中关村论坛举办以来的首个主题日活动:「人工智能主题日」今日开启!
到场嘉宾,也是星光熠熠,大佬云集,还有着浓浓的国际范儿,与世界顶尖水平接轨。
一共161位嘉宾,近一半是外籍AI大佬和从业者。
而嘉宾阵容也是非常豪华,汇集了国内外30多名院士,还有诺奖、图灵奖得主,清北港科大等知名高校的校长副校长。
百度、蚂蚁、微软、亚马逊等世界领军科技企业,也都前来参会。
可以说,「人工智能主题日」堪称如今AI界的顶级盛会,亮点满满,精彩纷呈。
重磅技术成果发布
国产Sora,又上新了!
在今天的中关村论坛「人工智能主题日」上,生数科技联合清华大学,共同发布了最新的视频大模型「Vidu」。
Vidu生成的画面一亮相,就让全场惊呼——这个效果也太像Sora了!

在人物和场景时间一致性的保持上,Vidu的表现令人印象深刻。

而且,它生成的视频最长可达16秒左右,在时长上破了纪录。
甫一亮相,Vidu就得到了业内公认——
综合考虑时长、一致性、真实度、美观性等因素,它是「国产Sora」模型中当之无愧的佼佼者,是国内最能和Sora全面对标的视频模型。
清华大学人工智能研究院副院长、生数科技首席科学家朱军为我们放出了Vidu的以下演示。
一只小狗在游泳池里游泳,毛发纤毫毕现,狗脚划水的动作十分自然,和水的相互作用十分符合物理学原理。

人物眼睛的特写、做陶罐的女人手中正在转动的陶罐、一对坐着的男女同时抬头的动作,都刻画地细致入微,逼真到仿佛现实。

总的来说,Vidu具有以下几大特点——
模拟真实物理世界
森林里的湖边风光,无论是树、水面、云朵,还是整体的光影效果,很逼真写实。

汽车行驶在崎岖山路上的场景,也是非常经典的Sora演示。
Vidu模拟了非常真实的光影效果,连扬起的灰尘,都十分符合物理规律。

富有想象力
在这艘AI视频模型必考题中,Vidu生成的视频效果实在太惊艳!
画室里的一艘船驶向镜头的场景。

这道题,考验了模型虚构场景的能力,为了生成超现实主义的画面,它们需要具有超强的想象力。
理解多镜头语言
可以看出,Vidu能够理解多镜头的语言,不再是简单的镜头推拉。这样,就能模拟我们的摄影过程。
生成的这个视频中,要求它包含海边小屋、镜头过渡到阳台、俯瞰大海、帆船、云朵等元素。
Vidu生成的视频,具有复杂的动态镜头,远、近、中景、特写,以及长镜头、追焦等效果,都十分惊艳。

一镜到底,16s时长
而在这个视频中,Vidu展现出了16s的超长「一镜到底」。
而且,视频完全是由单一大模型生成的,不需要任何插帧、剪切,直接就实现了端到端的生成。

超强时空一致性
要求它以《戴珍珠耳环的少女》为灵感,生成一只蓝眼睛的橙色猫,可以看出,Vidu生成了连贯的视频。
从旋转的各个视角看,都非常逼真,甚至让人产生了「这是一个3D模型」的错觉。

它生成的视频中,人物和场景在时空中始终保持一致。
理解中国元素
相比国外的AI视频模型,Vidu也更理解中国元素。
熊猫、龙这样的中国元素,它都能理解和生成。

和Pika、Gen-2比起来,Vidu的表现也丝毫不弱。
一艘木头玩具船在地毯上航行。
两位对手的视频一个只有4s,一个更是画面简单的循环播放,而Vidu的视频以16s的自然画面秒杀了它们,在一致性的保持和语义理解上,也都非常突出。
用和Sora同样的prompt,Vidu的表现甚至更好。
Sora并未理解旋转的镜头是什么意思,而Vidu不仅表现出了旋转,还保持了一致性的效果。

