当前的互联网的时代,信息爆炸的年代,抓住了风口那么距离成功也就走了一半啦!这个风口如何抓住我不知道,但是如何分析用户的喜好以及其他行为却是唾手可得的,用户的行为如何存储如何分析就是本文的下面要讲的知识点。
那么为什么要用到本文提到的hadoop组件,这里啰嗦两句,因为信息爆炸必然会带来海量的数据,那么单机服务器势必会造成存储以及计算瓶颈,那么hadoop组件就是在做这两件事情的。
hadoop之分布式存储HDFS
首先呢,这个HDFS的设计灵感来自google的GFS论文,设计的目的 就是应付海量的数据存储(PB|TB)
HDFS有如下特点:
- HDFS适合处理大规模数据,如:TB和PB,可以处理百万规模以上的文件数量,使用场景是一次写入、多次读取场景。
- HDFS将文件线性按字节切分成多个block块进行存储,每个block块默认128M。
- 每个block块默认有3个副本,提高容错性,如果一个副本丢失不可用,后续可以自动恢复。
- HDFS适合大文件写入,不适合大量小文件写入,因为小文件多NameNode要使用更多内存来维护存储文件目录和block信息。此外,读取大量小文件时,文件寻址时间要大于文件读取时间,违反HDFS设计目标。
- HDFS不支持并发写入数据,一个文件只能有一个写,不能多个线程同时写。
- HDFS数据写入后不支持修改,只支持append追加。
HDFS是一个主从(Master/Slaves)架构,由一个NameNode和一些DataNode组成,下图是HDFS架构:

HDFS 架构图
从上图看NameNode节点存储所有文件的与数据信息以及地址信息充当着目录索引的作用,SecondaryNameNode 节点则可以认为是NameNode的预备节点,DataNode节点则负责着文件以及文件副本的保存,正是有着副本以及Secondary NameNode节点的存在,保障了整个系统的高可用,下面则有一个简单的连接HDFS的例子。
hadoop之分布式计算之MapReduce
此功能的灵感同样是来自google的同名论文(牛逼的永远是写论文的呀)。
此功能模块的牛逼之处就在于它的编程思想,那么就已worldcount实例简单讲下。
假设现在有两个文件,数据如下,假如我们要读取文件中的数据进行wordcount统计,那么需要进 行如下步骤。
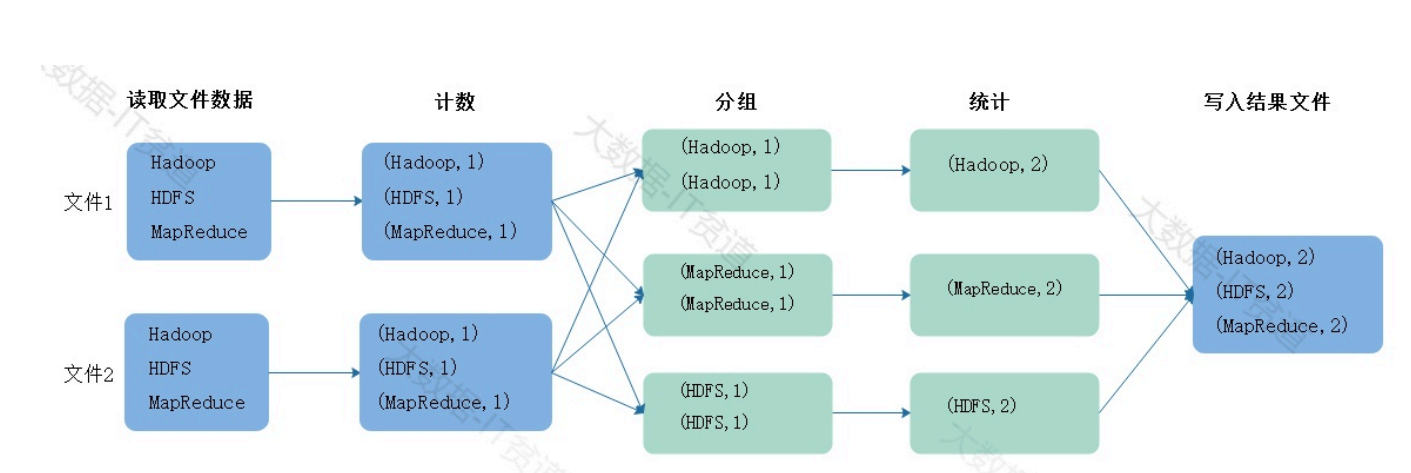
以上过程演示的就是MapReduce处理数据的大体流程,MapReduce模型由两个主要阶段组成: Map阶段和Reduce阶段:
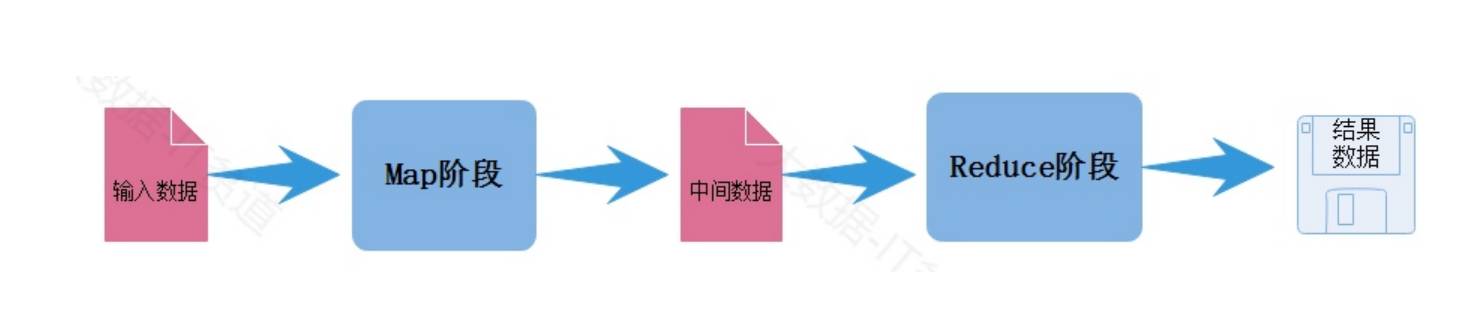
Map阶段:
在Map阶段中,输入数据被分割成若干个独立的块,并由多个Mapper任务并行处理,每个Mapper 任务都会执行用户定义的map函数,将输入数据转换成一系列键-值对的形式(Key-Value Pairs), 这些键-值对被中间存储,以供Reduce阶段使用。 Map阶段主要是对数据进行映射变换,读取一条数据可以返回一条或者多条K,V格式数据。
Reduce阶段:
在Reduce阶段中,所有具有相同键的键-值对会被分配到同一个Reducer任务上,Reducer任务会执 行用户定义的reduce函数,对相同键的值进行聚合、汇总或其他操作,生成最终的输出结果, Reduce阶段也可以由多个Reduce Task并行执行。 Reduce阶段主要对相同key的数据进行聚合,最终对相同key的数据生成一个结果,最终写出到磁盘 文件中。
下面就是一個简单的MapReduce代码示例: