。
- 使用同步原语:Go 语言中的 sync 包提供了一些同步原语,如互斥锁(Mutex)、读写锁(RWMutex)等,可以用于协程之间的同步访问共享资源。
- 使用select语句:select 语句可以用于在多个通道操作中选择一个执行,可以实现协程之间的多路复用和超时控制。
- 使用context包:context 包提供了一种在协程之间传递取消信号和截止时间的机制,可以用于协程之间的协调和同步。
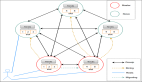
GMP模型
GM模型开销大的原因?
最开始的是GM模型没有 P 的,是M:N的两级线程模型,但是会出现一些性能问题:
- 全局队列的锁竞争。M从全局队列中添加或获取 G 的时候,都是需要上锁的(下图执行步骤要加锁),这样就会导致锁竞争,虽然达到了并发安全,但是性能是非常差的。
- M 转移 G 会有额外开销。M 在执行 G 的时候,假设 M1 执行的 G1 创建了 G2,新创建的就要放到全局队列中去,但是这时有一个空闲的 M2 获取到了 G2,那么这样 G1、G2 会被不同的 M 执行,但是 M1 中本来就有 G2 的信息,M2 在 G1 上执行是更好的,而且取和放到全局队列也会来回加锁,这样都会有一部分开销。
- 线程的使用效率不能最大化。M 拿不到的时候就会一直空闲,阻塞的时候也不会切换。也就是没有 workStealing 机制和 handOff 机制。
 图片
图片
GMP
 图片
图片
go生成一个协程,此时放在P中还是M中
如果在本地的队列中有足够的空间,则会直接进入本地队列等待M的执行;如果本地队列已经满了,则进入全局队列(在GMP模型中,所有的M都可以从全局队列中获取协程并执行)
G阻塞,M、P如何
当G因系统调用(syscall)阻塞时会阻塞M,此时P会和M解绑即hand off,并寻找新的idle的M,若没有idle的M就会新建一个M
Redis与MySQL数据如何同步
这里提供几种方案:
- 定时任务同步:编写定时任务或脚本,定期从 MySQL 中读取数据,然后将数据同步到 Redis 中。这种方案简单直接,适用于数据量不大且同步频率不高的场景。
- 使用消息队列:将 MySQL 中的数据变更操作(如新增、更新、删除)通过消息队列(如 RabbitMQ、Kafka)发送到消息队列中,然后消费者从消息队列中读取消息,将数据同步到 Redis 中。这种方案实现了异步同步,降低了对 MySQL 的压力。
- 使用数据库触发器:在 MySQL 中设置触发器,当数据发生变更时触发触发器,将变更信息发送到消息队列或直接同步到 Redis 中。这种方案可以实现实时同步,但需要谨慎设计触发器逻辑,避免影响数据库性能。
- 使用数据同步工具:可以使用一些数据同步工具(如 Maxwell、Debezium)来实现 MySQL 和 Redis 数据的实时同步。这些工具可以监控 MySQL 数据库的变更,并将变更数据同步到 Redis 中。
- 使用缓存库:一些缓存库(如 Redisson、Lettuce)提供了与 MySQL 数据库的集成,可以通过配置简单地实现 MySQL 数据到 Redis 的同步。
Explain的字段
explain的用法:
explain select * from gateway_apps;返回结果:
 图片
图片
下面对上面截图中的字段一一解释:
1、id:select 查询序列号。id相同,执行顺序由上至下;id不同,id值越大优先级越高,越先被执行。
2、select_type:查询数据的操作类型,其值如下:
- simple:简单查询,不包含子查询或 union
- primary:包含复杂的子查询,最外层查询标记为该值
- subquery:在 select 或 where 包含子查询,被标记为该值
- derived:在 from 列表中包含的子查询被标记为该值,MySQL 会递归执行这些子查询,把结果放在临时表
- union:若第二个 select 出现在 union 之后,则被标记为该值。若 union 包含在 from 的子查询中,外层 select 被标记为 derived
- union result:从 union 表获取结果的 select
3、table:显示该行数据是关于哪张表
4、partitions:匹配的分区
5、type:表的连接类型,其值,性能由高到底排列如下:
- system:表只有一行记录,相当于系统表
- const:通过索引一次就找到,只匹配一行数据
- eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常用于主键或唯一索引扫描
- ref:非唯一性索引扫描,返回匹配某个单独值的所有行。用于=、< 或 > 操作符带索引的列
- range:只检索给定范围的行,使用一个索引来选择行。一般使用between、>、<情况
- index:只遍历索引树
- ALL:全表扫描,性能最差
6、 possible_keys:显示 MySQL 理论上使用的索引,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用。如果该值为 NULL,说明没有使用索引,可以建立索引提高性能
7、key:显示 MySQL 实际使用的索引。如果为 NULL,则没有使用索引查询
8、key_len:表示索引中使用的字节数,通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好 显示的是索引字段的最大长度,并非实际使用长度
9、ref:显示该表的索引字段关联了哪张表的哪个字段
10、 rows:根据表统计信息及选用情况,大致估算出找到所需的记录或所需读取的行数,数值越小越好
11、filtered:返回结果的行数占读取行数的百分比,值越大越好