几分钟的视频结束,全场响起经久不息的掌声。
之所以能在短时间做出如此惊艳的视频AI模型,离不开团队的长期积累和多项原创成果。
团队的技术路线,竟也和Sora的高度一致。
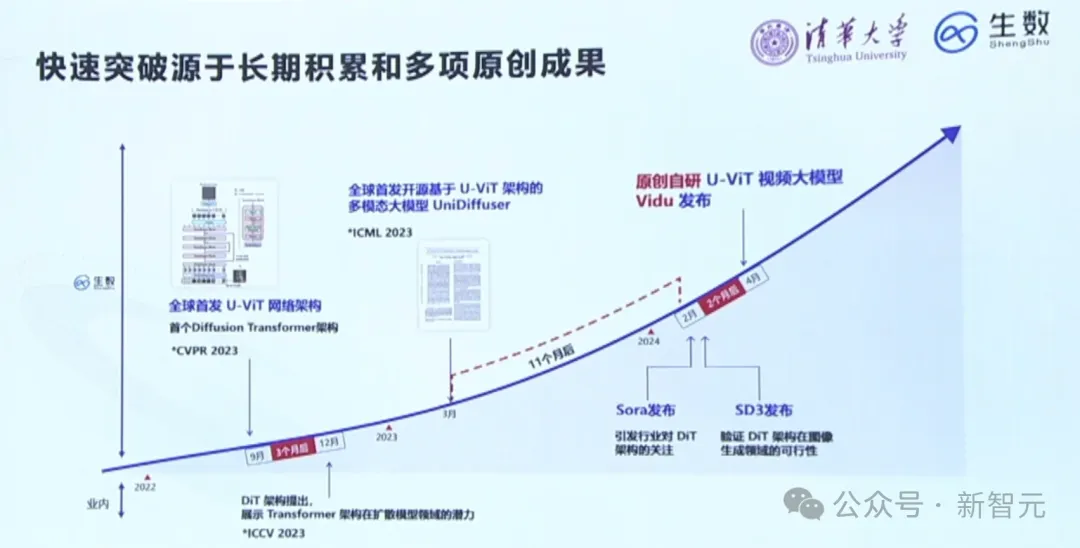
全球首个低碳、高性能多语言LLM
此外,全球首个低碳、高性能、低幻觉多语言大模型Tele-FLM,由北京智源人工智能研究院与中国电信人工智能研究院(TeleAI)在今天正式联合发布——所有核心技术、权重、训练过程中的各种细节全面开源。
520亿参数的Tele-FLM在2T token的数据上,用时2个月完成训练。

值得一提的是,据Meta3官网信息,Llama 3-70B模型的训练,可能使用了近5万块H100。而Tele-FLM仅用了896×A800的算力,完成了训练。
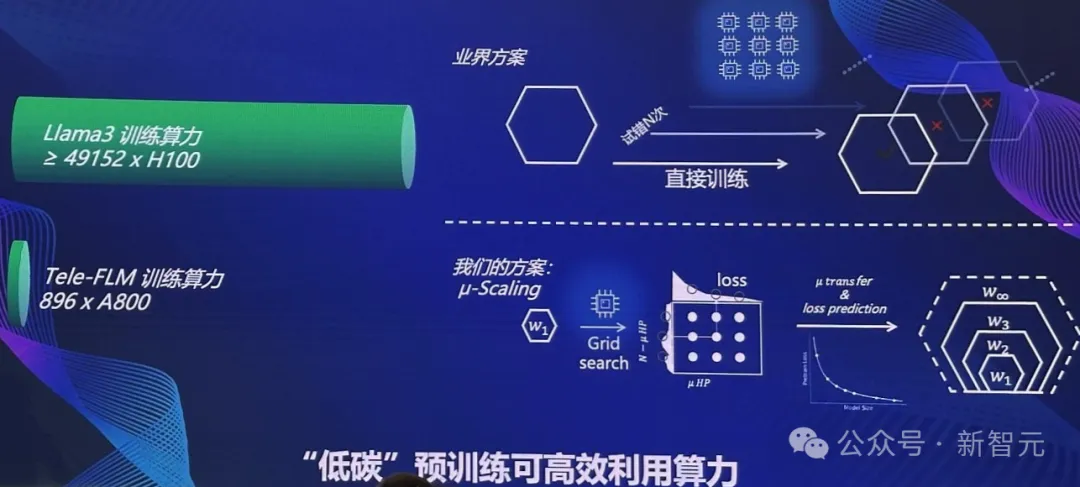
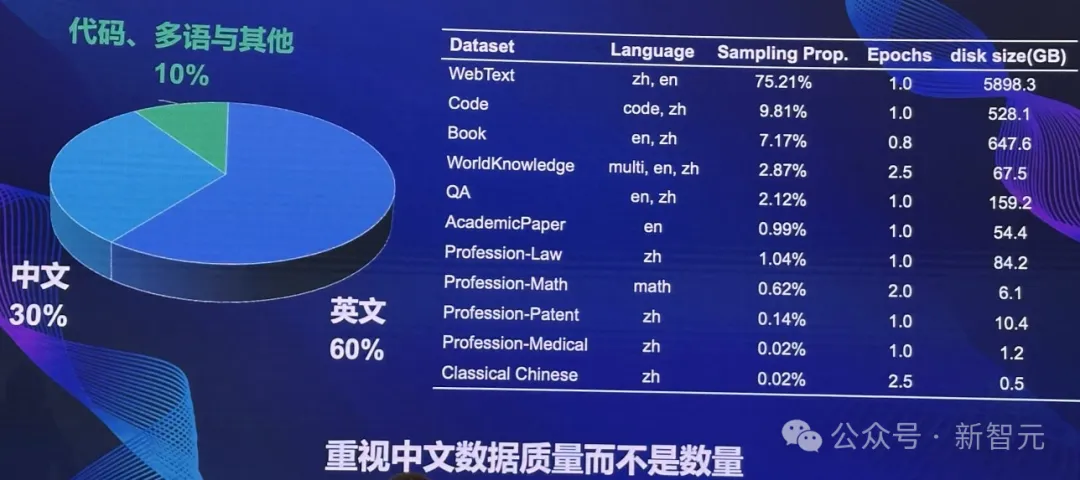
此外,模型训练过程还对数据质量进行严格把控。
通过使用高质量的中文数据,虽然只占30%,但Tele-FLM的中文能力明显超越了对标的模型,取得了领先的成果。
未来,还将推出千亿、六千亿、甚至万亿参数版本,而且都将全部开源,供所有人使用。

顺便提一句,会上最精彩的部分,莫过于机器人上台表演了。
看看来自宇树科技的这只机器狗,倒立行走,简直太飒了。

除了颇有前沿范儿的技术成果发布,人工智能主题日上,国内大佬的演讲也是干货满满。
大佬演讲精彩亮点
北大教授、中科院院士鄂维南的演讲,让我们重新审视,大模型+大数据库相结合的价值所在。
如今,我们能够畅想人工智能的未来,那都是因为有一个最基本的工具——深度学习。
其实,深度学习很早就诞生了。
但真正将其带向世界,释放出重大威力的标志性事件便是——2012年,Hinton和两位学生训练的大型深度神经网络一举赢得ImageNet大赛。

每个人都知道,若想开展机器学习研究,需要有三个最基本的工具:
一是模型工具,借助诸如Pytorch、TensorFlow、MindSpore等工具,AI开发者才能写出深度神经网络。
二是算力工具,当然非GPU莫属,再结合CUDA这样的架构,实现高效的算力利用率。
三是数据工具。

现在,全世界包括OpenAI、谷歌等在内的公司,都希望获取高质量的数据。同时,数据稀缺已然成为LLM训练的一大难题。
也正是在数据这个领域,现在的发展还不是很成熟,缺少可以利用的工具。
对于数据的处理,大家还是主要凭经验,没有一个完整的系统,去解决这一问题。
其中,「非结构化数据」处理,是机器学习方法的主要困难之一。
如果我们可以将文本、视频之类的数据,能够将其放在一个表格当中,那将会大大降低ML门槛。
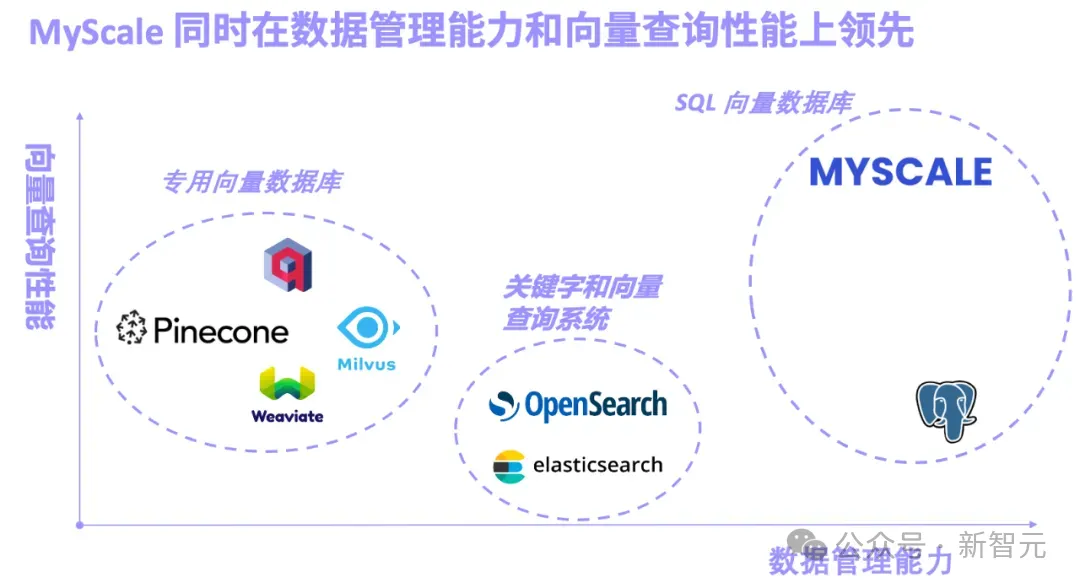
就在这个月初,国际上第一个AI「非结构化数据库」MyScale正式宣布开源。
通过自研高性能和高数据密度的向量索引算法,成为目前综合性能最好,功能最强的AI数据库。
LLM+大数据双轮驱动
那么,现在有了如上这些能力,接下来可以做什么?
或者说,下一个技术路线是什么?

当我们将所有数据放在「数据库」中,基于此,就可以构建各种各样的小模型,由此产生了「模型库」。
最后,就可以通过操作系统对模型进行调度。
这样的优势在于,不仅可以将所有结构化数据,以及非结构化数据,放在同一个数据库中,还能通过常见的SQL语言实现搜索查询。
此外,还可以很高效地训练出小样本的数据模型。与训大模型不同,训练小模型,如何选取数据是非常困难的。
比如针对自动驾驶场景,无用样本只会影响模型的效率和精度问题。
有了AI数据库,就可以快速获取相应的样本数据,比如红灯、左转弯等。
由此一来,训练后的自动驾驶模型,准确率可以提升50%-90%。

除此以外,模型管理平台,可以提供对模型全周期的管理。

一个很典型的场景是——政府智慧城市管理,以前遇到的是数据孤岛的难题,到现在的模型孤岛。
每个企业基于不同的模型做一个应用,由此带来的问题是,正度很难实现全面、方便快捷的管理。
而云平台的出现,可以让企业基于此做低门槛的开发,根据需求即可调用成千上万的模型。

而现在,大模型诞生可以大大提升基础AI能力,还有可以实现具体任务的Agent。
接下来,就可以在原来框架下稍作改动:
- 小模型改成Agent
- 模型生产平台以预训练模型作为基座

