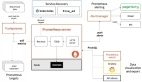
常见的监控方法
Prometheus和Grafana是两个流行的开源监控工具,它们经常一起使用来实现系统和应用程序的监控、可视化和告警。
Prometheus
Prometheus 是一个开源的系统监控和警报工具包。它最初由SoundCloud开发,用于监控其容器化架构中的服务。Prometheus提供了多维数据模型和强大的查询语言,可以轻松收集和存储时间序列数据,并支持灵活的数据查询和分析。其主要特点包括
多维数据模型
Prometheus使用标签(labels)来标识时间序列数据,允许用户根据多个维度进行查询和聚合。
灵活的查询语言
PromQL是Prometheus的查询语言,支持丰富的操作符和函数,可以实现复杂的数据查询和分析。
时序数据存储
Prometheus使用本地存储引擎存储时间序列数据,支持快速高效的数据查询和检索。
自动发现和服务发现
Prometheus支持自动发现和服务发现功能,可以动态地监控和管理多个目标实例。
警报和通知
Prometheus可以设置警报规则,并通过电子邮件、Slack等方式发送警报通知。
Grafana
Grafana 是一个开源的数据可视化和分析平台,最初由Torkel Ödegaard开发。它提供了丰富的数据可视化功能,支持多种数据源,并且具有灵活的仪表板配置和高度可定制化的图表。Grafana的主要特点包括
多数据源支持
Grafana支持多种数据源,包括Prometheus、InfluxDB、Elasticsearch、MySQL等,可以轻松整合不同数据源的监控数据。
丰富的可视化选项
Grafana提供了多种图表类型和可视化选项,包括折线图、柱状图、仪表盘等,用户可以根据需求自定义图表展示方式。
灵活的仪表板配置
Grafana允许用户自定义仪表板布局和组件配置,可以根据实际需求设计和定制监控仪表板。
告警和通知
Grafana可以集成多种告警通知方式,如电子邮件、Slack、Webhook等,帮助用户及时发现和处理异常情况。
Prometheus与Grafana的配合使用
Prometheus和Grafana通常一起使用,形成强大的监控和可视化解决方案。Prometheus负责数据的收集、存储和查询,而Grafana则负责将收集到的数据进行可视化展示和分析。通过这种配合使用,用户可以实现对系统和应用程序的全面监控和实时分析,帮助快速发现和解决潜在问题,提高系统的稳定性和可靠性。
使用Prometheus
要将监控指标提供给Prometheus,我们需要实现以下接口或遵循以下约定
Prometheus HTTP Server接口
我们需要在我们的应用程序中实现一个HTTP Server,用于提供监控指标的HTTP接口。这个接口通常位于/metrics路径下,Prometheus将定期向该接口发送HTTP请求来获取监控指标数据。
Exposition格式
我们的HTTP接口需要按照Prometheus的Exposition格式输出监控指标数据。Exposition格式是一种简单的文本格式,包含了监控指标的名称、标签和值。我们可以输出以下几种类型的监控指标
Counter(计数器)
用于累计某个事件发生的次数,例如请求数、错误数等。
Gauge(仪表盘)
表示当前的某个值,可以随时增减,例如内存使用量、并发连接数等。
Histogram(直方图)
用于表示数据的分布情况,例如请求响应时间的分布。
Summary(摘要)
类似于直方图,但是摘要会对数据进行汇总和统计,例如请求响应时间的摘要统计信息。
Prometheus指标命名规范
我们的监控指标名称需要遵循Prometheus的命名规范,通常使用小写字母和下划线,并且具有语义明确的名称。例如http_requests_total、memory_usage_bytes等。
标签(Labels)
为了更好地区分和过滤监控指标,我们可以为每个监控指标添加标签(Labels)。标签通常用于表示监控指标的附加信息,例如主机名、应用程序名称等。标签的格式为key=value。
定时更新
我们的HTTP接口应该能够定时更新监控指标的值,并且保证在Prometheus发送请求时返回最新的数据。通常,Prometheus会定期拉取监控指标数据,因此我们需要确保我们的接口能够及时提供最新的监控指标值。
通过实现以上接口和遵循约定,我们就可以将我们的监控指标暴露给Prometheus,并让Prometheus能够定期获取和存储这些指标数据,从而实现对我们的应用程序的全面监控。
Prometheus提供了哪些exporter
https://prometheus.io/docs/instrumenting/exporters/
官方提供了特别多的exporter,几乎涵盖了所以的,我们不需要自己写即可实现。

大数据基座各集群监控方法
日志采集
监控方法
Filebeat/Metricbeat/Winlogbeat监控
- 使用Elasticsearch和Kibana搭建监控平台,通过Beats提供的监控数据模块实时监控Filebeat、Metricbeat和Winlogbeat的运行状态、采集情况和性能指标。
- 设置警报规则,及时发现和处理异常情况,如采集失败、数据延迟等。
- 定期分析和统计采集数据,优化配置,提升采集效率和性能。
Kafka集群
监控方法
Kafka指标监控
- 使用Kafka自带的JMX监控功能,收集Kafka集群的各项指标,如吞吐量、延迟、存储使用情况等。
- 使用Kafka Manager或其他第三方监控工具,实时查看Kafka集群的健康状态和性能指标,并进行报警和故障处理。
归一化集群
分布式实现方案
Fluent Bit二次开发
- 在Fluent Bit基础上进行二次开发,实现分布式部署和数据处理能力。
- 使用Fluent Bit提供的插件机制,开发自定义插件实现数据归一化处理。
监控方法
集群状态监控
- 使用Prometheus和Grafana搭建监控平台,监控Fluent Bit集群的运行状态、资源利用率和负载情况。
- 收集Fluent Bit的日志和指标数据,实时查看归一化任务的运行情况和性能指标。
富化集群
分布式实现方案
自研Go语言规则引擎
- 基于Go语言开发规则引擎,实现分布式部署和规则匹配能力。
- 使用消息队列或分布式中间件进行任务调度和结果传递,实现富化任务的并行处理。
监控方法
集群状态监控
- 使用Prometheus和Grafana等监控工具监控富化集群的运行状态、资源利用率和任务执行情况。
- 收集富化任务的日志和指标数据,实时查看任务的运行情况、执行时长和处理数据量。
Hadoop集群
监控方法
Hadoop集群监控
- 使用Ambari、Cloudera Manager或其他Hadoop管理工具监控Hadoop集群的整体健康状况、节点状态和资源利用率。
- 使用Ganglia或自定义脚本收集Hadoop集群的指标数据,如HDFS存储使用量、MapReduce作业运行情况等。
Hive/Spark任务监控
- 使用Spark History Server或Spark监控模块监控Spark应用程序的运行情况和性能指标,如作业完成时间、任务执行时长等。
- 使用Hive Web UI或自定义脚本监控Hive查询的执行情况、查询延迟和资源消耗情况。
Oozie调度
监控方法
Oozie作业监控
- 使用Oozie Web控制台监控工作流和作业的运行状态、执行历史和日志信息。
- 使用Oozie命令行工具或API查询作业的状态,实时查看调度情况并进行调度管理。
Flink任务集群
监控方法
Flink集群监控
- 使用Flink自带的Web UI监控Flink任务集群的运行状态、作业图和任务指标。
- 配置Flink的Metrics系统,将指标数据发送至监控系统(如Prometheus),实时查看任务的吞吐量、延迟和状态。
以上监控方法可以帮助我们实现对大数据基座各集群的实时监控和性能分析,确保系统的稳定性和可靠性。
最终方案
我们可以采取在构建模块的时候集成Prometheus的exporter,这样可以为进一步做好集群监控搭好基础。