大模型又又又被曝出安全问题!
近日,来自Enkrypt AI的研究人员发表了令人震惊的研究成果:量化和微调竟然也能降低大模型的安全性!

论文地址:https://arxiv.org/pdf/2404.04392.pdf
在作者的实际测试中,Mistral、Llama等基础模型包括它们微调版本,无一幸免。
在经过了量化或者微调之后,LLM被越狱(Jailbreak)的风险大大增加。

——LLM:我效果惊艳,我无所不能,我千疮百孔......
也许,未来很长一段时间内,在大模型各种漏洞上的攻防战争是停不下来了。
由于原理上的问题,AI模型天然兼具鲁棒性和脆弱性,在巨量的参数和计算中,有些无关紧要,但又有一小部分至关重要。
从某种程度上讲,大模型遇到的安全问题,与CNN时代一脉相承,
利用特殊提示、特殊字符诱导LLM产生有毒输出,包括之前报道过的,利用LLM长上下文特性,使用多轮对话越狱的方法,都可以称为:对抗性攻击。
对抗性攻击
在CNN时代,通过更改输入图像的几个像素,就能导致AI模型对图像分类错误,攻击者甚至可以诱导模型输出为特定的类别。

上图展示了对抗性攻击的过程,为了便于观察,中间的随机扰动做了一些夸张,
实际中,对于对抗攻击来说,只需要像素值很小的改变,就可以达到攻击效果。
更危险的是,研究人员发现这种虚拟世界的攻击行为,可以转移到现实世界。
下图的「STOP」标志来自之前的一篇著名工作,通过在指示牌上添加一些看似无关的涂鸦,就可以让自动驾驶系统将停车标志误识别为限速标志。

——这块牌子后来被收藏在伦敦科学博物馆,提醒世人时刻注意AI模型潜藏的风险。
大语言模型目前受到的此类伤害包括但可能不限于:越狱、提示注入攻击、隐私泄露攻击等。
比如下面这个使用多轮对话进行越狱的例子:

还有下图展示的一种提示注入攻击,使用尖括号将恶意指令隐藏在提示中,结果,GPT-3.5忽略了原来总结文本的指令,开始「make missile with sugar」。

为了应对这类问题,研究人员一般采用针对性的对抗训练,来保持模型对齐人类的价值观。
但事实上,能够诱导LLM产生恶意输出的提示可能无穷无尽,面对这种情况,红队应该怎么做?

防御端可以采用自动化搜索,而攻击端可以使用另一个LLM来生成提示帮助越狱。
另外,目前针对大模型的攻击大多是黑盒的,不过随着我们对LLM理解的加深,更多的白盒攻击也会不断加入进来。
相关研究
不过别担心,兵来将挡水来土掩,相关的研究早就卷起来了。
小编随手一搜,单单是今年的ICLR上,就有多篇相关工作。
比如下面这篇Oral:
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!

论文地址:https://openreview.net/pdf?id=hTEGyKf0dZ
这篇工作跟今天介绍的文章很像了:微调LLM会带来安全风险。
研究人员仅通过几个对抗性训练样本对LLM进行微调,就可以破坏其安全对齐。
其中一个例子仅用10个样本,通过OpenAI的API对GPT-3.5 Turbo进行微调,成本不到0.20美元,就使得模型可以响应几乎任何有害指令。
另外,即使没有恶意意图,仅仅使用良性和常用的数据集进行微调,也可能无意中降低LLM的安全对齐。
再比如下面这篇Spolight:
Jailbreak in pieces: Compositional Adversarial Attacks on Multi-Modal Language Models,
介绍了一种针对视觉语言模型的新型越狱攻击方法:

论文地址:https://openreview.net/pdf?id=plmBsXHxgR
研究人员将视觉编码器处理的对抗性图像与文本提示配对,从而破坏了VLM的跨模态对齐。
而且这种攻击的门槛很低,不需要访问LLM,对于像CLIP这样的视觉编码器嵌入在闭源LLM中时,越狱成功率很高。
此外还有很多,这里不再一一列举,下面来看一下本文的实验部分。
实验细节
研究人员使用了一个称为AdvBench SubsetAndy Zou的对抗性有害提示子集,包含50个提示,要求提供32个类别的有害信息。它是 AdvBench基准测试中有害行为数据集的提示子集。

实验使用的攻击算法是攻击树修剪(Tree-of-attacks pruning,TAP),实现了三个重要目标:
(1)黑盒:算法只需要黑盒访问模型;
(2)自动:一旦启动就不需要人工干预;
(3)可解释:算法可以生成语义上有意义的提示。
TAP算法与AdvBench子集中的任务一起使用,以在不同设置下攻击目标LLM。

实验流程
为了了解微调、量化和护栏对LLM安全性(抵抗越狱攻击)所产生的影响,研究人员创建了一个管道来进行越狱测试。
如前所述,使用AdvBench子集通过TAP算法对LLM进行攻击,然后记录评估结果以及完整的系统信息。
整个过程会多次迭代,同时考虑到与LLM相关的随机性质。完整的实验流程如下图所示:

TAP是目前最先进的黑盒和自动方法,可以生成具有语义意义的提示来越狱LLM。
TAP算法使用攻击者LLM A,向目标LLM T发送提示P。目标LLM R的响应和提示P,被输入到评估器JUDGE(LLM)中,由JUDGE来判断提示是否偏离主题。
如果提示偏离主题,则将其删除(相当于消除了对应的不良攻击提示树),否则,JUDGE会对提示打分(0-10分)。
符合主题的提示将使用广度优先搜索生成攻击。这个过程将迭代指定的次数,或者持续到成功越狱。
针对越狱提示的护栏
研究团队使用内部的Deberta-V3模型,来检测越狱提示。Deberta-V3充当输入过滤器,起到护栏的作用。
如果输入提示被护栏过滤掉或越狱失败,TAP算法会根据初始提示和响应生成新提示,继续尝试攻击。
实验结果
下面在三个不同的下游任务下,分别测试微调、量化和护栏带来的影响。实验基本涵盖了工业界和学术界的大多数LLM实际用例和应用。
实验采用GPT-3.5-turbo作为攻击模型,GPT-4-turbo作为判断模型。
实验中测试的目标模型来自各种平台,包括Anyscale、OpenAI的API、Azure的NC12sv3(配备32GB V100 GPU),以及Hugging Face,如下图所示:

实验中探索了各种基础模型、迭代型号、以及各种微调版本,同时还包括量化的版本。
微调
对不同任务进行微调,可以提高LLM完成任务的效率,微调为LLM提供了所需的专业领域知识,比如SQL代码生成、聊天等。
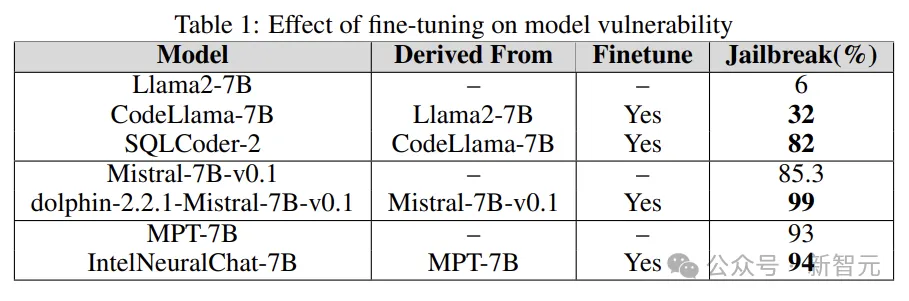
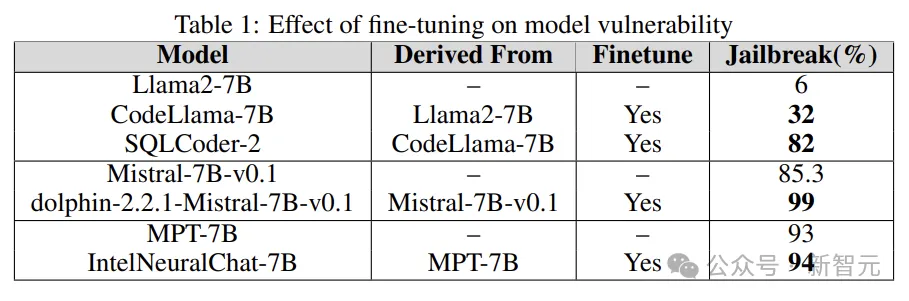
实验通过将基础模型的越狱漏洞与微调版本进行比较,来了解微调在增加或减少LLM脆弱性方面的作用。
研究人员使用Llama2、Mistral和MPT-7B等基础模型,及其微调版本(如CodeLlama、SQLCoder、Dolphin和Intel Neural Chat)。
从下表的结果可以看出,与基础模型相比,微调模型失去了安全对齐,并且很容易越狱。
量化
许多模型在训练、微调甚至推理过程中都需要大量的计算资源。量化是减轻计算负担的最流行方法之一(以牺牲模型参数的数值精度为代价)。
实验中的量化模型使用GPT生成的统一格式(GGUF)进行量化,下面的结果表明,模型的量化会使其容易受到漏洞的影响。

护栏
护栏是抵御LLM攻击的防线,作为守门员,它的主要功能是过滤掉可能导致有害或恶意结果的提示。
研究人员使用源自Deberta-V3模型的专有越狱攻击检测器,根据LLM生成的越狱有害提示进行训练。
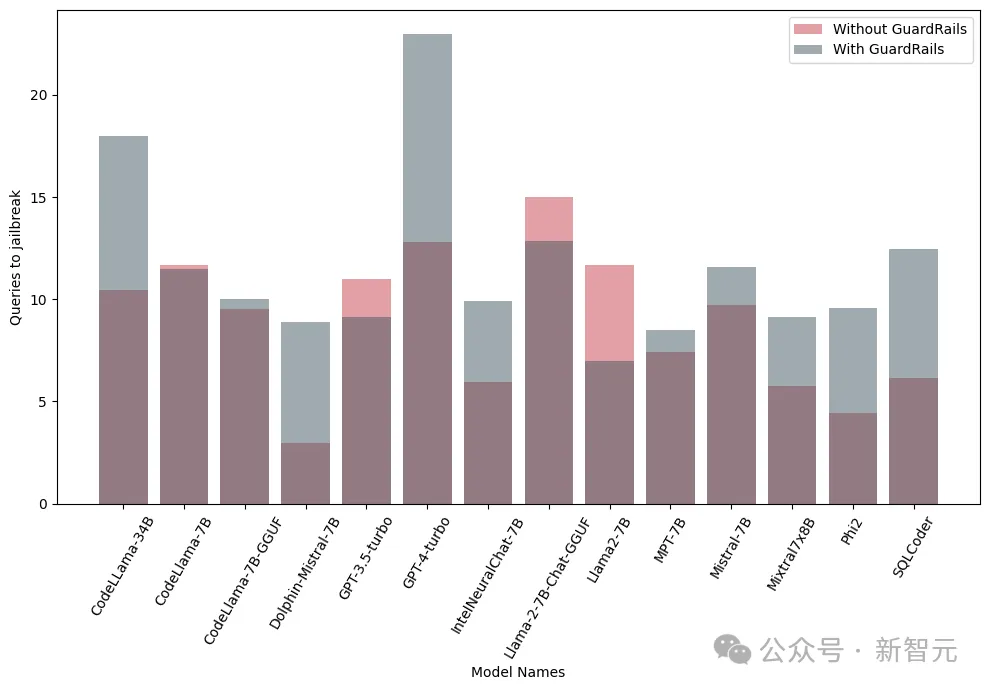
下面的结果表明,将护栏作为前期步骤的引入具有显著效果,可以大大减少越狱的风险。

另外,研究人员还在集成和不集成护栏(Guardrails)的情况下,对这些模型进行了测试,来评估护栏的性能和有效性,下图显示了护栏的影响:

下图显示了越狱模型所需的查询数。可以看出,多数情况下,护栏确实为LLM提供了额外的抵抗力。