一、背景
相信做过HBase开发、运维相关工作的朋友多多少少都有这样感受,HBase作为分布式非关系型数据库中的佼佼者不仅稳定、性能高、安装扩容等运维也非常简单,但是HBase缺乏成熟监控系统对故障排查极不友好。如果缺乏对HBase全面了解在应对日常故障经常束手无策,小编们作为运维大大小小20+个HBase集群涉及1.x~2.x等版本,经历过meta表损坏无法正常上线、Region重叠、Region空洞、权限丢失等线上问题毒打,也带着各种各样问题从HBase源码中寻求正确答案,本文是小编们多次故障中总结出的meta表常见解决方案。
二、HBase meta 元信息表
HBase meta表又称为catalog表是一张特殊的HBase表,它存储了HBase集群所有Region和其对应的RegionServer信息,元信息表的数据正确性对于HBase集群的正常运行至关重要,因此需要保证元信息表的数据正确是集群稳定运行的必要条件。如果meta表出现数据不一致将会导致RIT(Region In Transition)甚至出现由于HMaster 无法正常初始化导致集群无法正常启动,由此可见meta表在HBase集群中重要性,下面我们围绕meta表结构、数据格式、启动流程进行解析它(本文主要围绕HBase 2.4.8版本,也会穿插HBase 1.x版本)。
2.1 meta 表结构
meta表主要包括info、table、rep_barrier三个列族分别记录Region信息、表状态:

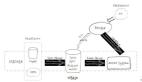
2.2 meta 表加载流程
通过上述meta表结构我们对该表有一个整体认识,做过HBase运维的朋友相信都有这种经验有一些集群启动比较快、有一些集群启动比较慢,甚至有时候由于操作不当集群重启时候一直卡在meta表加载无法继续执行后续流程。如果我们对meta表加载流程有一个整体了解之后我们将对每一个集群启动时间多多少少都有一个心理预期,以下是meta表加载相关流程:

通过以上meta表加载流程图我们很好找到为什么有一些集群启动比较慢、有一些集群启动失败原因了,下面我们针对两类场景进行分析:
集群启动慢:
通常新集群或者表数量比较少集群往往启动速度比较快,表数量比较多的集群往往启动相对慢很多,甚至有一些集群启动HMaster需要15~30分钟,有时候集群启动时间比较长让人不免怀疑是不是集群出现问题了,为什么那么长时间无法进入正常状态呢?在整个加载流程中出现两个耗时比较长地方。
预加载所有表描述符:需要把HBase数据目录全部扫描一遍并解析出.tabledesc目录下面数据文件存放HMaster 内存中,如果表数量比较多(超过10000张表)这一过程往往需要十来分钟,如果我们看HMaster 页面出现“Pre-loading table descriptors”字样时说明该集群处于预加载阶段我们只需耐心等待即可,因为还没有到meta表加载阶段。
上线业务表Region:meta表数据大小通常在几十M到几百M之间Region打开时间比较快(秒级),集群启动阶段需要检查并上线Offline Region,如果想加快打开速度可以适当调整hbase.master.executor.openregion.threads(默认值为5)值。
集群启动失败:
meta表上线失败:当default资源组的HRegionServer挂掉之后,重启后机器的startcode变化之后,meta的数据分片找不到打开节点,导致集群启动失败。
三、如何修复 meta 表
由于HBase集群状态主要是通过meta表去维护,如果meta表出现了损坏或错误,将会导致HBase集群的不可用和面临数据丢失风险。我们知道meta表数据一致性非常重要那么什么情况会出现数据不一致呢?(HBase 2.4.8修复命令参考hbase-operator-tools工具)。
- RegionServer宕机或异常:当RegionServer宕机或异常时,meta表中存储的Region和RegionServer信息可能会出现错误或丢失。
- 数据损坏或错误:当meta表中的数据损坏或错误时,可能会导致HBase集群的不可用和数据丢失。
- 非法操作:当对meta表进行非法操作时,例如删除或修改meta表中的数据,可能会导致meta表出现错误或丢失。
meta表故障只是一直比较笼统的说法,我们可以根据类型可以大致分为长时间RIT、Region空洞、Region重叠、表描述文件丢失、meta表hdfs路径为空、meta表数据丢失等,下面我分别对这些类型故障进行分析并进行修复:
3.1 RIT
RIT(Region In Transition)是指HBase集群中正在进行状态转换,以下操作都会引起HBase集群中Region的状态发生变化,例如RegionServer宕机、Region正在进行拆分、合并等操作,Region状态主要是包括以下十二种状态以及转化图:


为了更加清晰Region状态装换我们根据操作类型可以分为assign、unassign、split、merge,如果操作过程出现RegionServer宕机或异常、数据损坏或错误都会出现RIT,RIT虽然是在HBase运维中经常遇见的问题,但是如果清楚底层逻辑将会比较容易处理RIT问题,HBase集群都具备RIT修复能力大部分情况都不需要手工介入都能正常恢复,出现长时间RIT才需要人工介入处理,那什么是长时间RIT?为什么会出现长时间RIT呢?
如果用过HBase 1.x和HBase 2.x版本明显感觉HBase 2.x比较少出现RIT,其实Region的操作主要是通过AssignmentManager类进行Region转移,对比两个版本代码我们发现hbase.assignment.maximum.attempts参数(assign重试次数)在两个版本的默认值不一样,HBase 2.4.8重试次数为最大整数Integer.MAX_VALUE(而HBase 1.x中该值默认为10),这就是为什么在HBase 2.x中比较少出现长时间RIT原因。

RIT处理方法:
- 建删大表都会出现RIT主要是由于Region数量比较多集群压力比较大导致assign、unassign响应时间过长导致,针对这类问题一般不需要人工介入HBase可以自愈。
- 如果集群版本为1.x可以适当调整hbase.assignment.maximum.attempts值增加重试次数,如FAILED_OPEN、FAILED_CLOSE通常都可以自愈,或者手工执行assign命令一个个Region分配上线(如果Region比较多切换HMaster 修复)。
- 如果出现Region分配失败,不存在RegionServer时候,手工assign都没办法恢复,如Region被分配到bogus.example.com,1,1节点只能通过切换HMaster 恢复。
问题思考:
为什么Region手工介入都不能正常上线切换HMaster 就能恢复呢?(参考HMaster 启动流程TransitRegionStateProcedure、HMaster 类源码)
3.2 Region 空洞
我们创建HBase表时如果细心去分析Region规律会奇怪发现Region startkey和endkey属于左闭右开的连续区间,如果突然这些区间少了一块(如下图)将会出现什么问题呢?

出现上面情况就是我们常说的Region出现空洞,如果用HBase hbck工具检查会看到这样错误信息ERROR: There is a hole in the region chain between 01 and 02. You need to create a new .regioninfo and region dir in hdfs to plug the hole,HBase集群出现空洞往往是没办法自愈需要人工干预才能恢复正常,既然我们知道少了一个Region我们如果把空白区间的Region补回去不就可以了吗?正常做法是先把空白的Region补充回去,并检查meta表信息是否正确,最后再上线Region,如果这一系列操作都通过手工去实现不仅仅容易出错操作时间也很长,下面分别介绍一下不同版本HBase修复方法,其实不同版本处理方法虽然有一点差异但是处理流程都一样。

