译者 | 朱先忠
审校 | 重楼
摘要:本文将通过实际操作并结合编程方式介绍如何通过开源工具Rerun轻松实现基于开源框架MediaPipe的人体姿态跟踪的可视化呈现。
概述
本文中,我们将探索一个利用开源框架MediaPipe的功能以二维和三维方式跟踪人体姿势的使用情形。使这一探索更有趣味的是由开源可视化工具Rerun提供的可视化展示,该工具能够提供人类动作姿势的整体视图。
您将一步步跟随作者使用MediaPipe在2D和3D环境中跟踪人体姿势,并探索工具Rerun的可视化功能。
人体姿势跟踪
人体姿势跟踪是计算机视觉中的一项任务,其重点是识别关键的身体位置、分析姿势和对动作进行分类。这项技术的核心是一个预先训练的机器学习模型,用于评估视觉输入,并在图像坐标和3D世界坐标中识别身体上的地标。该技术的应用场景包括但不限于人机交互、运动分析、游戏、虚拟现实、增强现实、健康等领域。
有一个完美的模型固然很好,但不幸的是,目前的模型仍然不完美。尽管数据集可能存储了多种体型数据,但人体在个体之间是有所不同的。每个人身体的独特性都带来了挑战,尤其是对于那些手臂和腿部尺寸不标准的人来说,这可能会导致使用这项技术时精度较低。在考虑将这项技术集成到系统中时,承认不准确的可能性至关重要。希望科学界正在进行的努力将为开发更强大的模型铺平道路。
除了缺乏准确性之外,使用这项技术还需要考虑伦理和法律因素。例如,如果个人未经同意,在公共场所拍摄人体姿势可能会侵犯隐私权。在现实世界中实施这项技术之前,考虑到任何道德和法律问题都是至关重要的。
先决条件和初始设置
首先,安装所需的库:
使用MediaPipe跟踪人体姿势
 谷歌提供的姿势地标检测指南中的图像(参考文献1)
谷歌提供的姿势地标检测指南中的图像(参考文献1)
对于希望集成计算机视觉和机器学习的设备ML解决方案的开发人员来说,基于Python语言的MediaPipe框架正是一个方便的工具。
在下面的代码中,MediaPipe姿态标志检测被用于检测图像中人体的标志。该模型可以将身体姿势标志检测为图像坐标和3D世界坐标。一旦成功运行ML模型,就可以使用图像坐标和3D世界坐标来可视化输出。
从Mediapipe姿势结果集中读取二维地标位置。
从Mediapipe Pose结果集中读取三维地标位置。
跟踪并分析输入图像中的姿势。
使用Rerun可视化MediaPipe的输出
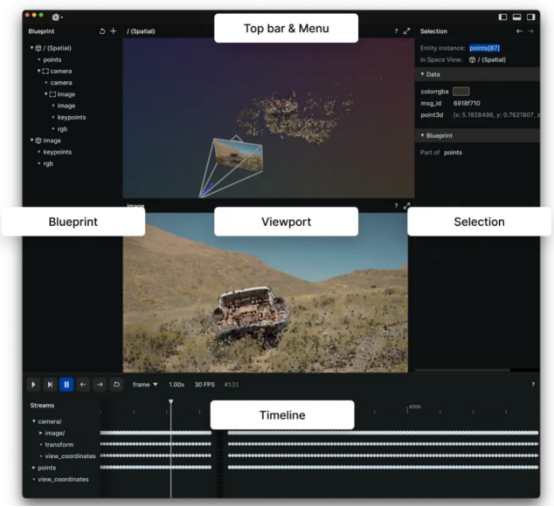 Rerun图像浏览器(图像来自于Rerun官方文档,参考资料2)
Rerun图像浏览器(图像来自于Rerun官方文档,参考资料2)
Rerun可作为多模态数据的可视化工具。通过Rerun图像浏览器,您可以构建布局、自定义可视化以及与数据交互。本节的其余部分将详细介绍如何使用Rerun SDK在Rerun图像浏览器中记录和显示数据。
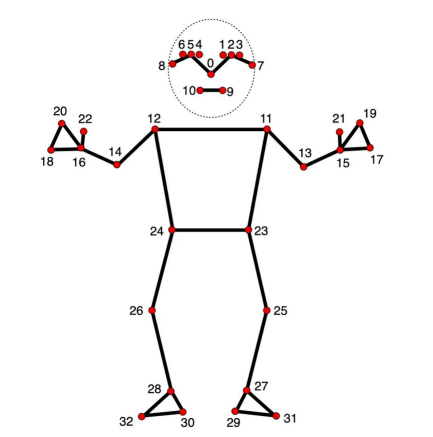 姿势标志模型(谷歌通过姿势标志检测指南拍摄的图像,参考资料1)
姿势标志模型(谷歌通过姿势标志检测指南拍摄的图像,参考资料1)
在二维和三维点中,指定点之间的连接至关重要。定义这些连接会自动渲染它们之间的线。使用MediaPipe提供的信息,可以从pose_connections集合获取姿势点连接,然后使用Annotation Context将它们设置为关键点连接。
