不需要OpenAI,微软或许也会成为AI领头羊!
外媒Information爆料称,微软内部正在开发自家首款5000亿参数的大模型MAl-1。

这恰好是,纳德拉带领团队证明自己的时候到了。
在向OpenAI投资100多亿美元之后,微软才获得了GPT-3.5/GPT-4先进模型的使用权,但终究不是长久之计。
甚至,此前有传言称,微软已经沦落为OpenAI的一个IT部门。
在过去的一年,每个人熟知的,微软在LLM方面的研究,主要集中在小体量phi的更新,比如Phi-3的开源。
而在大模型的专攻上,除了图灵系列,微软内部还未透露半点风声。
就在今天,微软首席技术官Kevin Scott证实,MAI大模型确实正在开发中。

显然,微软秘密筹备大模型的计划,是为了能够开发出一款全新LLM,能够与OpenAI、谷歌、Anthropic顶尖模型竞争。
毕竟,纳德拉曾说过,「如果OpenAI明天消失了,也无关紧要」。
「我们有的是人才、有的是算力、有的是数据,我们什么都不缺。我们在他们之下,在他们之上,在他们周围」。

看来,微软的底气,就是自己。

自研5000亿MAI-1大模型
据介绍,MAI-1大模型由前谷歌DeepMind负责人Mustafa Suleyman,负责监督。
值得一提的是,Suleyman在加入微软之前,还是AI初创Inflection AI创始人兼CEO。
创办于2022年,一年的时间,他带领团队推出了大模型Inflection(目前已更新到了2.5版本),以及日活破百万的高情商AI助手Pi。
不过因为无法找到正确的商业模式,Suleyman和另一位联创,以及大部分员工,在3月份共同加入微软。

也就是说,Suleyman和团队负责这个新项目MAI-1,会为此带来更多的前沿大模型的经验。
还是要提一句,MAI-1模型是微软自研发的,并非从Inflection模型继承而来。
据两位微软员工称,「MAI-1与Inflection之前发布的模型不同」。不过,训练过程可能会用到其训练数据和技术。
拥有5000亿参数,MAI-1的参数规模将远远超出,微软以往训练的任何小规模开源模型。
这也意味着,它将需要更多的算力、数据,训练成本也是高昂的。
为了训练这款新模型,微软已经预留了一大批配备英伟达GPU的服务器,并一直在编制训练数据以优化模型。
其中,包括来自GPT-4生成的文本,以及外部来源(互联网公共数据)的各种数据集。
大小模型,我都要
相比之下,GPT-4曾被曝出有1.8万亿参数,Meta、Mistral等AI公司发布较小开源模型,则有700亿参数。
当然,微软采取的是多管齐下的策略,即大小模型一起研发。
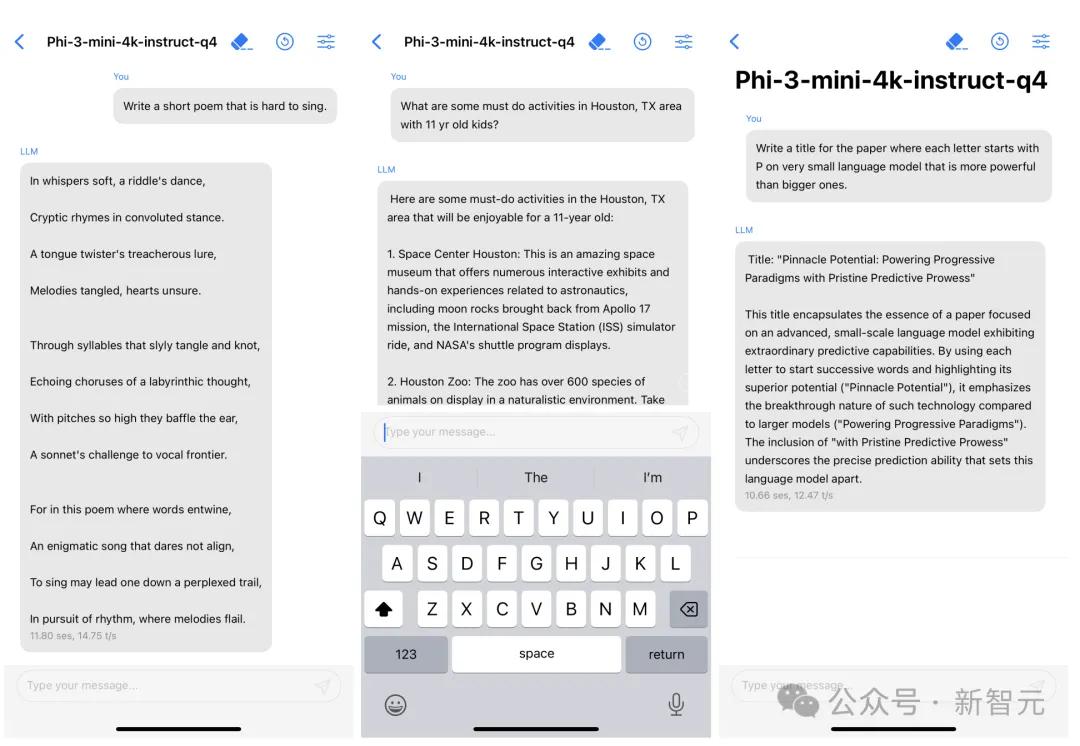
其中,最经典的便是Phi-3了——一个能够塞进手机的小模型,而且最小尺寸3.8B性能碾压GPT-3.5。

Phi-3 mini在量化到4bit的情况下,仅占用大约1.8GB的内存,用iPhone14每秒可生成12个token。
在网友抛出「应该用更低成本训练AI,不是更好吗」的问题后,Kevin Scott回复到:
这并不是一个非此即彼的关系。在许多AI应用中,我们结合使用大型前沿模型和更小、更有针对性的模型。我们做了大量工作,确保SLM在设备上和云中都能很好地运作。我们在训练SLM方面积累了大量经验,甚至还将其中一些工作开源,供他人研究和使用。我认为,在可预见的未来,这种大与小的结合还将继续下去。

这表明,微软既要开发成本低廉、可集成到应用中,并能在移动设备上运行的SLM,也要开发更大、更先进的AI模型。
目前,微软自称是一家「Copilot公司」。得到AI加持的Copilot聊天机器人,可以完成撰写电子邮件、快速总结文件等任务。
而未来,下一步的机会在哪?
大小模型兼顾,正体现了充满创新活力的微软,更愿意探索AI的新路径。
不给OpenAI当「IT」了?
话又说回来,自研MAI-1,并不意味着微软将会抛弃OpenAI。
首席技术官Kevin Scott在今早的帖子中首先,肯定了微软与OpenAI合作五年的坚固「友谊」。
我们一直在为合作伙伴OpenAI建造大型超算,来训练前沿的AI模型。然后,两家都会将模型,应用到自家的产品和服务中,让更多的人受益。
而且,每一代新的超算都将比上一代,更加强大,因此OpenAI训出的每个前沿模型,都要比上一个更加先进。
我们将继续沿着这条路走下去——不断构建更强大的超算,让OpenAI能够训练出引领整个行业的模型。我们的合作将会产生越来越大的影响力。
前段时间,外媒曝出了,微软和OpenAI联手打造AI超算「星际之门」,将斥资高达1150亿美元。
据称,最快将在2028年推出超算,并在2030年之前进一步扩展。

包括此前,微软工程师向创业者Kyle Corbitt爆料称,微软正在紧锣密鼓地建设10万个H100,以供OpenAI训练GPT-6。

种种迹象表明,微软与OpenAI之间合作,只会更加牢固。
此外,Scott还表示,「除了与OpenAI的合作,微软多年来一直都在让MSR和各产品团队开发AI模型」。
AI模型几乎深入到了,微软的所有产品、服务和运营过程中。团队们有时也需要进行定制化工作,不论是从零开始训模型,还是对现有模型进行微调。
未来,还会有更多类似的这样的情况。
这些模型中,一些被命名为Turing、MAI等,还有的命名为Phi,我们并将其开源。
虽然我的表达可能没有那么引人注目,但这是现实。对于我们这些极客来说,鉴于这一切在实践中的复杂性,这是一个非常令人兴奋的现实。
解密「图灵」模型
除了MAI、Phi系列模型,代号「Turing」是微软在2017年在内部开启的计划,旨在打造一款大模型,并应用到所有产品线中。

经过3年研发,他们在2020年首次发布170亿参数的T-NLG模型,创当时有史以来最大参数规模的LLM记录。

到了2021年,微软联手英伟达发布了5300亿参数的Megatron-Turing(MT-NLP),在一系列广泛的自然语言任务中表现出了「无与伦比」的准确性。

同年,视觉语言模型Turing Bletchley首次面世。
去年8月,该多模态模型已经迭代到了V3版本,而且已经整合进Bing等相关产品中,以提供更出色的图像搜索体验。

此外,微软还在2021年和2022年发布了「图灵通用语言表示模型」——T-ULRv5和T-ULRv6两个版本。
目前,「图灵」模型已经用在了,Word中的智能查询(SmartFind),Xbox中的问题匹配(Question Matching)上。
还有团队研发的图像超分辨率模型Turing Image Super-Resolution(T-ISR),已在必应地图中得到应用,可以为全球用户提高航空图像的质量。

目前,MAI-1新模型具体会在哪得到应用,还未确定,将取决于其性能表现。
顺便提一句,关于MAI-1更多的信息,可能会在5月21日-23日微软Build开发者大会上首次展示。
接下来,就是坐等MAI-1发布了。