Region空洞处理方法:
(1)HBase 1.x修复方法
- HBase hbck –fixHdfsHoles:在hdfs上创建空Region文件路径
- HBase hbck -fixMeta:修复该Region所在meta表数据
- HBase hbck –fixAssignments:上线修复之后Region
- 或者HBase hbck –repairHoles相当于(fixHdfsHoles、fixMeta、fixAssignments)几个组合起来
(2)HBase 2.4.8修复方法(参考后面hbase-operator-tools工具)
由于HBase 2.4.8没有提供相关的命令去添加Region目录操作方面相对麻烦一点,其实HBase 2.4.8里面很多工具类都提供创建Region方法,hbase-server-2.4.8-test包中HBaseTestingUtility类都提供了操作Region相关的入口,下面我们的解决方法主要是围绕该方法进行恢复。
- extraRegionsInMeta -fix:首先把meta表中hdfs目录不存在记录先删除
- HBaseTestingUtility.createLocalHRegion:创建hdfs文件路径保证Region连续性
- addFsRegionsMissingInMeta:再往meta表添加新建Region信息(添加成功之后会返还Region id
- assigns:最后把新加入Region上线
3.3 Region 重叠
既然Region会出现空洞那么会不会存在这种情况,相同的startkey、endkey出现多个呢?答案是肯定的如果多个Region startkey、endkey是一样的Region,那么我们将这种情况称作Region重叠。Region重叠在HBase中比较难模拟同时也是比较难处理的一种问题。如果我们做hbck检查时候出现这种日志ERROR: Multiple regions have the same startkey: 02

另外一种重叠Region跟相邻的分片其中一个或两个的rowkey范围有交集,这类问题统称overlap问题,针对这个比较难的场景我们通过自研工具模拟overlap问题复现并一键修复overlap(折叠)和hole(空洞)问题。
overlap问题模拟功能
Region重叠问题实际就是两个不同Region,rowkey的范围有交集,比如Region01的startkey和endkey是(01,03),同时另外一个Region02的范围是(01,02),这样两个Region出现了交集(01,02),hbck检测就会报overlap问题。
重叠问题在生产环境只有在Region分裂和机器同时挂掉情况下,才会出现overlap问题,出现条件比较苛刻,复现问题比较困难,能够复现问题对后续修复和故障演练都很重要,overlap问题复现原理:

overlap 问题复现
1)生成一个rowkey范围重叠的Region分片:
2) 将overlap问题Region移动到表目录下:

3) 删除正常的表migrate:test_hole2的meta表信息:
4)重构overlap问题表元数据信息:
5) 重启集群后hbck报告Region重叠c8662e08f6ae705237e390029161f58f,成功复现重叠问题

方法一:一键修复overlap(重叠)和hole(空洞)
适用于折叠数量不超过64个情况下,利用自研工具 hbase-meta-tool可以将相邻Region有rowkey交集的范围合并,有空洞缺失范围生成新的Region,这样就能修复问题,问题修复原理如图:

1)修复集群的重叠与空洞问题:
方法二:大规模折叠修复
适用大规模折叠超过几千个或者上万个情况修复服务器端报异常,采取一下修复手段
1)一键清除有折叠问题表的元数据:
2)备份原始表数据:
3)删除原始表和导入备份数据每个Region分片:
3.4 meta 表数据修复
HBase线上集群我们可能会遇到下面棘手问题:
- coprocessor配置错误的表,找不到协处理器路径,加载Region过程中找不到jar,导致集群反复挂掉,drop命令也删除不掉;
- HBase meta表元数错误,startcode不对,上线过程中找不到服务器的表,表始终不能上线。
我们要在保证不影响集群其他表服务的情况下,单独不停服修复问题表。
问题表的meta数据修复
1)假设表migrate:test1有问题,可以一键删除问题表元数据:
2)读取hdfs表的.regioninfo文件夹内容,一键重构正确的元数据:
3.5 meta 损坏
上述5种情况都是在meta表正常上线的前提下面修复,如果meta表数据损坏无法上线我们应该怎么修复呢?通常我们都会想到重建meta表再把Region信息写入meta表,如果集群处于下线状态HBase shell或者HBase api通常是无法执行create建表。
我们分析meta表初始化类InitMetaProcedure发现meta表创建流程大致分两步走:
1)创建Region目录已经.tabledesc文件
2)分配Region并上线。
InitMetaProcedure核心源码:
InitMetaProcedure
我们可以参照InitMetaProcedure代码逻辑编写相应工具进行建表上线操作,meta表上线之后我们只需要把每张表Region信息写入meta并对所有Region进行assign上线即可恢复集群正常状态。通过以上流程我们发现meta表修复流程也并非那么复杂,但是如果生产环境表数量比较多或者个别大表Region数成千上万那么手工添加就变的非常耗时,我们下面介绍一直相对比较简单的解决方法(HBase 1.x hbck工具、HBase 2.x hbase-operator-tools),下面我们看一下离线修复处理流程。

HBase 1.x修复方法
- 停止HBase集群
- sudo -u hbase hbase org.apache.hadoop.hbase.
util.hbck.OfflineMetaRepair -fix - 重启集群完成修复。
HBase 2.4.8修复方法(hbase-operator-tools工具)
1)根据hdfs路径自动生成meta表
- 停止HBase集群
- sudo -u hbase hbase org.apache.hbase.
hbck1.OfflineMetaRepair -fix - 重启集群完成修复。
2)单表修复方法
- 删除zookeeper中HBase根目录
- 删除HMaster 、RegionServer所在hdfs WALs目录
- 重启集群此时meta没有数据,集群无法进入正常状态
- 执行添加Region命令把hbase:namespace、hbase:quota、hbase:rsgroup、hbase:acl四字表添加到集群,添加完成之后日志将会打印assigns后面跟随这几张表的Region,需要记录下这些Region以便下一步assign操作。
- 把上一步添加打印Region上线
- 业务表上线(只需要重复4-5步骤把业务表逐步上线)
注意事项
(如果业务表Region比较多第5不assign不能把Region全部上线成功,需要把表现disable再enable就可以正常上线)
备注:hbase-operator-tools OfflineMetaRepair工具存在以下几个bug需要修复。
1、HBaseFsck createNewMeta方法创建meta表缺少.tabledesc文件
修改前:
修改后:
2、HBaseFsck generatePuts默认Region状态为CLOSED因为HMaster 重启时候只上线OFFLINE状态Region(如果为CLOSED需要手工一个个Region上线工作量非常庞大)
修改前:
修改后:
缺点
1)离线修复需要停止集群服务,停止时长根据修复时间而定(大概在10-15分钟左右)。
2)如果其中存在Region重叠、空洞等问题需要手工处理完成再执行OfflineMetaRepair离线修复命令。
四、hbase-operator-tools工具
hbase-operator-tools是HBase中的一组工具,用于协助HBase管理员管理和维护HBase集群。hbase-operator-tools提供了一系列工具,包括备份和恢复工具、Region管理工具、数据压缩和移动工具等,可以帮助管理员更好地管理HBase集群,提高集群的稳定性和可靠性。需要编译源码之后才可以使用,源码git地址。常见命令如下:

五、总结
HBase meta表的数据正确性对于HBase集群的正常运行至关重要,如何保证meta表数据正确以及数据损坏之后快速修复变的极为重要,如果对meta没有全面认识每次集群出现故障将会措手无策。本文主要是围绕meta表结构加载流程、常见问题以及相关的修复方法分析,针对以上修复方法我们可以粗略分为以下两大类:
- 在线修复:meta表可以正常通过hbck、自研工具进行meta表数据修复保证数据完整性。
- 离线修复:meta表无法正常上线根据hdfs中Region信息重构meta表恢复HBase服务。
如果集群规模比较大离线修复时间比较长集群需要长时间停止服务,大部分情况业务是不能容忍可以结合实际情况进行表级别修复(除非meta表文件损坏不能正常上线),建议定时对集群做hbck检查一旦出现元信息不一致情况尽快修复避免问题扩散(如元信已经错乱做集群重启错乱Region将会由于assign失败导致其他Region无法正常上线),如果定时巡检发现有业务表出现元信息错乱情况直接重meta表把该表信息删除并根据根据hdfs路径信息重新把Region加回meta表(addFsRegions-
MissingInMeta命令可以根据hdfs路径把Region正确添加到meta表)。
参考文章: