SQL 窗口函数为在线分析系统(OLAP)和商业智能(BI)提供了复杂分析和报表统计的功能,例如产品的累计销量统计、分类排名、同比/环比分析等。这些功能通常很难通过聚合函数和分组操作来实现。
本文比较了五种主流数据库实现的窗口函数,包括 MySQL、Oracle、SQL Server、PostgreSQL 以及 SQLite。

窗口函数定义
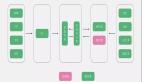
窗口函数(Window Function)可以像聚合函数一样对一组数据进行分析并返回结果,二者的不同之处在于,窗口函数不是将一组数据汇总成单个结果,而是为每一行数据都返回一个分析结果。聚合函数和窗口函数的区别如下图所示。

我们以 SUM 函数为例演示这两种函数的差异,以下语句中的 SUM() 是一个聚合函数:
SELECT SUM(salary) AS "月薪总和"
FROM employee;以上 SUM 函数作为聚合函数使用,表示将所有员工的数据汇总成一个结果。因此,查询返回了所有员工的月薪总和:
月薪总和
---------
245800.00以下语句中的 SUM 是一个窗口函数:
SELECT emp_name AS "员工姓名",
SUM(salary) OVER () AS "月薪总和"
FROM employee;其中,关键字 OVER 表明 SUM() 是一个窗口函数。括号内为空,表示将所有数据作为一个分组进行汇总。该查询返回的结果如下:
员工姓名|月薪总和
-------|---------
刘备 |245800.00
关羽 |245800.00
张飞 |245800.00
...以上查询结果返回了所有的员工姓名,并且通过聚合函数 SUM() 为每个员工都返回了相同的汇总结果。
从以上示例中可以看出,窗口函数的语法与聚合函数的不同之处在于,它包含了一个 OVER 子句。OVER 子句用于指定一个数据分析的窗口,完整的窗口函数定义如下:
window_function ([expression], ...) OVER (
PARTITION BY ...
ORDER BY ...
frame_clause
)其中 window_function 是窗口函数的名称,expression 是可选的分析对象(字段名或者表达式),OVER 子句包含分区(PARTITION BY)、排序(ORDER BY)以及窗口大小(frame_clause)3 个选项。
提示:聚合函数将同一个分组内的多行数据汇总成单个结果,窗口函数则保留了所有的原始数据。在某些数据库中,窗口函数也被称为联机分析处理(OLAP)函数,或者分析函数(Analytic Function)。
创建数据分区
窗口函数 OVER 子句中的 PARTITION BY 选项用于定义分区,其作用类似于查询语句中的 GROUP BY 子句。如果我们指定了分区选项,窗口函数将会分别针对每个分区单独进行分析。
例如,以下语句按照不同部门分别统计员工的月薪合计:
SELECT emp_name "员工姓名", salary "月薪", dept_id "部门编号",
SUM(salary) OVER (
PARTITION BY dept_id
) AS "部门合计"
FROM employee;其中,PARTITION BY 选项表示按照部门进行分区。查询返回的结果如下:
员工姓名|月薪 |部门编号|部门合计
-------|--------|-------|--------
刘备 |30000.00| 1|80000.00
关羽 |26000.00| 1|80000.00
张飞 |24000.00| 1|80000.00
诸葛亮 |24000.00| 2|39500.00
黄忠 | 8000.00| 2|39500.00
魏延 | 7500.00| 2|39500.00
...查询结果中的前 3 行数据属于同一个部门,因此它们对应的部门合计字段都等于 80000(30000+26000+24000)。其他部门的员工采用同样的方式进行统计。
提示:在窗口函数 OVER 子句中指定了 PARTITION BY 选项之后,我们无须使用 GROUP BY 子句也能获得分组统计结果。如果不指定 PARTITION BY 选项,表示将全部数据作为一个整体进行分析。
分区内的排序
窗口函数 OVER 子句中的 ORDER BY 选项用于指定分区内数据的排序方式,作用类似于查询语句中的 ORDER BY 子句。
排序选项通常用于数据的分类排名。例如,以下语句用于分析员工在部门内的月薪排名:
SELECT emp_name "姓名", salary "月薪", dept_id "部门编号",
RANK() OVER (
PARTITION BY dept_id
ORDER BY salary DESC
) AS "部门排名"
FROM employee;其中,RANK 函数用于计算数据的名次,PARTITION BY 选项表示按照部门进行分区,ORDER BY 选项表示在部门内按照月薪从高到低进行排序。查询返回的结果如下:
姓名 |月薪 |部门编号|部门排名
------|--------|-------|-------
刘备 |30000.00| 1| 1
关羽 |26000.00| 1| 2
张飞 |24000.00| 1| 3
诸葛亮|24000.00| 2| 1
黄忠 | 8000.00| 2| 2
魏延 | 7500.00| 2| 3
...查询结果中的前 3 行数据属于同一个部门:“刘备”的月薪最高,在部门内排名第 1;“关羽”排名第 2;“张飞”排名第 3。其他部门的员工采用同样的方式进行排名。
提示:窗口函数 OVER 子句中的 ORDER BY 选项和查询语句中的 ORDER BY 子句的使用方法相同。因此,对于 Oracle、PostgreSQL 以及 SQlite,我们也可以使用 NULLS FIRST 或者 NULLS LAST 选项指定空值的排序位置。
指定窗口大小
窗口函数 OVER 子句中的 frame_clause 选项用于指定一个移动的分析窗口,窗口总是位于分区的范围之内,是分区的一个子集。在指定了分析窗口之后,窗口函数不再基于分区进行分析,而是基于窗口内的数据进行分析。
窗口选项可以用于实现各种复杂的分析功能,例如计算累计到当前日期为止的销量总和,每个月及其前后各 N 个月的平均销量等。
指定窗口大小的具体选项如下:
{ ROWS | RANGE } frame_start
{ ROWS | RANGE } BETWEEN frame_start AND frame_end其中,ROWS 表示以数据行为单位计算窗口的偏移量,RANGE 表示以数值(例如 10 天、5 千米等)为单位计算窗口的偏移量。
提示:除了 ROWS 和 RANGE 之外,Oracle、PostgreSQL 以及 SQLite 还支持 GROUPS 类型的窗口大小,数值相等的数据行都属于一个 GROUP。
frame_start 选项用于定义窗口的起始位置,可以指定以下内容之一:
- UNBOUNDED PRECEDING,表示窗口从分区的第一行开始。
- N PRECEDING,表示窗口从当前行之前的第 N 行开始。
- CURRENT ROW,表示窗口从当前行开始。
frame_end 选项用于定义窗口的结束位置,可以指定以下内容之一:
- CURRENT ROW,表示窗口到当前行结束。
- N FOLLOWING,表示窗口到当前行之后的第 N 行结束。
- UNBOUNDED FOLLOWING,表示窗口到分区的最后一行结束。
下图说明了这些窗口大小选项的含义。

随着窗口函数对每一行数据的分析,图中的 CURRENT ROW 代表了当前正在处理的数据行,其他的数据行则可以通过它们相对于当前行的位置进行表示。例如,以下窗口选项:
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW表示分析窗口从当前分区的第一行开始,直到当前行结束。
分析窗口的大小不会超出当前分区的范围,每个窗口函数支持的窗口大小选项不同,我们将会在下面的案例分析中分别进行介绍。
窗口函数分类
常见的 SQL 窗口函数可以分为以下几类:
- 聚合窗口函数(Aggregate Window Function)。许多常见的聚合函数也可以作为窗口函数使用,包括 AVG()、SUM()、COUNT()、MAX() 以及 MIN() 等。
- 排名窗口函数(Ranking Window Function)。排名窗口函数用于对数据进行分组排名,包括 ROW_NUMBER()、RANK()、DENSE_RANK()、PERCENT_RANK()、CUME_DIST() 以及 NTILE() 等函数。
- 取值窗口函数(Value Window Function)。取值窗口函数用于返回指定位置上的数据行,包括 FIRST_VALUE()、LAST_VALUE()、LAG()、LEAD()、NTH_VALUE() 等函数。
接下来我们将会使用两个示例表,其中 sales_monthly 表中存储了不同产品(苹果、香蕉、桔子)每个月的销量情况,以下是该表中的部分数据:
product|ym |amount
-------|------|--------
苹果 |201801|10159.00
苹果 |201802|10211.00
苹果 |201803|10247.00
苹果 |201804|10376.00
苹果 |201805|10400.00
苹果 |201806|10565.00
...transfer_log 表中记录了一些银行账号的交易日志,以下是该表中的部分数据:
log_id|log_ts |from_user |to_user |type|amount
------|-------------------|--------------|--------------|----|------
1|2019-01-02 10:31:40|62221234567890| |存款 | 50000
2|2019-01-02 10:32:15|62221234567890| |存款 |100000
3|2019-01-03 08:14:29|62221234567890|62226666666666|转账 |200000
4|2019-01-05 13:55:38|62221234567890|62226666666666|转账 |150000