图像坐标——二维位置
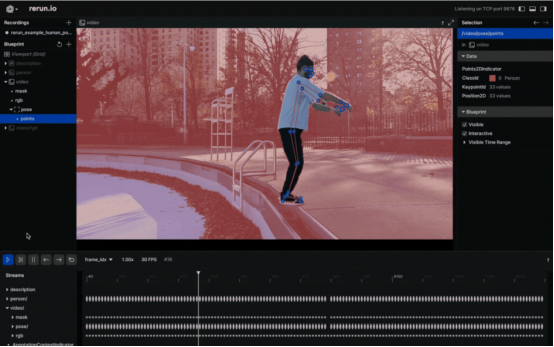 将人的姿势可视化为2D点(作者本人提供的图像)
将人的姿势可视化为2D点(作者本人提供的图像)
在视频中以可视化方式观察身体姿势的标志似乎是一个不错的选择。要实现这一点,您需要仔细遵循Rerun文档中有关Entities和Components的相关介绍。其中,“实体路径层次结构(The Entity Path Hierarchy)”页面描述了如何在同一实体上记录多个组件。例如,您可以创建“video”实体,并包括视频的“video/rgb”组件和身体姿势的“video/pose”组件。不过,如果你打算把它用于视频设计中的话,你需要认真掌握时间线的概念。每个帧都可以与适当的数据相关联。
以下是一个可以将视频上的2D点可视化的函数:
三维世界坐标——三维点
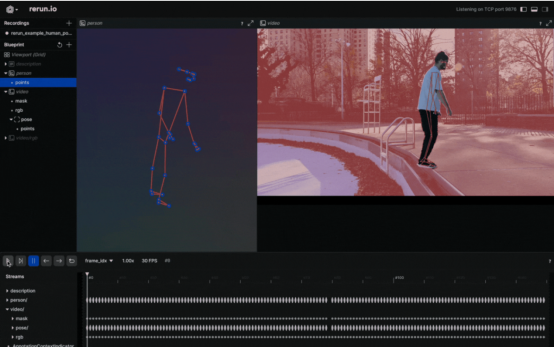 将人的姿势可视化为3D点(作者本人提供的图像)
将人的姿势可视化为3D点(作者本人提供的图像)
当你有三维点的时候,为什么要选择二维点呢?创建一个新实体,将其命名为“Person”,并输出有关这些三维点的数据。这就行了!这样就可以创建人体姿势的三维演示。
以下是操作方法:
源代码探索
本文重点介绍了“人体姿势跟踪”示例的主要部分。对于那些喜欢动手的人来说,这个例子的完整源代码可以在GitHub(https://github.com/rerun-io/rerun/blob/latest/examples/python/human_pose_tracking/main.py)上找到。您可以随意探索、修改和理解其中实现的内部工作原理。
提示和建议
1.压缩图像以提高效率
您可以通过压缩记录的图像来提高整个过程的速度:
2.限制内存使用
如果你记录的数据超过了RAM的容量,它就会开始丢弃旧数据。默认限制是系统RAM的75%。如果你想增加这个限制,可以使用命令行参数——内存限制。有关内存限制的更多信息,请参阅Rerun的“如何限制内存使用”页面信息。
3.根据您的需求定制视觉效果
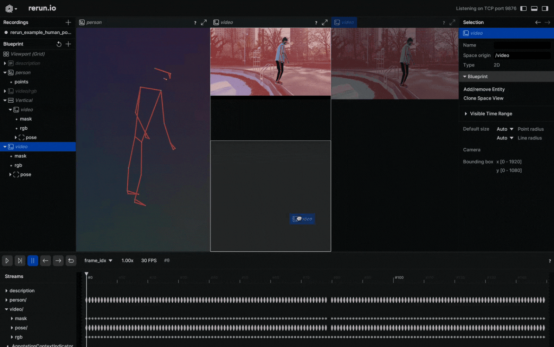 自定义Rerun查看器(作者本人提供的图像)
自定义Rerun查看器(作者本人提供的图像)
超越人体姿势跟踪
如果你觉得这篇文章有用且有些见地,下面再推荐一篇类似主题的文章:
- MediaPipe的实时手部跟踪和手势识别:Rerun应用示例
另外,我会经常分享一些关于计算机视觉和机器人的可视化教程。
参考资料
[1]谷歌公司的论文《Pose Landmark Detection Guide》,本页面的部分内容转载自谷歌创建和共享的作品,可根据Creative Commons 4.0 Attribution许可证中描述的条款使用。
[2] Rerun官方参考文档,可根据MIT许可使用。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Human Pose Tracking with MediaPipe in 2D and 3D: Rerun Showcase,作者:Andreas Naoum