主备、主从、和主主架构都基于一个共同的前提:主机需要有能力存储所有数据。然而,主机的存储和处理容量是有限的。以历史发展为例,Intel 386时代的服务器仅能存储几百MB数据,到了Intel奔腾时代则能够存储几十GB,而进入Intel酷睿多核时代后,服务器的存储能力增加到了数TB。尽管从硬件发展角度看,存储能力的提升速度相当快,但与业务需求的增长速度相比,这种提升还是远远不够。例如,截至2013年,Facebook已经累计存储了2500亿张照片,总容量达到250PB(250×1024TB),日均上传量达到3亿5000万张图片。这种庞大的数据量显然无法由单台服务器来存储和处理,因此必须依赖多台服务器的集群架构来实现。
简而言之,集群是由多台机器组成的一个统一系统,这里的“多台”通常指的是至少3台机器。与主备或主从架构的两台机器相比,集群提供了更大的扩展性。集群可以根据其中机器承担的角色不同分为两种类型:数据集中型集群和数据分散型集群。
数据集中集群
数据集中集群与主备、主从这类架构相似,我们也可以称数据集中集群为 1 主多备或者 1 主多从。无论是 1 主 1 从、1 主 1 备,还是 1 主多备、1 主多从,数据都只能往主机中写,而读操作可以参考主备、主从架构进行灵活多变。下图是读写全部到主机的一种架构:
 图片
图片
在主备和主从架构中,数据通常通过单一的复制通道从主机复制到备机。然而,在数据集中集群架构中,存在多个复制通道,这可能会增加主机的复制负担。在某些情形下,减轻主机的复制负担或减少复制操作对正常读写活动的影响是必要的。
此外,多个复制通道可能会导致不同备机之间的数据出现不一致。在这种情况下,需要对各备机之间的数据一致性进行验证和调整。
对于备机如何判断主机的状态,主备和主从架构中只涉及单台备机的状态判断。但在数据集中集群架构中,多台备机都需要对主机状态做出判断,且不同备机的判断结果可能不一致,处理这些不一致的判断是一个复杂的问题。
当主机发生故障时,如何决定新的主机也是一个关键问题。在主从架构中,通常直接将备机升级为主机。然而,在数据集中集群架构中,由于存在多台可升级的备机,必须决定哪一台备机最适合成为新的主机,以及备机之间如何进行协调。
ZooKeeper是一个典型的开源数据集中集群解决方案,它通过ZAB算法来解决这些问题,尽管ZAB算法相当复杂。
对于数据分散集群,这种结构涉及多台服务器,每台服务器存储部分数据并备份其他部分数据。数据分散集群面临的复杂性在于如何将数据恰当地分配到不同服务器上。这涉及到以下几个设计要素:
- 均衡性:分配算法必须确保数据在各服务器之间的分布大体均衡,避免某台服务器的数据量显著高于其他服务器。
- 容错性:当部分服务器出现故障时,算法需要能够将受影响的数据区重新分配给其他服务器。
- 可伸缩性:当需要扩展集群容量时,算法应能自动将数据迁移到新增的服务器上,并确保扩容后数据依然均衡分布。
与数据集中集群不同,数据分散集群中的每台服务器都能处理读写请求,因此不存在像数据集中集群中那样的专门负责写操作的主机角色。然而,在数据分散集群中,需要有一个特定角色负责执行数据分配算法,这个角色可能是一台独立服务器,也可能是由集群内部选举产生的服务器。如果是后者,这台服务器通常也被称为主机,但其职责与数据集中集群中的主机职责有所不同。
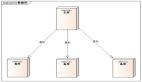
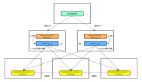
Hadoop 的实现就是独立的服务器负责数据分区的分配,这台服务器叫作Namenode。Hadoop 的数据分区管理架构如下:
 图片
图片
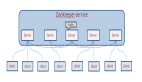
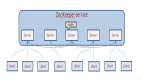