5|2019-01-07 20:00:31|62221234567890|62227777777777|转账 |300000
6|2019-01-09 17:28:07|62221234567890|62227777777777|转账 |500000
...该表中的字段分别表示交易日志编号、交易时间、交易发起账号、交易接收账号、交易类型以及交易金额。
聚合窗口函数
案例分析:移动平均值
AVG 函数在作为窗口函数使用时,可以用于计算随着当前行移动的窗口内数据行的平均值。例如,以下语句用于查找不同产品截至每个月、最近 3 个月的平均销量:
SELECT product AS "产品", ym "年月", amount "销量",
AVG(amount) OVER (
PARTITION BY product
ORDER BY ym
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
) AS "最近平均销量"
FROM sales_monthly
ORDER BY product, ym;AVG 函数 OVER 子句中的 PARTITION BY 选项表示按照产品进行分区;ORDER BY 选项表示按照月份进行排序;ROWS BETWEEN 2 PRECEDING AND CURRENT ROW 表示窗口从当前行的前 2 行开始,直到当前行结束。该查询返回的结果如下:
产品|年月 |销量 |最近平均销量
----|------|--------|------------
桔子|201801|10154.00|10154.000000
桔子|201802|10183.00|10168.500000
桔子|201803|10245.00|10194.000000
桔子|201804|10325.00|10251.000000
桔子|201805|10465.00|10345.000000
桔子|201806|10505.00|10431.666667
...对于“桔子”,第一个月的分析窗口只有 1 行数据,因此平均销量为“10154”。第二个月的分析窗口为第 1 行和第 2 行数据,因此平均销量为“10168.5”((10154+10183)/2)。第三个月的分析窗口为第 1 行到第 3 行数据,因此平均销量为“10194”((10154+10183+10245)/3)。依此类推,直到计算完“桔子”所有月份的平均销量,然后开始计算其他产品的平均销量。
案例分析:累计求和
SUM 函数作为窗口函数时,可以用于统计指定窗口内的累计值。例如,以下语句用于查找不同产品截至当前月份的累计销量:
SELECT product AS "产品", ym "年月", amount "销量",
SUM(amount) OVER (
PARTITION BY product
ORDER BY ym
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS "累计销量"
FROM sales_monthly
ORDER BY product, ym;SUM 函数 OVER 子句中的 PARTITION BY 选项表示按照产品进行分区;ORDER BY 选项表示按照月份进行排序;ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 表示窗口从当前分区第 1 行开始,直到当前行结束。该查询返回的结果如下:
产品|年月 |销量 |累计销量
----|------|--------|---------
桔子|201801|10154.00| 10154.00
桔子|201802|10183.00| 20337.00
桔子|201803|10245.00| 30582.00
桔子|201804|10325.00| 40907.00
桔子|201805|10465.00| 51372.00
桔子|201806|10505.00| 61877.00
...对于“桔子”,第一个月的分析窗口只有 1 行数据,因此累计销量为“10154”。第二个月的分析窗口为第 1 行和第 2 行数据,因此累计销量为“20337”(10154+10183)。第三个月的分析窗口为第 1 行到第 3 行数据,因此累计销量为“30582”(10154+10183+10245)。依此类推,直到计算完“桔子”所有月份的累计销量,然后开始计算其他产品的累计销量。
提示:对于聚合窗口函数,如果我们没有指定 ORDER BY 选项,默认的窗口大小就是整个分区。如果我们指定了 ORDER BY 选项,默认的窗口大小就是分区的第一行到当前行。因此,以上示例语句中的 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 选项可以省略。
除使用 ROWS 关键字以数据行为单位指定窗口的偏移量外,我们也可以使用 RANGE 关键字以数值为单位指定窗口的偏移量。例如,以下语句用于查找短期之内(5 天)累计转账超过100 万元的账号:
-- Oracle、MySQL 以及 PostgreSQL
SELECT log_ts, from_user, total_amount
FROM (
SELECT log_ts, from_user,
SUM(amount) OVER (
PARTITION BY from_user
ORDER BY log_ts
RANGE INTERVAL '5' DAY PRECEDING
) AS total_amount
FROM transfer_log
WHERE TYPE = '转账'
) t
WHERE total_amount >= 1000000;其中,SUM 函数 OVER 子句中的 RANGE 选项指定了一个 5 天之内的时间窗口。该查询返回的结果如下:
log_ts |from_user |total_amount
-------------------|--------------|------------
2021-01-10 07:46:02|62221234567890| 1050000截至 2021 年 1 月 10 日 7 时 46 分 02 秒,账号“62221234567890”在最近 5 天之内累计转账 105 万元。
SQLite 不支持 INTERVAL 时间常量,我们可以将时间戳数据转换为整数后使用,例如:
-- SQLite
WITH tl(log_ts, unix, from_user, amount) AS (
SELECT log_ts, CAST(STRFTIME('%s', log_ts) AS INT), from_user, amount
FROM transfer_log
WHERE type = '转账'
)
SELECT log_ts, from_user, total_amount
FROM (
SELECT log_ts, from_user,
SUM(amount) OVER (
PARTITION BY from_user
ORDER BY unix
RANGE 5 * 86400 PRECEDING
) AS total_amount
FROM tl
) t
WHERE total_amount >= 1000000;我们首先定义了一个 CTE,字段 unix 表示将 log_ts 转换为 1970 年 1 月 1 日以来的整数秒。然后我们在 SUM 函数中通过 RANGE 选项指定了一个 5 天(5*86 400 秒)之内的时间窗口。
Microsoft SQL Server 中的 RANGE 窗口大小选项只能指定 UNBOUNDED PRECEDING、UNBOUNDED FOLLOWING 或者 CURRENT ROW,不能指定一个具体的数值,因此无法实现以上查询。
排名窗口函数
排名窗口函数可以用来获取数据的分类排名。常见的排名窗口函数如下:
- ROW_NUMBER 函数可以为分区中的每行数据分配一个序列号,序列号从 1 开始。
- RANK 函数返回当前行在分区中的名次。如果存在名次相同的数据,后续的排名将会产生跳跃。
- DENSE_RANK 函数返回当前行在分区中的名次。即使存在名次相同的数据,后续的排名也是连续值。
- PERCENT_RANK 函数以百分比的形式返回当前行在分区中的名次。如果存在名次相同的数据,后续的排名将会产生跳跃。
- CUME_DIST 函数计算当前行在分区内的累积分布。
- NTILE 函数将分区内的数据分为 N 等份,并返回当前行所在的分片位置。
排名窗口函数不支持动态的窗口大小选项,而是以整个分区作为分析的窗口。
案例分析:分类排名
以下查询使用 4 个不同的排名函数计算每个员工在其部门内的月薪排名:
SELECT d.dept_name AS "部门名称", e.emp_name AS "姓名", e.salary AS "月薪",
ROW_NUMBER() OVER (PARTITION BY e.dept_id ORDER BY e.salary DESC) AS "row_number",
RANK() OVER (PARTITION BY e.dept_id ORDER BY e.salary DESC) AS "rank",
DENSE_RANK() OVER (PARTITION BY e.dept_id ORDER BY e.salary DESC) AS "dense_rank",
PERCENT_RANK() OVER (PARTITION BY e.dept_id ORDER BY e.salary DESC) AS "percent_rank"
FROM employee e
JOIN department d ON (e.dept_id = d.dept_id);其中,4 个窗口函数的 OVER 子句完全相同,PARTITION BY 表示按照部门进行分区,ORDER BY 表示按照月薪从高到低进行排序。该查询返回的结果如下:
部门名称 |姓名 |月薪 |row_number|rank|dense_rank|percent_rank
--------|-----|--------|-----------|----|----------|----------------
行政管理部|刘备 |30000.00| 1| 1| 1| 0.0
行政管理部|关羽 |26000.00| 2| 2| 2| 0.5
行政管理部|张飞 |24000.00| 3| 3| 3| 1.0
...
研发部 |赵云 |15000.00| 1| 1| 1| 0.0
研发部 |周仓 | 8000.00| 2| 2| 2| 0.125
研发部 |关兴 | 7000.00| 3| 3| 3| 0.25
研发部 |关平 | 6800.00| 4| 4| 4| 0.375
研发部 |赵氏 | 6600.00| 5| 5| 5| 0.5
研发部 |廖化 | 6500.00| 6| 6| 6| 0.625
研发部 |张苞 | 6500.00| 7| 6| 6| 0.625
研发部 |赵统 | 6000.00| 8| 8| 7| 0.875
...我们以“研发部”为例,ROW_NUMBER 函数为每个员工分配了一个连续的数字编号,其中“廖化”和“张苞”的月薪相同,但是编号不同。
RANK 函数为每个员工返回了一个名次,其中“廖化”和“张苞”的名次都是 6,在他们之后“赵统”的名次为 8,产生了跳跃。
DENSE_RANK 函数为每个员工返回了一个名次,其中“廖化”和“张苞”的名次都是 6,在他们之后“赵统”的名次为 7,没有产生跳跃。
PERCENT_RANK 函数按照百分比指定名次,取值位于 0 到 1 之间。其中“赵统”的百分比排名为 0.875,产生了跳跃。
提示:我们也可以使用 COUNT()窗口函数产生和 ROW_NUMBER 函数相同的结果,读者可以自行尝试。
另外,以上示例中 4 个窗口函数的 OVER 子句完全相同。此时,我们可以采用一种更简单的写法:
-- MySQL、Oracle、PostgreSQL 以及 SQLite
SELECT d.dept_name AS "部门名称", e.emp_name AS "姓名", e.salary AS "月薪",
ROW_NUMBER() OVER w AS "row_number",
RANK() OVER w AS "rank",
DENSE_RANK() OVER w AS "dense_rank",
PERCENT_RANK() OVER w AS "percent_rank"
FROM employee e
JOIN department d ON (e.dept_id = d.dept_id)
WINDOW w AS (PARTITION BY e.dept_id ORDER BY e.salary DESC);我们在查询语句的最后使用 WINDOW 子句定义了一个窗口变量 w,然后在所有窗口函数的 OVER 子句中使用了该变量。
这种使用窗口变量的写法可以简化窗口选项的输入,目前 Microsoft SQL Server还不支持这种命名窗口语法。
基于排名窗口函数,我们还可以实现分类 Top-N 排行榜。例如,以下语句用于查找每个部门中最早入职的 2 名员工:
WITH ranked_emp AS (
SELECT d.dept_name,
e.emp_name,
e.hire_date,
ROW_NUMBER() OVER (PARTITION BY e.dept_id ORDER BY e.hire_date) AS rn
FROM employee e
JOIN department d ON (e.dept_id = d.dept_id)
)
SELECT dept_name "部门名称", emp_name "姓名", hire_date "入职日期", rn "入职顺序"
FROM ranked_emp
WHERE rn <= 2;其中,ranked_emp 是一个通用表表达式,包含了员工在其部门内的入职顺序。然后我们在主查询语句中返回了每个部门前 2 名入职的员工:
部门名称 |姓名 |入职日期 |入职顺序
--------|-----|----------|-------
行政管理部|刘备 |2000-01-01| 1
行政管理部|关羽 |2000-01-01| 2
人力资源部|诸葛亮|2006-03-15| 1
人力资源部|魏延 |2007-04-01| 2
财务部 |孙尚香|2002-08-08| 1
财务部 |孙丫鬟|2002-08-08| 2
...案例分析:累积分布
CUME_DIST 函数可以返回当前行在分区内的累积分布,也就是排名在当前行之前(包含当前行)所有数据所占的比率,取值范围为大于 0 且小于或等于 1。
例如,以下查询返回了所有员工按照月薪排名的累积分布情况:
SELECT emp_name AS "姓名", salary AS "月薪",
CUME_DIST() OVER (ORDER BY salary) AS "累积占比"
FROM employee;其中,OVER 子句没有指定分区选项,因此 CUME_DIST 函数会将全体员工作为一个整体进行分析。ORDER BY 选项表示按照月薪从低到高进行排序。该查询返回的结果如下:
姓名 |月薪 |累积占比
----|--------|-------
蒋琬 | 4000.00|0.08
邓芝 | 4000.00|0.08
庞统 | 4100.00|0.12
...
关羽 |26000.00|0.96
刘备 |30000.00| 1.0结果显示 8%(2/25)的员工月薪小于或等于 4000 元;或者也可以说,月薪 4000 元,意味着在公司中的月薪排名属于最低的 8%。
NTILE 函数用于将分区内的数据分为 N 等份,并计算当前行所在的分片位置。例如,以下语句将员工按照入职先后顺序分为 5 组,并计算每个员工所在的分组:
SELECT emp_name AS "姓名", hire_date AS "入职日期",
NTILE(5) OVER (ORDER BY hire_date) AS "分组位置"
FROM employee;其中,OVER 子句没有指定分区选项,因此 NTILE 函数会将全体员工作为一个整体进行分析。ORDER BY 选项表示按照入职先后进行排序。该查询返回的结果如下:
姓名 |入职日期 |分组位置
-----|----------|-------
刘备 |2000-01-01| 1
关羽 |2000-01-01| 1
张飞 |2000-01-01| 1
孙尚香|2002-08-08| 1
孙丫鬟|2002-08-08| 1
赵云 |2005-12-19| 2
...
简雍 |2019-05-11| 5分组位置为 1 的是最早入职的 20% 员工,分组位置为 5 的是最晚入职的 20% 员工。
取值窗口函数
取值窗口函数可以用来返回窗口内指定位置的数据行。常见的取值窗口函数如下:
- LAG 函数可以返回窗口内当前行之前的第 N 行数据。
- LEAD 函数可以返回窗口内当前行之后的第 N 行数据。
- FIRST_VALUE 函数可以返回窗口内第一行数据。
- LAST_VALUE 函数可以返回窗口内最后一行数据。
- NTH_VALUE 函数可以返回窗口内第 N 行数据。
其中,LAG 和 LEAD 函数不支持动态的窗口大小,它们以整个分区作为分析的窗口。
案例分析:环比、同比分析
环比增长指的是本期数据与上期数据相比的增长,例如,产品 2019 年 6 月的销量与 2019\ 年 5 月的销量相比增加的部分。以下语句统计了各种产品每个月的环比增长率:
SELECT product AS "产品", ym "年月", amount "销量",
((amount - LAG(amount, 1) OVER (PARTITION BY product ORDER BY ym))/ LAG(amount, 1) OVER (PARTITION BY product ORDER BY ym)) * 100 AS "环比增长率(%)"
FROM sales_monthly
ORDER BY product, ym;其中,LAG(amount, 1) 表示获取上一期的销量,PARTITION BY 选项表示按照产品分区,ORDER BY 选项表示按照月份进行排序。当前月份的销量 amount 减去上一期的销量,再除以上一期的销量,就是环比增长率。该查询返回的结果如下:
产品|年月 |销量 |环比增长率(%)
---|------|--------|------------
桔子|201801|10154.00|
桔子|201802|10183.00| 0.285602
桔子|201803|10245.00| 0.608858
...
香蕉|201904|11408.00| 1.063076
香蕉|201905|11469.00| 0.534712
香蕉|201906|11528.00| 0.5144302018 年 1 月是第一期,因此其环比增长率为空。2018 年 2 月“桔子”的环比增长率为 0.2856%((10183 - 10154) / 10154×100),依此类推。
同比增长指的是本期数据与上一年度或历史同期相比的增长,例如,产品 2019 年 6 月的销量与 2018 年 6 月的销量相比增加的部分。以下语句统计了各种产品每个月的同比增长率:
SELECT product AS "产品", ym "年月", amount "销量",
((amount - LAG(amount, 12) OVER (PARTITION BY product ORDER BY ym))/ LAG(amount, 12) OVER (PARTITION BY product ORDER BY ym)) * 100 AS "同比增长率(%)"
FROM sales_monthly
ORDER BY product, ym;其中,LAG(amount, 12)表示当前月份之前第 12 期的销量,也就是去年同月份的销量。PARTITION BY 选项表示按照产品分区,ORDER BY 选项表示按照月份进行排序。当前月份的销量 amount 减去去年同期的销量,再除以去年同期的销量,就是同比增长率。该查询返回的结果如下:
产品|年月 |销量 |同比增长率(%)
---|------|--------|------------
桔子|201801|10154.00|
桔子|201802|10183.00|
桔子|201803|10245.00|
...
桔子|201901|11099.00| 9.306677
桔子|201902|11181.00| 9.800648
桔子|201903|11302.00|10.317228
...2018 年的 12 期数据都没有对应的同比增长率,“桔子”2019 年 1 月的同比增长率为 9.3067%
((11099 - 10154) / 10154×100),依此类推。
提示:LEAD 函数与 LAG 函数的使用方法类似,不过它的返回结果是当前行之后的第 N 行数据。
案例分析:复合增长率
复合增长率是第 N 期的数据除以第一期的基准数据,然后开 N-1 次方再减去 1 得到的结果。假如 2018 年的产品销量为 10 000,2019 年的产品销量为 12 500,2020 年的产品销量为 15 000(销量单位省略,下同)。那么这两年的复合增长率的计算方式如下:
(15000/10000)(1/2) - 1 = 22.47%以年度为单位计算的复合增长率被称为年均复合增长率,以月度为单位计算的复合增长率被称为月均复合增长率。以下查询统计了自 2018 年 1 月以来不同产品的月均销量复合增长率:
WITH s(product, ym, amount, first_amount, num) AS (
SELECT product, ym, amount,
FIRST_VALUE(amount) OVER (PARTITION BY product ORDER BY ym),
ROW_NUMBER() OVER (PARTITION BY product ORDER BY ym)
FROM sales_monthly
)
SELECT product AS "产品", ym "年月", amount "销量",
(POWER(1.0*amount/first_amount, 1.0/NULLIF(num-1, 0)) - 1) * 100 AS "月均复合增长率(%)"
FROM s
ORDER BY product, ym;我们首先定义了一个通用表表达式,其中 FIRST_VALUE(amount)返回了第一期(201801)的销量,ROW_NUMBER 函数返回了每一期的编号。主查询中的 POWER 函数用于执行开方运算,NULLIF 函数用于处理第一期数据的除零错误,常量 1.0 用于避免由整数除法所导致的精度丢失问题。该查询返回的结果如下:
产品|年月 |销量 |月均复合增长率(%)
---|------|--------|-----------------
桔子|201801|10154.00|
桔子|201802|10183.00| 0.285602
桔子|201803|10245.00| 0.447100
桔子|201804|10325.00| 0.558233
桔子|201805|10465.00| 0.757067
桔子|201806|10505.00| 0.681987
...2018 年 1 月是第一期,因此其产品月均销量复合增长率为空。“桔子”2018 年 2 月的月均销量复合增长率等于它的环比增长率,2018 年 3 月的月均销量复合增长率等于 0.4471%,依此类推。
以下语句统计了不同产品最低销量、最高销量以及第三高销量所在的月份:
SELECT product AS "产品", ym "年月", amount "销量",
FIRST_VALUE(ym) OVER (
PARTITION BY product ORDER BY amount DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS "最高销量月份",
LAST_VALUE(ym) OVER (
PARTITION BY product ORDER BY amount DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS "最低销量月份",
-- Microsoft SQL Server 不支持 NTH_VALUE
NTH_VALUE(ym, 3) OVER (
PARTITION BY product ORDER BY amount DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS "第三高月份"
FROM sales_monthly
ORDER BY product, ym;三个窗口函数的OVER子句相同,PARTITION BY选项表示按照产品进行分区,ORDER BY 选项表示按照销量从高到低排序。以上三个函数的默认窗口都是从分区的第一行到当前行,因此我们将窗口扩展到了整个分区。该查询返回的结果如下:
产品|年月 |销量 |最高销量月份|最低销量月份|第三高月份
---|------|-----|----------|----------|---------
桔子|201801|10154|201906 |201801 |201904
桔子|201802|10183|201906 |201801 |201904
桔子|201803|10245|201906 |201801 |201904
桔子|201804|10325|201906 |201801 |201904
桔子|201805|10465|201906 |201801 |201904
桔子|201806|10505|201906 |201801 |201904
...“桔子”的最高销量出现在 2019 年 6 月,最低销量出现在 2018 年 1 月,第三高销量出现在 2019 年 4 月。
Microsoft SQL Server 目前还不支持 NTH_VALUE() 窗口函数,因此无法得到销量第三高的月份。