LlamaIndex是一个专注于检索增强生成(RAG)的工具,可以协助您丰富大模型的数据提示。本文将用实例向您展示和介绍。
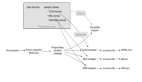
众所周知,GPT(General Pretrained Transformer)为我们描述了一套通过各种矩阵乘法,实现输入、转换和输出的循环。其中的单词(实际上是文本、声音或图像的令牌)会被转换为具有足够维度的矢量,从而表达内在意义。如下图所示,为了确保被传入的上下文是可以计算的,我们需要注意其临近的动词,并通过更多的矩阵乘法块,来移动向量,进而更接近其上下文的真正含义(例如,“黑洞”就不仅仅是一个黑暗的洞穴的含义)。

不过,GPT产品的瓶颈在于:其对于下一个词的猜测,顶多只能和输入文本语料库的水平相当。而如果我们需要向ChatGPT询问那些它尚未学习过的文本时,鉴于输入窗口的限制,我们无法将大量文本一次性塞入查询中。而此时,我们就需要用RAG来对提示进行“丰富”。
如果您使用过矢量数据库,那么一定听说过RAG,它是检索增强生成(Retrieval Augmented Generation)的缩写,是一种在无需重新训练的情况下,将新数据引入大语言模型(LLM)的方法。而LlamaIndex(https://docs.llamaindex.ai/en/stable/)则是一个专注于检索的工具,可被用来协助您“丰富”数据的提示。
开始使用LlamaIndex
如果您想直接上手LlamaIndex,其快速的开始链接--https://docs.llamaindex.ai/en/stable/getting_started/installation/,给出了“5行代码”入手法。
在Mac上,我选择使用Visual Studio Code来安装并运行Python 3。为此,我会打开一个Warp终端,并输入如下命令:
完成后,我们可以通过如下截图予以确认:

接着,我会在该空文件夹中启动Visual Studio 。在安装了Python扩展后,我使用Python来创建环境,即:从命令面板(Palette)中创建了一个特定于项目的虚拟环境。然后,我选择了Venv,并最后确认了自己正在使用的是刚刚安装好的Python:

根据LlamaIndex的说明,我们需要在Visual Studio Code的虚拟环境中,使用pip安装lama-index包(注意,是在活动终端而非Warp中):


下面,我需要向环境出示自己的OpenAI密钥。鉴于在IDE下运行的虚拟环境的特性,我们将其粘贴在Visual Studio Code运行项目所制作的launch.json文件中,是最安全的(当然,您可能需要创建一个OpenAI帐户。):
按照LlamaIndex开始教程中的建议,我从链接--https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/paul_graham/paul_graham_essay.txt下载并放置了一个名为data的文件夹,其中包含了一本冗长的传记。
在Visual Studio代码中,我创建了一个starter.py文件,其内容如下:
可见,就算您对Python并无深入的了解,也能依靠llama_index软件包构建出大部分代码。下面展示的是它对于查询的回复:

为了确认我确实调用了OpenAI,以下便是我帐户活动的统计数据:

那么,这段代码到底能做什么呢?它会将新的文本嵌入到矢量存储中,并通过调用VectorStoreIndex以便在查询时提供检索,并在调用进入GPT-3.5之前,以英语形式添加到上下文的窗口中。这便是我在前文中提到的对提示进行“丰富”的实践。
通过添加两行日志代码,我既能够提取大量密集的REST调用,也可以从llama_index包中提取如下实用的提示:
据此,我们可以了解到其后台发生的调用与变化了。
在完成之前,我会在data文件夹中添加另一个文档:莎士比亚的《十四行诗》。虽然我无法保障LLM已经有所“知晓”,但是显然这一堆诗并不会构成具有实际意义的叙事。

据此,我将使用一个故意模糊的问题,来运行如下额外的查询:
就此,我得到的简短回答是:
是不是非常有趣?在后台,llama_index包“捕获”的是这十四行诗中提到Adonis的如下区域:
“你是被祝福的,你的价值给了你机会,你必须胜利,虽然缺乏希望。你的本质是什么?你是由什么构成的?既然每个人都有自己的影子,而你也有自己的那个。不过,每个影子都能借来指代Adonis和其赝品,也就是去模仿你。在Helen的脸颊上,所有美丽的艺术,就像你在希腊的轮胎上涂上了新的颜色。虽说是春天,但一年后仍会腐朽。一个是你美丽的影子,另一个则是你的慷慨,你是我们所知道的每一个幸福的该有的形状。”
就像我们之前看到的日志节点那样,我也截获到了如下节点信息:
可见,其中大部分出自十四行诗的第53节。“blessed”一词确实出现在“Adonis”的附近。
当然,对于表现足够好的LlamaIndex来说,这些都不是问题。我刚刚使用了构建管道的第一步,LlamaIndex后续会为您提供更多的、以这类方式处理文档的解释。
小结
目前,虽然我们仍然缺乏一种全面的语言来描述模型内部发生的事情,但是通过LlamaIndex使用的RAG不乏一种可靠的途径。它既可以增强针对特定领域信息的大语言模型,也可以确保处理结果的可验证性。而这一切都旨在减少错误应答的可能,而这正是当前困扰人工智能的典型问题。
译者介绍
陈峻(Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。
原文标题:A Developer’s Guide to Getting Started with LlamaIndex,作者:David Eastman
链接:https://thenewstack.io/a-developers-guide-to-getting-started-with-llamaindex/。