另一方面,模型操作系统可以将模型和任务完成对接。
比如,把政府的需求梳理后,针对每个需求去做一个模型,结果就会产生很多模型。甚至一个需求,需要做不同的模型。
然而,针对复杂场景,模型操作系统却很难将模型和任务完成对接。
鄂维南院士表示,「这恰恰是未来大模型能够提供的真正的核心能力——一个能完全将模型和任务匹配的操作系统」。
另外,大模型还可以和大数据库进行结合。

比如,鄂维南院士预告的团队成果——Science Navigator平台。
它是将所有理工科的文献塞到一个数据库里,由此训出的文献大模型,具备了查询文献、提供论文写作灵感等能力。
未来,还可设想将国家图书馆所有资料塞进数据库中,让模型释放出更大的潜力。
总而言之,想要训出优质大模型,构建一个高效的数据处理的系统,是关键所在。

光电智能计算登上Nature
接下来,是中国工程院院士、中国人工智能学会理事长戴琼海对于光电智能计算方面的介绍。
要说大模型再发展下去,面临的最大危机是什么?
大家都知道,答案无疑就是算力和电力的巨大缺口了。
如今,GPT系列的研究,已经累计投入了超过30亿美元。

AI模型的耗电,实在是太猛了!
ChatGPT每天的能耗高达70万美元,而在十年内,大模型计算将消耗我国每年发电量的5%到10%!

黄仁勋、Sam Altman、马斯克等大佬,也都纷纷预言:下一波AI消耗的电力将远远超过预期,能源系统难以应对。超级AI,将成电力需求的无底洞!

如今的主流通用芯片就是GPU,此外还有延长线,即专用芯片,这些都是基于电子电路的发展。

而第三条路,就是新型的计算架构,比如量子计算、存算一体、光电计算。
能否从电子电路,改变成光的载体?1966年,「光纤之父」高锟打开了光通信的大门。

不过有一个问题是:功耗下来了,算力却一直提不上去。
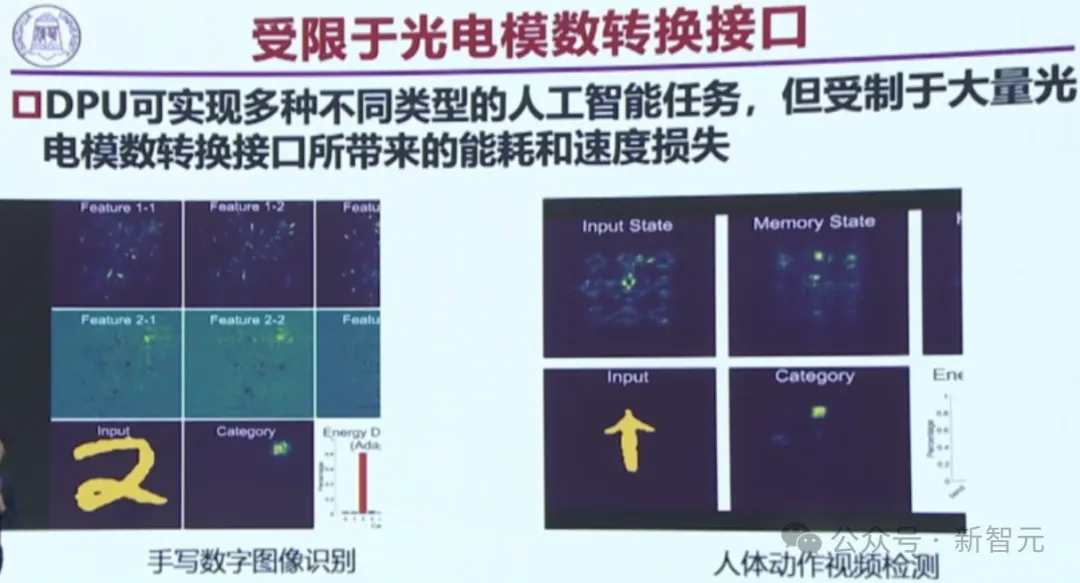
为此,我国在国际上第一个提出了一个,大规模可重构衍射计算处理器(DPU)。