12、extra:包含不合适在其他列中显示但十分重要的额外信息,常见的值如下:
- using filesort:说明 MySQL 会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。出现该值,应该优化 SQL
- using temporary:使用了临时表保存中间结果,MySQL 在对查询结果排序时使用临时表。常见于排序 order by 和分组查询 group by。出现该值,应该优化 SQL
- using index:表示相应的 select 操作使用了覆盖索引,避免了访问表的数据行,效率不错
- using where:where 子句用于限制哪一行
- using join buffer:使用连接缓存
- distinct:发现第一个匹配后,停止为当前的行组合搜索更多的行
Redis过期删除策略
Redis 中提供了三种过期删除的策略
定时删除
在设置某个 key 的过期时间同时,我们创建一个定时器,让定时器在该过期时间到来时,立即执行对其进行删除的操作。
优点:
对 CPU 是友好的,只有在取出键值对的时候才会进行过期检查,这样就不会把 CPU 资源花费在其他无关紧要的键值对的过期删除上。
缺点:
如果一些键值对永远不会被再次用到,那么将不会被删除,最终会造成内存泄漏,无用的垃圾数据占用了大量的资源,但是服务器却不能去删除。
惰性删除
惰性删除,当一个键值对过期的时候,只有再次用到这个键值对的时候才去检查删除这个键值对,也就是如果用不着,这个键值对就会一直存在。
优点:
对 CPU 是友好的,只有在取出键值对的时候才会进行过期检查,这样就不会把 CPU 资源花费在其他无关紧要的键值对的过期删除上。
缺点:
如果一些键值对永远不会被再次用到,那么将不会被删除,最终会造成内存泄漏,无用的垃圾数据占用了大量的资源,但是服务器却不能去删除。
定期删除
定期删除是对上面两种删除策略的一种整合和折中
每个一段时间就对一些 key 进行采样检查,检查是否过期,如果过期就进行删除
1、采样一定个数的key,采样的个数可以进行配置,并将其中过期的 key 全部删除;
2、如果过期 key 的占比超过可接受的过期 key 的百分比,则重复删除的过程,直到过期key的比例降至可接受的过期 key 的百分比以下。
优点:
定期删除,通过控制定期删除执行的时长和频率,可以减少删除操作对 CPU 的影响,同时也能较少因过期键带来的内存的浪费。
缺点:
执行的频率不太好控制
频率过快对 CPU 不友好,如果过慢了就会对内存不太友好,过期的键值对不能及时的被删除掉
同时如果一个键值对过期了,但是没有被删除,这时候业务再次获取到这个键值对,那么就会获取到被删除的数据了,这肯定是不合理的。
Redis 中过期删除策略
上面讨论的三种策略,都有或多或少的问题。Redis 中实际采用的策略是惰性删除加定期删除的组合方式。
定期删除,获取 CPU 和 内存的使用平衡,针对过期的 KEY 可能得不到及时的删除,当 KEY 被再次获取的时候,通过惰性删除再做一次过期检查,来避免业务获取到过期内容。
Redis常用数据结构
Redis 共有 5 种基本数据类型:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
Zset使用场景, 具体实现
Zset的两种实现方式:
- ziplist:满足以下两个条件的时候
- 元素数量少于128的时候
- 每个元素的长度小于64字节
- skiplist:不满足上述两个条件就会使用跳表,具体来说是组合了map和skiplist
- map用来存储member到score的映射,这样就可以在O(1)时间内找到member对应的分数
- skiplist按从小到大的顺序存储分数
- skiplist每个元素的值都是[score,value]对
skiplist优势
skiplist本质上是并行的有序链表,但它克服了有序链表插入和查找性能不高的问题。它的插入和查询的时间复杂度都是O(logN)
skiplist原理
普通有序链表的插入需要一个一个向前查找是否可以插入,所以时间复杂度为O(N),比如下面这个链表插入23,就需要一直查找到22和26之间。
 图片
图片
如果节点能够跳过一些节点,连接到更靠后的节点就可以优化插入速度:
 图片
图片
在上面这个结构中,插入23的过程是
- 先使用第2层链接head->7->19->26,发现26比23大,就回到19
- 再用第1层连接19->22->26,发现比23大,那么就插入到26之前,22之后
上面这张图就是跳表的初步原理,但一个元素插入链表后,应该拥有几层连接呢?跳表在这块的实现方式是随机的,也就是23这个元素插入后,随机出一个数,比如这个数是3,那么23就会有如下连接:
- 第3层head->23->end
- 第2层19->23->26
- 第1层22->23->26
下面这张图展示了如何形成一个跳表
 图片
图片
在上述跳表中查找/插入23的过程为:
 图片
图片
总结一下跳表原理:
- 每个跳表都必须设定一个最大的连接层数MaxLevel
- 第一层连接会连接到表中的每个元素
- 插入一个元素会随机生成一个连接层数值[1, MaxLevel]之间,根据这个值跳表会给这元素建立N个连接
- 插入某个元素的时候先从最高层开始,当跳到比目标值大的元素后,回退到上一个元素,用该元素的下一层连接进行遍历,周而复始直到第一层连接,最终在第一层连接中找到合适的位置
使用场景:
- 对有序数据进行排序,例如新闻排行榜或游戏排行榜。
- 对数据进行分组,例如将所有评分在3.0 到4.0 之间的电影分为一组。
- 对数据进行去重,例如将所有重复的单词从文本中删除。
本文转载自微信公众号「王中阳Go」,作者「王中阳Go」,可以通过以下二维码关注。

转载本文请联系「王中阳Go」公众号。