随着G行应用上全栈云越来越多,云上应用的需求也越发变得多样,对网络、安全、可观测性等各类需求也逐渐从传统面向"点、线"的场景转向了"面、分布式"的场景,对云上很多领域而言,eBPF这种新技术能提供简单、便捷、快速的手段来实现各类工具、服务。本文对eBPF的概念、主要使用场景、使用方式进行了简单介绍,并结合全栈云实际运维场景对eBPF技术进行了实践,抛砖引玉。
一、eBPF基本概念
传统BPF工作方式: 基于事件驱动的框架,用户使用BPF虚拟机指令集(RISC精简指令集)定义过滤规则,然后传递给kernel再进行JIT即时编译成CPU原生指令,在事件被触发时执行。通过这种在kernel层实行过滤的方式,降低用户层定义的过滤成本,提升包过滤性能。传统的tcpdump就是这种过滤方式。
eBPF是在研究软件定义网络方案时扩展出来的技术,使BPF扩展成为了一个更通用的虚拟机,仍然是基于事件驱动的框架。eBPF patch在2014年3月开始合入kernel主分支中,JIT组件在2014年发布的Linux 3.15版本中被合入,应用层控制BPF程序的bpf系统调用在Linux 3.18中被合入,接下来的Linux 4.x版本系列中添加了eBPF支持kprobes,uprobes,tracepoints和perf_events等事件类型。
eBPF相比传统BPF技术,寄存器从32位扩展到64位,寄存器数量也扩展到10个以上,扩展了map技术实现内核态与用户态共享存储空间用于高效读取数据,并从包过滤事件类型扩展到动态插桩内核函数、静态插桩内核函数、用户函数插桩、性能监控、安全等领域。当前BPF名称默认即指eBPF。
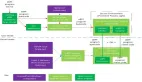
二、eBPF内部工作机制示意图
 图1 eBPF工作示意图
图1 eBPF工作示意图
主要过程:
- 用户编写eBPF代码,并使用LLVM、GCC等把代码编译成eBPF字节码;
- 用户态程序或工具通过bpf系统调用加载eBPF字节码到kernel中;
- 内核验证器验证字节码是否合规、安全,确保不会造成kernel异常,验证通过后,内核中的JIT即时编译器把字节码翻译成CPU原生指令并加载到对应的事件接口;
当内核中对应事件被触发时,执行被加载的CPU原生指令,分析数据放入map共享区供用户态程序使用。
三、eBPF重要应用场景
1. eBPF定义网络
在与Linux Kernel解耦的同时,通过eBPF可编程性及高效处理可以在Linux内核包处理上下文中动态添加处理逻辑,包括过滤、流量控制、转发、执行路径优化、协议解析等几乎任意操作,同时以近似于本地编译的内核代码效率执行。比如Linux内核XDP(快速数据路径)框架,通过在框架中挂载eBPF程序后,可实现三层路由转发、四层负载均衡、分布式防火墙、访问控制ACL等功能定制,可以编写eBPF程序挂载到网卡驱动层直接处理网络流量,绕过Linux Kernel,进而可以使用专用的网络处理器(NPU)进行网络流量处理,释放CPU资源。开源社区比较典型的有facebook开源的Katran四层负载均衡器等。腾讯使用Cilium作为TKE底层引擎,阿里云使用eBPF技术实现CNI网卡。G行全栈云使用的DeepFlow流量采集和分析技术也使用了eBPF技术。
2. eBPF定义安全
除了早期基于bpf技术实现的内核运行时安全计算模型Seccomp和LSM Linux安全模块之外,业界有很多基于eBPF技术来高效灵活实现网络安全策略,比如Flacon异常行为检测工具;容器网络领域的开源项目Cilium,重度使用eBPF技术来实现云原生场景下的三层/四层/七层网络安全策略等,在不更改应用程序代码或容器配置的情况下能够发布和更新 Cilium 安全策略;用于Linux的运行时安全和取证工具Tracee,使用Linux eBPF 技术在运行时跟踪系统和应用程序,收集事件并分析检测可疑行为模式。
3. eBPF可观测性和实时跟踪
Netflix公司基于eBPF实现生产环境tracing, AWS公司使用eBPF作为RPC观测工具,国内互联网巨头字节跳动使用eBPF技术实现主机可观测性和ACL访问控制等。
网络包全链路排查开源工具pwru(package where r u)是基于 eBPF 开发的网络数据包排查工具,提供了完整的细粒度网络数据包排查方案 (kernel版本需大于5.5)。
四、 eBPF主要使用方式
1. 使用C语言、Go语言等编程语言编写原始eBPF程序,实现逻辑控制、观测跟踪等功能,具体可参考社区教程。
2. 使用高阶封装工具 BCC编写eBPF观测跟踪程序。为了降低BPF程序开发门槛,社区发起了BCC项目,提供简单易用的编写、加载和运行eBPF程序的一个框架,并可以通过Python、Lua等脚本语言来编写。除此之外还提供了很多现成的用于对内核、CPU、内存、调度、网段等子系统的观测跟踪,参考https://github.com/iovisor/bcc。
3. 使用高阶封装工具bpftrace编写eBPF观测跟踪程序。通过命令行就能实现eBPF性能观测工具,更加简化eBPF使用,用于追踪、调试Linux kernel、了解kernel运行机制非常有用,缺点是不能调用内核函数或者自定义函数(此类场景需要使用BCC或C、GO语言开发),可参考https://github.com/iovisor/bpftrace
五、 G行全栈云Caas环境下eBPF技术初体验案例一:全栈云hyper主机ping延时高
在全栈云某些hyper物理机上,发现ping 127.0.0.1延时高(图2)
 图2 ping延时高
图2 ping延时高
通过perf性能分析工具分别对正常ping、有ping延时进程分别进行trace采样,制作成火焰图,分析出耗时部分。
正常ping(图3):
 图3 正常ping火焰图
图3 正常ping火焰图
异常ping(延时大,图4):
 图4 异常ping火焰图
图4 异常ping火焰图
在火焰图里可以看到,相比正常ping,延时高ping过程在try_to_wakeup_up()调用过程中耗费较大。
为了进一步搞清ping延时过程中try_to_wakeup_up具体是什么情况,编写bpftrace kprobe类型程序挂载到try_to_wakeup_up内核函数:
#include <linux/sched.h>
kprobe:try_to_wake_up
/ pid == $1 /
{
$task = ((struct task_struct *) arg0);
$pid = $task->pid;
printf("from %s -> wakeup comm %s pid %d\n", comm, $task->comm, $pid);
}用bpftrace执行此eBPF程序,监控ping进程被try_to_wakeup_up的详细过程(图5):
 图5 eBPF tracing数据
图5 eBPF tracing数据
从图中我们可以看到,在ping的过程中,try_to_wakeup_up频繁唤醒isc-socket进程,经分析,此为dhcpd相关进程,是IaaS层分布式虚拟路由dvr master与client之间的处理逻辑。把dhcpd相关进程迁移到别的机器后,本机器上的ping 127.0.0.1延时恢复正常。
从以上案例可以看出,eBPF具备强大的可观测性和实时跟踪能力,可以很容易根据场景定制出合适的trace能力,对于观测定位kernel、进程的运行逻辑十分便利。
案例二:观测收发包主要过程耗时
在全栈云CaaS环境下,各业务以pod的形式运行在自己的namespace中,如果不同pod之间通信偶尔抖动变慢,如何判断是网卡、协议栈、应用层等哪个环节出现了问题?传统的tcpdump抓包工具(底层基于了classic bpf库)抓包位置在软中断从网卡队列(ring buffer)中读取数据后发送给协议栈的时候,只能从tcpdump看到sequence数据包在网卡接口处收发的时间,在正常情况下无法直观看到更深层次的延时原因,比如是内核处理延时还是用户态延时?
如果我们知道veth驱动收发包关键kernel函数,以及协议栈处理与veth驱动的衔接点,就可以编写eBPF程序挂载到这些关键函数入口或出口处,在可通过kprobe或者tracepoint在协议栈各层的关键函数中添加hook点,当数据包经过该函数时,打印出seq、network namespace、时间戳等关键信息,帮助我们快速定位或者缩小问题范围。
本文模拟node节点某块虚拟网卡延时(图6),此时node节点上与pod节点(与延时虚拟网卡配对)如何判断是网卡慢还是协议栈处理慢?
 图6 测试环境
图6 测试环境
首先需要分析出此场景下eBPF程序合适的kernel挂载点,基于bpftrace工具编写eBPF程序并进行观测跟踪体验:
1. veth发送关键内核函数:
__dev_queue_xmit(将数据发送到驱动层)
在该挂载点,获取tcp四元组信息,获取tcp sequence,并使用全局变量保存接收时间(纳秒)@rcvpkg[$seq] = nsecs;
2. veth接收关键内核函数:
__netif_receive_skb(将报文收到协议栈)
tcp_rcv_state_process(tcp状态机处理函数)
tcp_rcv_established(tcp establish过程处理)
选取上面3个示例挂载点,获取tcp四元组信息,获取tcp sequence与当前时间,减去__dev_queue_xmit记录的起始时间,就可以得到发送到接收、协议栈主要处理函数耗时,对于超过一定时间的可以进行告警打印。
if( ($seq) == @sequence ){
$delta = ((nsecs - @rcvpkg[$seq]) / 1000000) % 1000;
if( $delta >= $1 ){
time("\n%H:%M:%S ");
printf("%-19u %-5s %d,%s,%s,%-10d ", $nsid, $netif, pid, comm, func, cpu);
printf("flags:%s, seq:%-u, ack:%u, win:%-25u ", $pkgflag, $seq, $ack, $win);
printf("%s:%-15d %s:%-15d %d ms\n", $srcip, $sport, $dstip, $dport, (nsecs / 1000000) % 1000);
printf("Slow pkg: duratinotallow=%u ms, seq=%-u\n", $delta, $seq);
}
}模拟网络延时:
tc qdisc add dev vnice9657d91c32 root netem delay 10ms
tc qdisc add dev vnicb8898168feb root netem delay 20ms
在node节点上执行eBPF程序:
bpftrace netpod.bt 5 > tt
在node节点上执行测试命令:
curl 30.254.10.7:8099;
nsenter -n -t 20720 telnet 30.254.10.6 22627
eBPF捕获数据如下,可以看出tc设置的延时是在xmit发送时候产生的,接收方及tcp协议栈处理耗时正常(图7-1,图7-2)。
 图7-1 eBPF tracing网络延时数据
图7-1 eBPF tracing网络延时数据
 图7-2 eBPF tracing网络延时数据
图7-2 eBPF tracing网络延时数据
六、eBPF演进趋势展望
eBPF技术像是一个任意门,可以随意穿梭到你想去的地方进行探索甚至改造,在云时代大显身手。Linux kernel面临不断增长的复杂度、性能、可扩展、向后兼容性等需求,需要保持kernel渐进式发展,更多新功能、新特性无法及时合并到kernel中。eBPF的内核可编程性,既能保证安全,又能在不改变kernel代码的情况下实现新功能、新特性的快速应用,可为kernel的发展提供tick-tock迭代新方案,可以想象未来kernel的发展极有可能在eBPF技术基础上实现软件定义kernel。对于全栈云平台而言,可以跟进eBPF技术发展,研究eBPF适用的应用场景,更好支持云上应用。