在架构突破上,我国团队首次提出了光-电-光融合可重构计算方法;在非线性突破上,首次提出了光电探测非线性激活函数。

光电之间的ADDA转换,要花费巨大的功耗,这就是一个最重要的瓶颈。
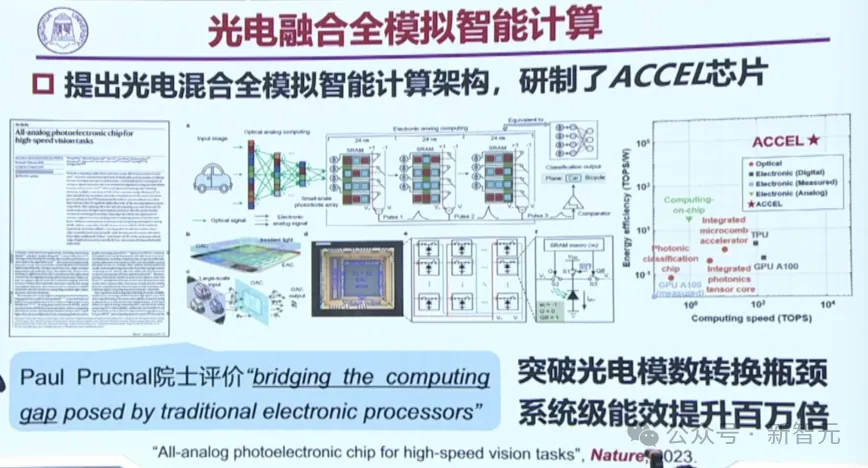
在此基础上,团队提出了光电混合全模拟的智能计算架构,研制了ACCEL芯片,突破了光电模数的转换瓶颈,直接让系统级能效提升了百万倍!
这项研究去年已在Nature上发表,同样属于中关村创新成果。
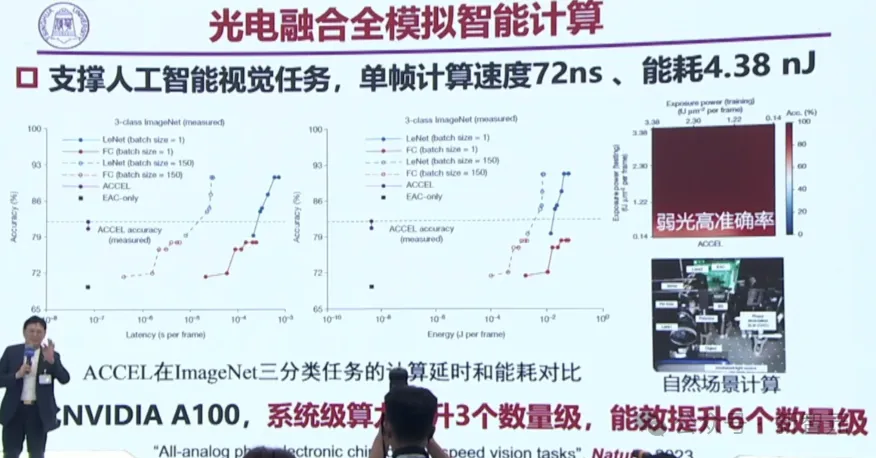
如今,ACCEL芯片已经在很多任务级开展了工作,让能耗大大下降。