与 Hadoop 不同的是,Elasticsearch 集群通过选举一台服务器来做数据分区的分配,叫作 master node,其数据分区管理架构是:
 图片
图片
在集群架构中,数据集中型集群只允许客户端将数据写入主节点,而数据分散型集群允许客户端在任何服务器上进行读写操作。这一关键差异决定了两种架构适用于不同的应用场景。数据集中型集群通常适用于数据量较小、服务器数量较少的情况,如ZooKeeper集群,通常建议使用约5台服务器,且每台服务器的数据量是可管理的。相反,数据分散型集群因其优越的可扩展性,更适合处理大量业务数据和大规模服务器群,如Hadoop和HBase集群,这些集群可包含数百甚至数千台服务器。
数据分区
在考虑存储高可用架构时,我们通常关注的是如何在硬件故障发生时维持系统的运行。然而,对于可能导致所有硬件同时故障的重大灾害或事故,如新奥尔良的水灾、美加大范围停电、洛杉矶的大地震等,单纯基于硬件故障的高可用架构可能不足以应对。在这种情况下,需要设计可以抵抗地理级别故障的高可用架构,这正是数据分区架构的来源。
数据分区架构通过按照特定规则将数据分布在不同的地理位置来避免地理级别的故障带来的重大影响。这种架构确保即使某一地区遭受重大灾害,也只有部分数据受到影响,而非全部数据。一旦地区故障恢复,其他地区的备份数据可以快速恢复受影响地区的业务运行。
设计有效的数据分区架构需要综合考虑多个方面:
1.数据量数据量的大小决定了分区复杂性
例如,假设每台MySQL服务器的存储能力为500GB,那么2TB的数据需要至少4台服务器。但对于200TB的数据,简单地增加到800台MySQL服务器将极大增加管理复杂度。例如,可能每周都有服务器故障,从800台服务器中找出故障的那一两台并不简单,同时,运维复杂度也会显著提高。在地理分布上,若数据集中在一个城市,一旦发生大型灾难,风险极高。
2.分区规则
分区可以按照洲际、国家或城市等级别进行,具体采取哪种规则取决于业务需求和成本考虑。洲际分区适用于服务不同大洲的用户,由于网络延迟较大,通常用作数据备份而非实时服务。国家分区适合针对具有不同语言、法律需求的国家,通常也主要用于数据备份。城市分区则适合在同一国家或地区内提供低延迟服务,适用于异地多活等需求。
3.复制规则
即使采用了数据分区架构,每个分区仍然需要处理大量数据。单一分区的数据损坏或丢失仍然是无法接受的。因此,即使在分区架构中,也必须实施数据复制策略,以确保数据的安全和高可用性。
常见的分区复制规则有三种:集中式、互备式和独立式。
集中式备份
集中式备份系统设有一个主要的备份中心,所有的分区都将其数据传输至该中心进行备份。此架构的优点包括设计的简洁性,由于分区之间没有直接的联系,各自独立运作,互不干扰。此外,扩展性也较高,若需要添加新的分区,如武汉分区,仅需将其数据备份到已有的西安备份中心,不影响其他分区。然而,这种方式的缺点是成本相对较高,因为需要建立和维护一个独立的备份中心。
 图片
图片
互备式备份
互备式备份要求每个分区备份另一个分区的数据。这种设计较为复杂,因为每个分区不仅要处理自己的业务数据还要负责备份工作,分区间存在相互影响和依赖。扩展此系统相对困难,例如引入武汉分区可能需要重新配置广州分区的备份目标为武汉,同时还需处理原有的北京与广州的备份数据,不论是数据迁移还是保留历史数据都会带来挑战。但这种方法成本较低,因为它直接利用现有的设施。

独立式备份
独立式备份中,每个分区都拥有自己的备份中心,且备份中心不与原数据中心位于同一地点。例如,北京分区的备份设在天津,上海的备份设在杭州,广州的则设在汕头,主要目的是为了防止同城或相同地理位置的灾难同时影响主数据中心和备份中心。这种架构的优点在于设计简单,分区间互不干涉,扩展也相对简单,新分区只需建立自己的备份中心即可。然而,其缺点是成本非常高,每个分区需要单独建设和维护备份中心,地点租赁和设施成本是主要的财务负担,使得独立式备份的成本远高于集中式备份。
 图片
图片