












机器如何能像人类和动物一样高效地学习?机器如何学习世界运作方式并获得常识?机器如何学习推理和规划……
当一系列问题被提出时,有人回答自回归 LLM 足以胜任。
然而,知名 AI 学者、图灵奖得主 Yann LeCun 并不这么认为,他一直唱衰自回归 LLM。近日 LeCun 在哈佛大学的演讲内容深入探讨了这些问题,内容长达 95 页,可谓干货满满。
LeCun 给出了一个模块化的认知架构,它可能构成回答这些问题的途径。该架构的核心是一个可预测的世界模型,它允许系统预测其行动的后果,并规划一系列行动来优化一组目标。
目标包括保证系统可控性和安全性的护栏。世界模型采用了经过自监督学习训练的分层联合嵌入预测架构(H-JEPA)。
- PPT 链接:https://drive.google.com/file/d/1Ymx_LCVzy7vZXalrVHPXjX9qbpd9k_bo/view?pli=1
- 视频地址 https://www.youtube.com/watch?v=MiqLoAZFRSE
LeCun 的演讲围绕多方面展开。
开始部分,LeCun 介绍了目标驱动的人工智能。LeCun 指出与人类、动物相比,机器学习真的烂透了,一个青少年可以在大约 20 小时的练习中学会开车,小朋友可以在几分钟内学会清理餐桌。
相比之下,为了可靠,当前的 ML 系统需要通过大量试验进行训练,以便在训练期间可以覆盖最意外的情况。尽管如此,最好的 ML 系统在现实世界任务(例如驾驶)中仍远未达到人类可靠性。
我们距离达到人类水平的人工智能还差得很远,需要几年甚至几十年的时间。在实现这一目标之前,或许会先实现拥有猫类(或者狗类)级别智能的 AI。LeCun 强调 AI 系统应该朝着能够学习、记忆、推理、规划、有常识、可操纵且安全的方向发展。
LeCun 再一次表达了对自回归 LLM 的不满(从 ChatGPT 到 Sora,OpenAI 都是采用的自回归生成式路线),虽然这种技术路线已经充斥了整个 AI 界,但存在事实错误、逻辑错误、不一致、推理有限、毒性等缺陷。此外,自回归 LLM 对潜在现实的了解有限,缺乏常识,没有记忆,而且无法规划答案。
在他看来,自回归 LLM 仅仅是世界模型的一种简化的特殊情况。为了实现世界模型,LeCun 给出的解决方案是联合嵌入预测架构(JEPA)。
LeCun 花了大量篇幅介绍 JEPA 相关技术,最后他给出了简单的总结:放弃生成模型,支持联合嵌入架构;放弃概率模型,支持基于能量的模型(EBM);放弃对比方法,支持正则化方法;放弃强化学习,支持模型 - 预测控制;仅当规划无法产生结果时才使用强化学习来调整世界模型。
在开源问题上,LeCun 认为开源 AI 不应该因为监管而消失,人工智能平台应该是开源的,否则,技术将被几家公司所掌控。不过为了安全起见,大家还是需要设置共享护栏目标。
对于 AGI,LeCun 认为根本不存在 AGI,因为智能是高度多维的。虽然现在 AI 只在一些狭窄的领域超越了人类,毫无疑问的是,机器最终将超越人类智能。

机器学习烂透了,距离人类水平的 AI 还差得远
LeCun 指出 AI 系统应该朝着能够学习、记忆、推理、规划、有常识、可操纵且安全的方向发展。在他看来,与人类和动物相比,机器学习真的烂透了,LeCun 指出如下原因:
- 监督学习(SL)需要大量标注样本;
- 强化学习(RL)需要大量的试验;
- 自监督学习(SSL)效果很好,但生成结果仅适用于文本和其他离散模式。
与此不同的是,动物和人类可以很快地学习新任务、了解世界如何运作,并且他们(人类和动物)都有常识。

随后,LeCun 表示人类需要的 AI 智能助理需要达到人类级别。但是,我们今天距离人类水平的人工智能还差得很远。
举例来说,17 岁的少年可以通过 20 小时的训练学会驾驶(但 AI 仍然没有无限制的 L5 级自动驾驶),10 岁的孩子可以在几分钟内学会清理餐桌,但是现在的 AI 系统还远未达到。现阶段,莫拉维克悖论不断上演,对人类来说很容易的事情对人工智能来说很难,反之亦然。
那么,我们想要达到高级机器智能(Advanced Machine Intelligence,AMI),需要做到如下:
- 从感官输入中学习世界模型的 AI 系统;
- 具有持久记忆的系统;
- 具有规划行动的系统;
- 可控和安全的系统;
- 目标驱动的 AI 架构(LeCun 重点强调了这一条)。

自回归 LLM 糟糕透了
自监督学习已经被广泛用于理解和生成文本,图像,视频,3D 模型,语音,蛋白质等。大家熟悉的研究包括去噪 Auto-Encoder、BERT、RoBERTa。

LeCun 接着介绍了生成式 AI 和自回归大语言模型。自回归生成架构如下所示:
 自回归大语言模型(AR-LLM)参数量从 1B 到 500B 不等、训练数据从 1 到 2 万亿 token。ChatGPT、Gemini 等大家熟悉的模型都是采用这种架构。
自回归大语言模型(AR-LLM)参数量从 1B 到 500B 不等、训练数据从 1 到 2 万亿 token。ChatGPT、Gemini 等大家熟悉的模型都是采用这种架构。
LeCun 认为虽然这些模型表现惊人,但它们经常出现愚蠢的错误,比如事实错误、逻辑错误、不一致、推理有限、毒性等。此外,LLM 对潜在现实的了解有限,缺乏常识,没有记忆,而且无法规划答案。

LeCun 进一步指出自回归 LLM 很糟糕,注定要失败。这些模型不可控、呈指数发散,并且这种缺陷很难修复。

此外,自回归 LLM 没有规划,充其量就是大脑中的一小部分区域。

虽然自回归 LLM 在协助写作、初稿生成、文本润色、编程等方面表现出色。但它们经常会出现幻觉,并且在推理、规划、数学等方面表现不佳,需要借助外部工具才能完成任务。用户很容易被 LLM 生成的答案所迷惑,此外自回归 LLM 也不知道世界是如何运转的。

LeCun 认为当前 AI 技术(仍然)距离人类水平还很远,机器不会像动物和人类那样学习世界的运作方式。目前看来自回归 LLM 无法接近人类智力水平,尽管 AI 在某些狭窄的领域超过了人类。但毫无疑问的是,最终机器将在所有领域超越人类智慧。

目标驱动的 AI
在 LeCun 看来,目标驱动的 AI 即自主智能(autonomous intelligence)是一个很好的解决方案,其包括多个配置,一些模块可以即时配置,它们的具体功能由配置器(configurator)模块确定。
配置器的作用是执行控制:给定要执行的任务,它预先配置针对当前任务的感知(perception)、世界模型(world model)、成本(cost)和参与者(actor)。
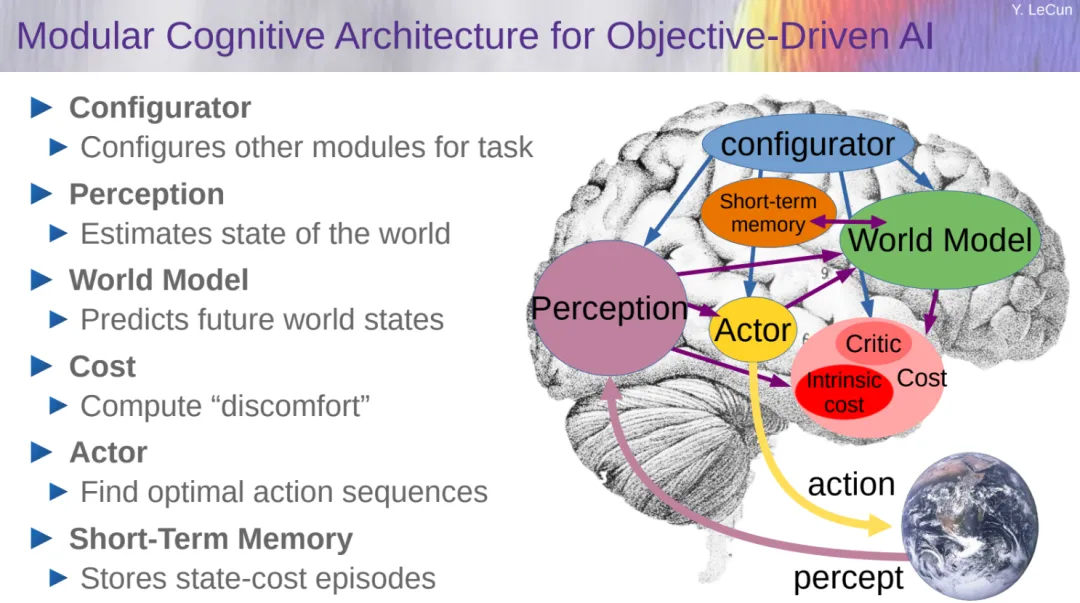

目标驱动的 AI 中最复杂的部分是世界模型的设计。
设计和训练世界模型
关于这部分内容,我们先看 LeCun 给出的建议:
- 放弃生成模型,支持联合嵌入架构;
- 放弃概率模型,支持基于能量的模型(EBM);
- 放弃对比方法,支持正则化方法;
- 放弃强化学习,支持模型 - 预测控制;
- 仅当规划无法产生结果时才使用强化学习来调整世界模型。

LeCun 指出生成架构不适用于图像任务,未来几十年阻碍人工智能发展的真正障碍是为世界模型设计架构以及训练范式。
训练世界模型是自监督学习(SSL)中的一个典型例子,其基本思想是模式补全。对未来输入(或暂时未观察到的输入)的预测是模式补全的一个特例。在这项工作中,世界模型旨在预测世界状态未来表征。