相比英伟达A100,ACCEL芯片让系统级算力提升了3个数量级,能效提升了6个数量级。
在国际上的整个光芯片领域,都处在最前沿。
不过,真正的大模型训练和推理,还是存在一个关键的问题:深度网络做不了深,层数就非常有限。
于是,团队又提出了一个新的架构——大规模智能光计算芯片「太极」。
电子的深度网络架构可以做一百层、两百层,但光却做不了深,怎么办?
团队的办法是,化「深」为「广」,其中有干涉也有衍射,用干涉来做广,用衍射来做深,这就把以前的深度架构改成了拉伸的架构。
横纵结合,是为太极。
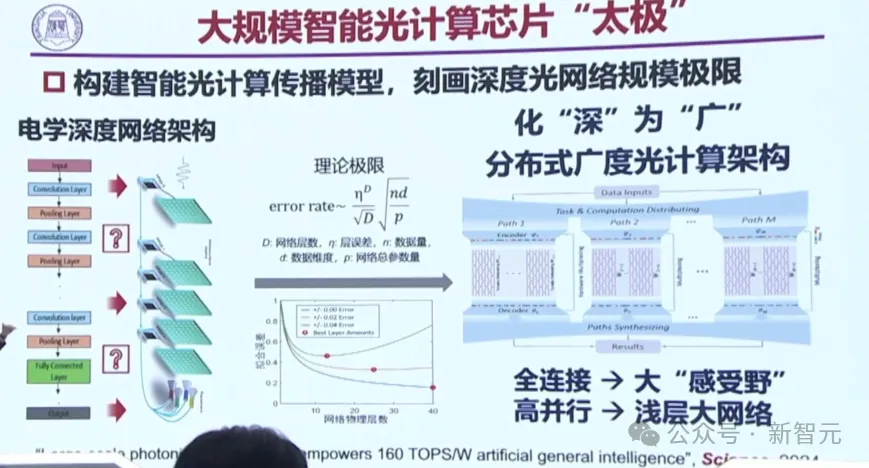
两种光性质结合在了一起,就建立了任务编码宏观拆分机制。具有「广度」的光神经网络,就能支撑复杂的智能任务。
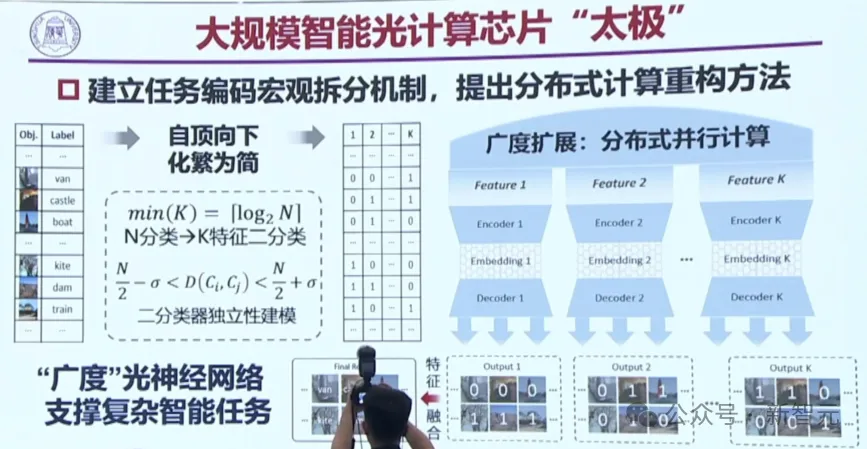
甚至能做100多层的深度网络。
而下图中的蓝色线条,即为衍射。干涉和衍射,就像乐高拼玩具一样,拼在一起,就可以做大模型的光计算应用。
大规模的太极光计算芯片,完全可以支持现在的图像分类、多种音乐风格的生成。

