本文经自动驾驶之心公众号授权转载,转载请联系出处。
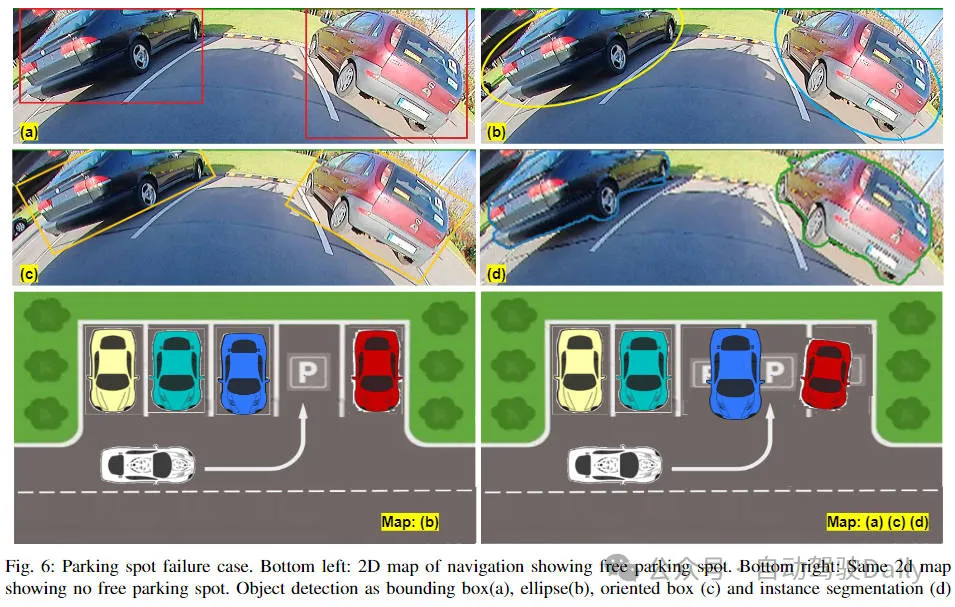
目标检测在自动驾驶系统当中是一个比较成熟的问题,其中行人检测是最早得以部署算法之一。在多数论文当中已经进行了非常全面的研究。然而,利用鱼眼相机进行环视的近距离的感知相对来说研究较少。由于径向畸变较大,标准的边界框表示在鱼眼相机当中很难实施。为了缓解上述提到的相关问题,我们探索了扩展边界框的标准对象检测输出表示。我们将旋转的边界框、椭圆、通用多边形设计为极坐标弧/角度表示,并定义一个实例分割mIOU度量来分析这些表示。所提出的具有多边形的模型FisheyeDetNet优于其他模型,同时在用于自动驾驶的Valeo鱼眼相机数据集上实现了49.5%的mAP指标。目前,这是第一个关于自动驾驶场景中基于鱼眼相机的目标检测算法研究。
文章链接:https://arxiv.org/pdf/2404.13443.pdf
网络结构
我们的网络结构建立在YOLOv3网络模型的基础上,并且对边界框,旋转边界框、椭圆以及多边形等进行多种表示。为了使网络能够移植到低功率汽车硬件上,我们使用ResNet18作为编码器。与标准Darknet53编码器相比,参数减少了近60%。提出了网络架构如下图所示。
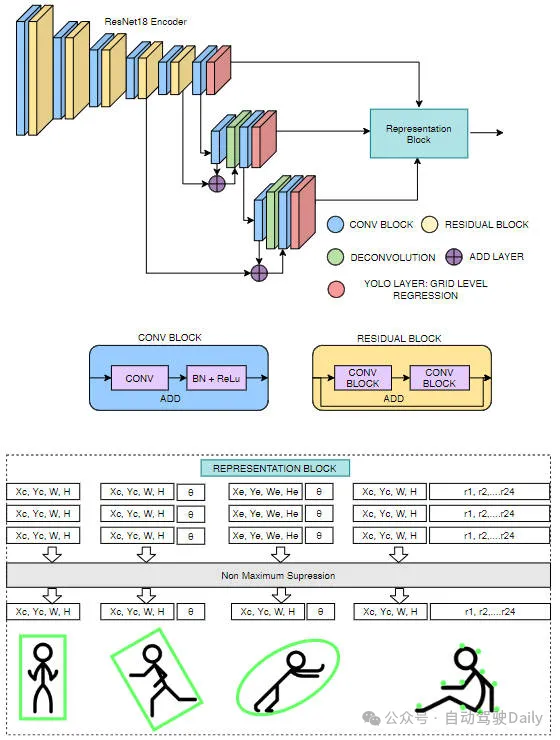
边界框检测
我们的边界框模型与 YOLOv3 相同,只是 Darknet53 编码器被替换为 ResNet18 编码器。与YOLOv3类似,目标检测是在多个尺度上执行的。对于每个尺度中的每个网格,预测对象宽度()、高度()、对象中心坐标(,)和对象类。最后,使用非最大抑制来过滤冗余检测。
旋转边界框检测
在该模型中,与常规框信息(,,,)一起回归框的方向。方向地面实况范围 (-180 到 +180°) 在 -1 到 +1 之间进行归一化。
椭圆检测
椭圆回归与定向框回归相同。唯一的区别是输出表示。因此损失函数也与定向框损失相同。
多边形检测
我们提出的基于多边形的实例分割方法与PolarMask和PolyYOLO方法非常相似。而不是使用稀疏多边形点和像PolyYOLO这样的单尺度预测。我们使用密集多边形注释和多尺度预测。
实验对比
我们在Valeo鱼眼数据集上评估,该数据集有 60K 图像,这些图像是从欧洲、北美和亚洲的 4 个环绕视图相机捕获的。
所有模型都使用 IoU 阈值为 50% 的平均精度度量 (mAP) 进行比较。结果如下表所示。每个算法都基于两个标准进行评估—相同表示和实例分割的性能。