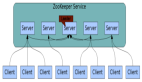
一、分布式锁的概念与原理
分布式锁是一种在分布式系统中控制对共享资源的并发访问的技术。在多个进程或线程需要访问和修改共享数据时,为了避免数据不一致的问题,需要使用锁来确保同一时间只有一个操作能够执行。在单一系统内部,这通常通过线程锁或进程锁来实现,但在分布式系统中,这些传统的锁机制无法工作,因此需要分布式锁。
二、在.NET框架中使用数据库实现分布式锁
在.NET中实现分布式锁的一种常见方法是利用数据库的事务和唯一约束。以下是一个使用System.Data.SqlClient的简单示例:
- 创建锁表:在数据库中创建一个表,用于记录锁信息。该表至少包含以下字段:锁名称、持有者信息、获取锁的时间等。
- 获取锁:为了获取锁,可以插入一条记录到锁表中。如果插入成功,则表示获取到了锁;如果插入失败(例如,因为违反了唯一约束),则表示锁已被其他进程持有。
using (var connection = new SqlConnection(connectionString))
{
connection.Open();
using (var transaction = connection.BeginTransaction())
{
try
{
using (var command = connection.CreateCommand())
{
command.Transaction = transaction;
command.CommandText = "INSERT INTO Locks (LockName, Holder, AcquiredAt) VALUES (@LockName, @Holder, GETDATE())";
// 添加参数并执行命令...
int result = command.ExecuteNonQuery();
if (result > 0)
{
// 成功获取锁
transaction.Commit();
}
else
{
// 未能获取锁,进行回滚或其他处理
transaction.Rollback();
}
}
}
catch (SqlException ex)
{
// 处理异常,例如唯一约束违反等
transaction.Rollback();
}
}
}- 释放锁:当完成共享资源的访问后,需要从锁表中删除相应的记录以释放锁。
using (var connection = new SqlConnection(connectionString))
{
connection.Open();
using (var command = connection.CreateCommand())
{
command.CommandText = "DELETE FROM Locks WHERE LockName = @LockName AND Holder = @Holder";
// 添加参数并执行命令...
command.ExecuteNonQuery();
}
}三、分布式锁的优势与挑战
优势:
- 实现了跨进程、跨服务器的资源共享控制。
- 利用数据库的事务特性,确保了锁的一致性和可靠性。
- 可以方便地实现锁的超时和续期机制。
挑战:
- 数据库可能成为性能瓶颈,特别是在高并发场景下。
- 需要处理死锁和锁超时等异常情况。
- 需要确保锁的公平性和一致性。
解决方案:
- 优化数据库性能,例如通过索引、分区等手段。
- 设置合理的锁超时时间,避免长时间占用资源。
- 使用更高级的分布式锁服务,如Redis的RedLock算法等。
四、实际应用案例
在一个电商系统中,多个后台服务可能需要同时更新商品库存。为了避免库存超卖,可以使用分布式锁来确保同一时间只有一个服务能够修改库存。通过数据库实现的分布式锁可以确保在库存更新操作期间的数据一致性。
五、总结
基于数据库的分布式锁是实现分布式系统中资源共享控制的一种有效手段。在.NET项目中,通过System.Data.SqlClient等数据库连接库可以方便地实现这种锁机制。然而,它也有一些性能上的挑战和潜在问题需要注意和解决。在实际应用中,应根据项目的具体需求和场景选择合适的分布式锁实现方式。