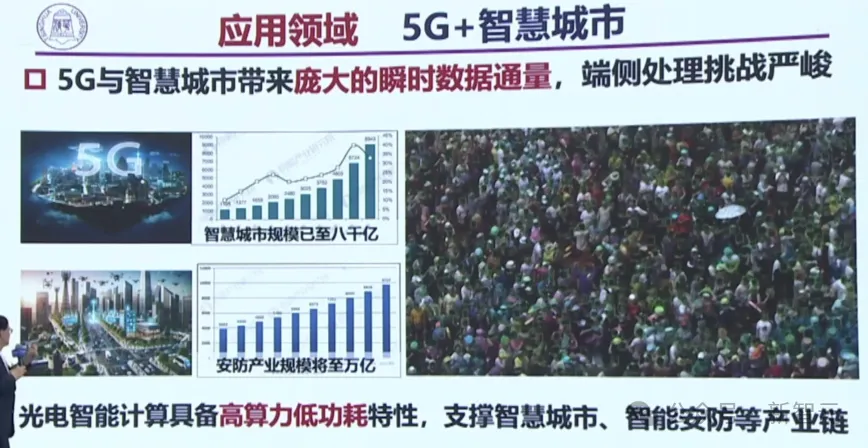
在未来5G和智慧城市结合,会带来庞大的瞬时数据通道,让端侧处理面临着严峻挑战。
比如下面这个超大的视频,如果由A100来跑,还需要8台到10台以上才可以。而光芯片只需要一台,就可以进行这方面的应用了。
因此,光电智能计算,可以支撑智慧城市、智能安防等产业链。
未来, 团队还计划构建一个光算力实验室,总之,太极芯片非常有望实现工业场景的应用。
海淀区优势聚集
以上重磅成果,恰好都诞生在海淀。为什么?
仔细分析可以知道,这种现象是一种必然。
人才+生态
在海淀,汇集了高密度的人才和生态土壤。
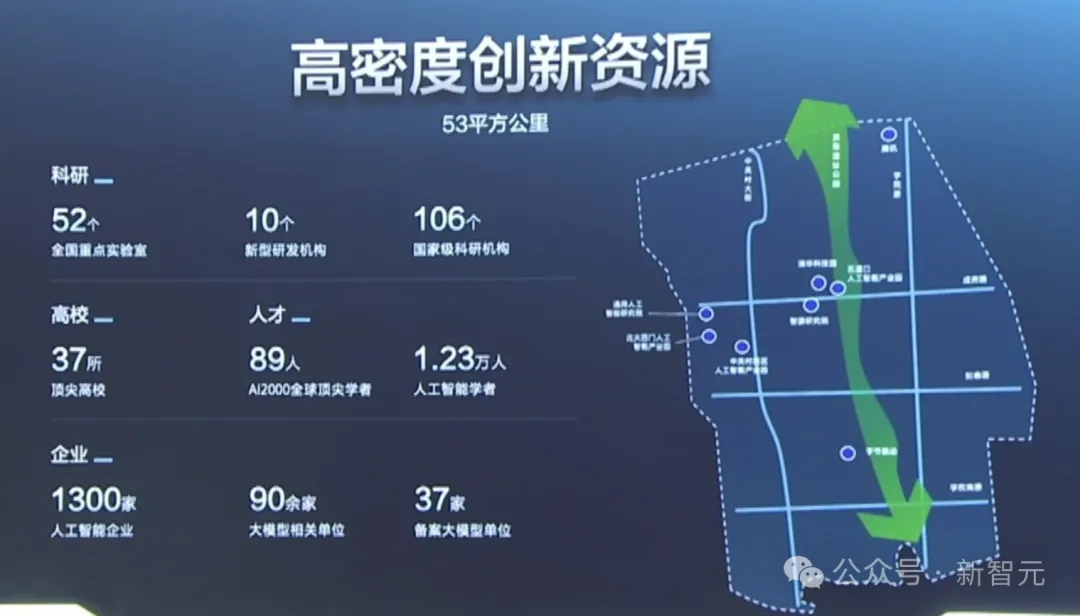
要说海淀区的AI人才浓度,说一声全国TOP 1应该不算过分。
在这里,汇聚起了1.23万人工智能学者,和89位AI2000全球顶尖学者。
全国AI人才看北京,北京AI人才看海淀。
已经「出厂」的人才,密密麻麻地分布在海淀的近千家企业。海淀的AI企业,直接占全北京的2/3,全国的1/5。
还在校的人才,也正紧锣密鼓地培养中。
全海淀的37所高校中,设立AI专业的高校,就高达21所。
人才、企业、算力基础设施布置,海淀是妥妥的一条龙布局。
说一声AI建设创新策源地和产业高地,海淀区是当之无愧。