














CubeFS 是一种新一代云原生存储系统,支持 S3、HDFS 和 POSIX 等访问协议,支持多副本与纠删码两种存储引擎,为用户提供多租户、 多 AZ 部署以及跨区域复制等多种特性。
CubeFS 作为一个云原生的分布式存储平台,提供了多种访问协议,因此其应用场景也非常广泛,下面简单介绍几种比较典型的应用场景
- 大数据分析:兼容 HDFS 协议,为 Hadoop 生态(如 Spark、Hive)提供统一存储底座,为计算引擎提供无限的存储空间以及大带宽的数据存储能力。
- 深度训练/机器学习:作为分布式并行文件系统,支撑 AI 训练、模型存储及分发、IO 加速等需求。
- 容器共享存储:容器集群可以将容器镜像的配置文件或初始化加载数据存储在 CubeFS 上,在容器批量加载时实时读取。多 Pod 间通过 CubeFS 共享持久化数据,在 Pod 故障时可以进行快速故障切换。
- 数据库&中间件:为数据库应用如 MySQL、ElasticSearch、ClickHouse 提供高并发、低时延云盘服务,实现彻底的存算分离。
- 在线服务:为在线业务(如广告、点击流、搜索)或终端用户的图、文、音视频等内容提供高可靠、低成本的对象存储服务。
- 传统 NAS 上云:替换线下传统本地存储及 NAS,助力 IT 业务上云。
特性
CubeFS 具有众多特性,包括:
多协议
兼容 S3、POSIX、HDFS 等多种访问协议,协议间访问可互通
- POSIX 兼容:兼容 POSIX 接口,让上层应用的开发变得极其简单,就跟使用本地文件系统一样便捷。此外,CubeFS 在实现时放松了对 POSIX 语义的一致性要求来兼顾文件和元文件操作的性能。
- 对象存储兼容:兼容 AWS 的 S3 对象存储协议,用户可以使用原生的 Amazon S3 SDK 管理 CubeFS 中的资源。
- Hadoop 协议兼容:兼容 Hadoop FileSystem 接口协议,用户可以使用 CubeFS 来替换 HDFS,做到上层业务无感。
双引擎
支持多副本及纠删码两种引擎,用户可以根据业务场景灵活选择
- 多副本存储引擎:副本之间的数据为镜像关系,通过强一致的复制协议来保证副本之间的数据一致性,用户可以根据应用场景灵活的配置不同副本数。
- 纠删码存储引擎:纠删码引擎具备高可靠、高可用、低成本、支持超大规模(EB)的特性,根据不同 AZ 模型可以灵活选择纠删码模式。
多租户
支持多租户管理,提供细粒度的租户隔离策略
可扩展
可以轻松构建 PB 或者 EB 级规模的分布式存储服务,各模块可水平扩展
高性能
支持多级缓存,针对小文件特定优化,支持多种高性能的复制协议
- 元数据管理:元数据集群为内存元数据存储,在设计上使用两个 B-Tree(inodeBTree 与 dentryBTree)来管理索引,进而提升元数据访问性能;
- 强一致副本协议 :CubeFS 根据文件写入方式的不同采用不同的复制协议来保证副本间的数据一致性。(如果文件按照顺序写入,则会使用主备复制协议来优化 IO 吞吐量;如果是随机写入覆盖现有文件内容时,则是采用一种基于 Multi-Raft 的复制协议,来确保数据的强一致性);
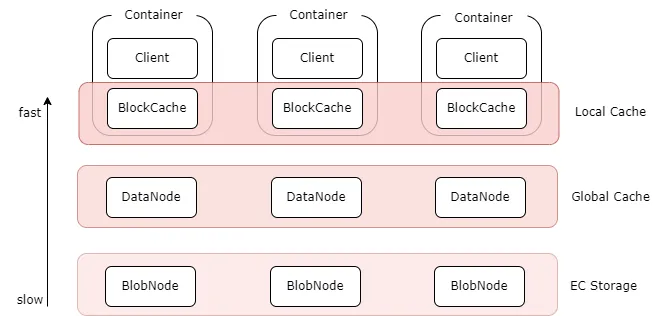
- 多级缓存:纠删码卷支持多级缓存加速能力,针对热点数据,提供更高数据访问性能:
- 本地缓存:可以在 Client 机器上同机部署 BlockCache 组件,将本地磁盘作为本地缓存. 可以不经过网络直接读取本地 Cache, 但容量受本地磁盘限制;
- 全局缓存:使用副本组件 DataNode 搭建的分布式全局 Cache, 比如可以通过部署客户端同机房的 SSD 磁盘的 DataNode 作为全局 cache, 相对于本地 cache, 需要经过网络, 但是容量更大, 可动态扩缩容,副本数可调。
云原生
基于 CSI 插件可以快速地在 Kubernetes 上使用 CubeFS。
整体架构
整体上 CubeFS 由元数据子系统(Metadata Subsystem)、数据子系统(Data Subsystem)和资源管理节点(Master)以及对象网关(Object Subsystem)组成,可以通过 POSIX/HDFS/S3 接口访问存储数据。
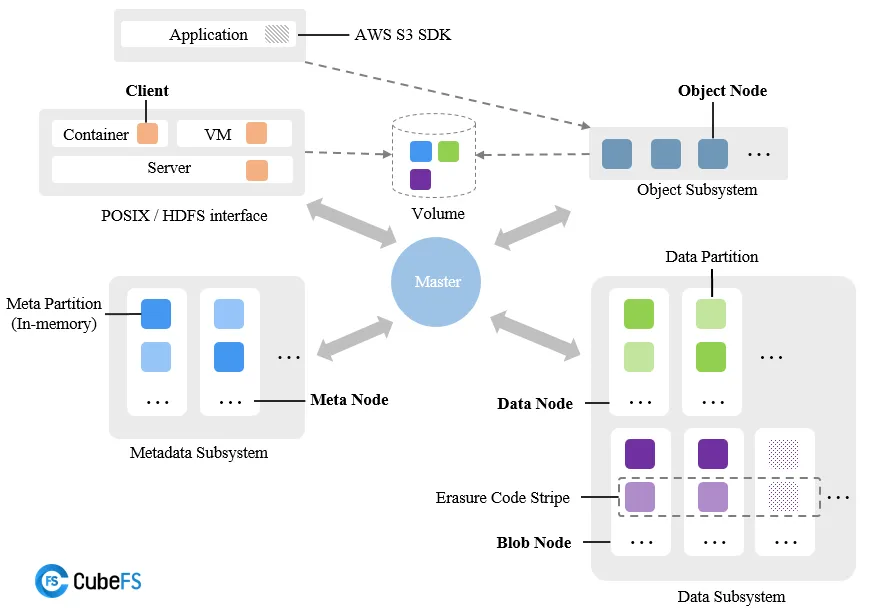
资源管理节点
由多个 Master 节点组成,负责异步处理不同类型的任务,如管理数据分片与元数据分片(包括创建、删除、更新以及一致性检查等),检查数据节点或者元数据节点的健康状态,维护管理卷信息等
Master 节点可以有多个,节点之间通过 Raft 算法保证元数据的一致性,并且持久化到
RocksDB中。
元数据子系统
由多个 Meta Node 节点组成,多个元数据分片(Meta Partition)和 Raft 实例(基于 Multi-Raft 复制协议)组成,每个元数据分片表示一个 Inode 范围元数据,其中包含两棵内存 B-Tree 树:inode BTree 与 dentry BTree。
元数据实例最少需要 3 个,支持水平扩容。
数据子系统
分为副本子系统和纠删码子系统,两种子系统可同时存在,也都可单独存在:
- 副本子系统由 DataNode 组成,每个节点管理一组数据分片,多个节点的数据分片构成一个副本组;
- 纠删码子系统(Blobstore)主要由 BlobNode 模块组成,每个节点管理一组数据块,多个节点的数据块构成一个纠删码条带。
数据节点支持水平扩容。
对象子系统
由对象节点(ObjectNode)组成,提供了兼容标准 S3 语义的访问协议,可以通过 Amazon S3 SDK 或者是 s3cmd 等工具访问存储资源。
卷
逻辑上的概念,由多个元数据和数据分片组成,从客户端的角度看,卷可以被看作是可被容器访问的文件系统实例。从对象存储的角度来看,一个卷对应着一个 bucket。一个卷可以在多个容器中挂载,使得文件可以被不同客户端同时访问。
安装
CubeFS 的安装方式有很多,包括 Docker、YUM 等等,由于我们这里直接直接在 Kubernetes 上使用,因此我们可以通过 Helm 来安装 CubeFS,各组件会直接使用宿主机网络,使用 hostPath 将磁盘映射到容器中。
在 Kubernetes 集群中部署 CubeFS 可以按照下图所示的架构进行部署:

CubeFS 目前由这四部分组成:
- Master:资源管理节点,负责维护整个集群的元信息,部署为 StatefulSet 资源。
- DataNode:数据存储节点,需要挂载大量磁盘负责文件数据的实际存储,部署为 DaemonSet 资源。
- MetaNode:元数据节点,负责存储所有的文件元信息,部署为 DaemonSet 资源。
- ObjectNode:负责提供转换 S3 协议提供对象存储的能力,无状态服务,部署为 Deployment 资源。
在部署之前,我们需要拥有一个至少有 3 个节点(最好 4 个以上,可以容灾)的 Kubernetes 集群,且集群版本需要大于等于 1.15。
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane 46d v1.28.7
node1 Ready <none> 46d v1.28.7
node2 Ready <none> 46d v1.28.7首先我们需要给节点打上各自的标签,标明这台机器要在 CubeFS 集群中承担的角色:
由于我们这里只有 3 个节点,所以需要这些节点承担一些共同的角色。
- Master 节点,至少三个,建议为奇数个:
kubectl label node master component.cubefs.io/master=enabled
kubectl label node node1 component.cubefs.io/master=enabled
kubectl label node node2 component.cubefs.io/master=enabled- MetaNode 元数据节点,至少 3 个,奇偶无所谓:
kubectl label node master component.cubefs.io/metanode=enabled
kubectl label node node1 component.cubefs.io/metanode=enabled
kubectl label node node2 component.cubefs.io/metanode=enabled- Datanode 数据节点,至少 3 个,奇偶无所谓:
kubectl label node master component.cubefs.io/datanode=enabled
kubectl label node node1 component.cubefs.io/datanode=enabled
kubectl label node node2 component.cubefs.io/datanode=enabled- ObjectNode 对象存储节点,可以按需进行标记,不需要对象存储功能的话也可以不部署这个组件:
kubectl label node node1 component.cubefs.io/objectnode=enabled
kubectl label node node2 component.cubefs.io/objectnode=enabled- CSI 组件,用于在 Kubernetes 中使用 CubeFS,需要在所有节点上部署:
kubectl label node node1 component.cubefs.io/csi=enabled
kubectl label node node2 component.cubefs.io/csi=enabledCubeFS 安装时会根据这些标签通过 nodeSelector 进行匹配,然后在机器创建起对应的 Pod。
接下来我们就可以通过 Helm 来安装 CubeFS 了,首先我们需要将 CubeFS 的 Helm Chart 下载到本地:
git clone https://github.com/cubefs/cubefs-helm
cd cubefs-helm然后根据自身环境定制 values 文件,比如下面是一个简单的 values 文件:
# cubefs-values.yaml
component:
master: true
datanode: true
metanode: true
objectnode: false
client: false
csi: true
monitor: false
ingress: true
image:
# 3.3.0 版本之前会出现 /lib64/libstdc++.so.6: version `GLIBCXX_3.4.21' not found 错误
server: cubefs/cfs-server:v3.3.0
client: cubefs/cfs-client:v3.3.0
csi_driver: cnych/cubefs-cfs-csi-driver:3.2.0.150.0
csi_provisioner: cnych/csi-provisioner:v2.2.2
csi_attacher: cnych/csi-attacher:v3.4.0
csi_resizer: cnych/csi-resizer:v1.3.0
driver_registrar: cnych/csi-node-driver-registrar:v2.5.0
master:
# The replicas of master component, at least 3, recommend to be an odd number
replicas: 3
tolerations:
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
effect: "NoSchedule"
resources:
enabled: true
requests:
memory: "512Mi"
cpu: "500m"
limits:
memory: "512Mi"
cpu: "500m"
metanode:
total_mem: "4000000000"
tolerations:
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
effect: "NoSchedule"
resources:
enabled: true
requests:
memory: "512Mi"
cpu: "500m"
limits:
memory: "512Mi"
cpu: "500m"
datanode:
# DataNode 要使用的磁盘,可以挂载多块
# 格式: 挂载点:保留的空间
# 保留的空间: 单位字节,当磁盘剩余空间小于该值时将不会再在该磁盘上写入数据
disks:
- /data0:10000000000
tolerations:
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
effect: "NoSchedule"
resources:
enabled: true
requests:
memory: "512Mi"
cpu: "500m"
limits:
memory: "512Mi"
cpu: "500m"
csi:
driverName: csi.cubefs.com
logLevel: error
kubeletPath: /var/lib/kubelet
controller:
tolerations: []
nodeSelector:
component.cubefs.io/csi: "enabled"
node:
tolerations: []
nodeSelector:
component.cubefs.io/csi: "enabled"
resources:
enabled: true
requests:
memory: "512Mi"
cpu: "500m"
limits:
memory: "512Mi"
cpu: "500m"
storageClass:
setToDefault: false
reclaimPolicy: "Delete"
# CSI 客户端配置
provisioner:
# Kubelet 的主目录
kubelet_path: /var/lib/kubelet然后使用如下命令进行 CubeFS 部署:
helm upgrade --install cubefs -n cubefs-system ./cubefs-helm/cubefs -f cubefs-values.yaml --create-namespace部署完成后可以使用命令 kubectl get pods -n cubefs-system 等待所有组件状态变为 Running 即可:
$ kubectl get pods -n cubefs-system
NAME READY STATUS RESTARTS AGE
cfs-csi-controller-66cdbb664f-pqkp6 4/4 Running 0 28m
cfs-csi-node-966t9 2/2 Running 0 25m
cfs-csi-node-9f4ts 2/2 Running 0 25m
datanode-4zfhc 1/1 Running 0 28m
datanode-blc8w 1/1 Running 0 28m
datanode-ldj72 1/1 Running 0 28m
master-0 1/1 Running 0 28m
master-1 1/1 Running 0 23m
master-2 1/1 Running 0 23m
metanode-5csgt 1/1 Running 0 7m31s
metanode-jvqnl 1/1 Running 0 7m31s
metanode-vpjtj 1/1 Running 0 7m31s各个组件的关键日志会在容器标准输出中输出。
此外还会自动创建一个 StorageClass 对象,可以通过 kubectl get sc 查看:
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
cfs-sc csi.cubefs.com Delete Immediate true 29m测试
现在我们有了一个可用的 StorageClass 对象了,接下来可以创建一个 PVC 对象来测试 CubeFS 的存储功能。如下所示:
# cubefs-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cubefs-pvc
namespace: default
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: cfs-sc上面的 PVC 对象中我们通过 storageClassName 指定了使用的 StorageClass 名称,这里是 cfs-sc,这个名称需要和我们之前创建的 StorageClass 名称一致,这样就会根据 cubefs-sc 中定义的参数来创建存储卷。当我们在编写 pvc yaml 主要注意一下参数:
- metadata.name:pvc 的名称,可以按需修改,同一个 namespace 下 pvc 名称是唯一的,不允许有两个相同的名称。
- metadata.namespace:pvc 所在的命名空间,按需修改
- spec.resources.request.storage:pvc 容量大小。
- storageClassName:这是 storage class 的名称。如果想知道当前集群有哪些 storageclass,可以通过命令 kubectl get sc 来查看。
这里直接应用这个 yaml 文件即可:
kubectl apply -f cubefs-pvc.yaml执行命令完成后,可以通过命令 kubectl get pvc -n 命名空间 来查看对应 pvc 的状态,Pending 代表正在等待,Bound 代表创建成功。
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
cubefs-pvc Bound pvc-53cc95b7-8a05-43f8-8903-f1c6f7b11c05 5Gi RWO cfs-sc 3s如果 PVC 的状态一直处于 Pending,可以通过命令查看原因:
kubectl describe pvc -n 命名空间 PVC 名称如果报错消息不明显或者看不出错误,则可以使用 kubectl logs 相关命令先查看 csi controller pod 里面的 csi-provisioner 容器的报错信息,csi-provisioner 是 k8s 与 csi driver 的中间桥梁,很多信息都可以在这里的日志查看。
如果 csi-provisioner 的日志还看不出具体问题,则使用 kubectl exec 相关命令查看 csi controller pod 里面的 cfs-driver 容器的日志,它的日志放在容器里面的 /cfs/logs 下。
这里不能使用 Kubectl logs 相关命令是因为 cfs-driver 的日志并不是打印到标准输出,而其它几个类似 csi-provisioner 的 sidecar 容器的日志是打印到标准输出的,所以可以使用 kubectl logs 相关命令查看。
有了 PVC 则接下来就可以在应用中挂载到指定目录了,比如我们这里有一个如下所示的示例:
# cfs-csi-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: cfs-csi-demo
namespace: default
spec:
selector:
matchLabels:
app: cfs-csi-demo-pod
template:
metadata:
labels:
app: cfs-csi-demo-pod
spec:
nodeSelector:
component.cubefs.io/csi: enabled
containers:
- name: cfs-csi-demo
image: nginx:1.17.9
imagePullPolicy: "IfNotPresent"
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
mountPropagation: HostToContainer
name: mypvc
volumes:
- name: mypvc
persistentVolumeClaim:
claimName: cubefs-pvc上面的资源清单中我们将一个名称为 cubefs-pvc 的 PVC 挂载到 cfs-csi-demo 容器里面的 /usr/share/nginx/html 下。
同样直接创建这个资源清单即可:
kubectl apply -f cfs-csi-demo.yaml创建完成后可以通过 kubectl get pods 查看 Pod 的状态:
$ kubectl get pods -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cfs-csi-demo-5d456c8d97-sjsvw 1/1 Running 0 78s 10.0.1.85 node1 <none> <none>我们可以直接通过往 /usr/share/nginx/html 目录写入文件来测试 CubeFS 的存储功能:
$ kubectl exec -it cfs-csi-demo-5d456c8d97-sjsvw -- /bin/bash
root@cfs-csi-demo-5d456c8d97-sjsvw:/# echo "Hello, CubeFS" > /usr/share/nginx/html/index.html
root@cfs-csi-demo-5d456c8d97-sjsvw:/#然后我们可以将这个 Pod 删除重建,然后查看是否还有这个文件:
$ kubectl delete pod cfs-csi-demo-5d456c8d97-sjsvw
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
cfs-csi-demo-5d456c8d97-c245z 1/1 Running 0 3m22s
$ kubectl exec -it cfs-csi-demo-5d456c8d97-c245z -- ls /usr/share/nginx/html
index.html
$ kubectl exec -it cfs-csi-demo-5d456c8d97-c245z -- cat /usr/share/nginx/html/index.html
Hello, CubeFS如果能够看到 Hello, CubeFS 则说明 CubeFS 的存储功能正常。
