联合嵌入预测架构(JEPA)
LeCun 给出的解决方案是联合嵌入预测架构(JEPA),他介绍了联合嵌入世界模型。

LeCun 进一步给出了生成模型和联合嵌入的对比:
- 生成式:预测 y(包含所有细节);
- 联合嵌入:预测 y 的抽象表示。
LeCun 强调 JEPA 不是生成式的,因为它不能轻易地用于从 x 预测 y。它仅捕获 x 和 y 之间的依赖关系,而不显式生成 y 的预测。下图显示了一个通用 JEPA 和生成模型的对比。

LeCun 认为动物大脑的运行可以看作是对现实世界的模拟,他称之为世界模型。他表示,婴儿在出生后的头几个月通过观察世界来学习基础知识。观察一个小球掉几百次,普通婴儿就算不了解物理,也会对重力的存在与运作有基础认知。
LeCun 表示他已经建立了世界模型的早期版本,可以进行基本的物体识别,并正致力于训练它做出预测。

基于能量的模型(通过能量函数获取依赖关系)
演讲中还介绍了一种基于能量的模型(EBM)架构,如图所示,数据点是黑点,能量函数在数据点周围产生低能量值,并在远离高数据密度区域的地方产生较高能量,如能量等高线所示。

训练 EBM 有两类方法:对比方法和正则化方法,前者对维度扩展非常糟糕,

下图是 EBM 与概率模型的比较,可以得出概率模型只是 EBM 的一个特例。为什么选择 EBM 而不是概率模型,LeCun 表示 EBM 在评分函数的选择上提供了更大的灵活性;学习目标函数的选择也更加灵活。因而 LeCun 更加支持 EBM。

对比方法 VS 正则化方法:

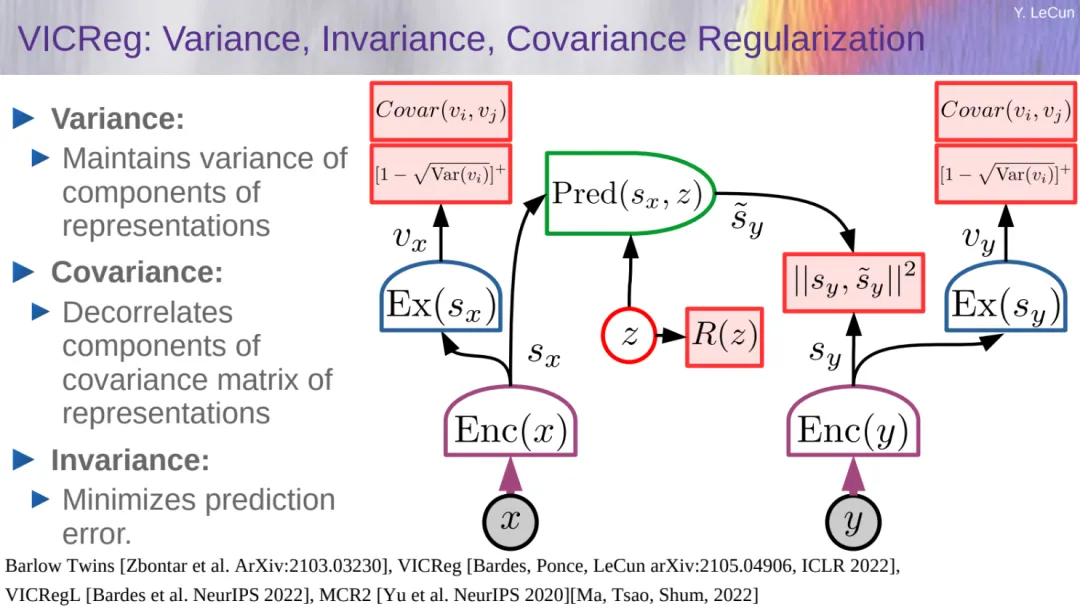
接着 LeCun 介绍了他们在 ICLR 2022 上提出的 VICReg 方法,这是一种基于方差 - 协方差正则化的自监督学习方法,通过约束嵌入空间中样本的方差和协方差,使得模型能够学习到更具代表性的特征。
相较于传统的自监督学习方法,VICReg 在特征提取和表示学习方面表现更好,为自监督学习领域带来了新的突破。
此外,LeCun 还花了大量篇幅介绍 Image-JEPA、Video-JEPA 方法及性能,感兴趣的读者可以自行查看。

最后,LeCun 表示他们正在做的事情包括使用 SSL 训练的分层视频 JEPA(Hierarchical Video-JEPA),从视频中进行自监督学习;对目标驱动的 LLM 进行推理和规划,实现这一步需要在表示空间中规划并使用 AR-LLM 将表示转换为文本的对话系统;学习分层规划,就 toy 规划问题对多时间尺度的 H-JEPA 进行训练。
感兴趣的读者可以查看原始 PPT 来学习。

















