一、问题:如何分析海量数据集
想象一下,您有数千亿字节的网站日志,跟踪每位访问者的互动,现在您希望从中筛选出一些信息,比如哪些页面最受欢迎,访问者在购买流程中的流失情况等。
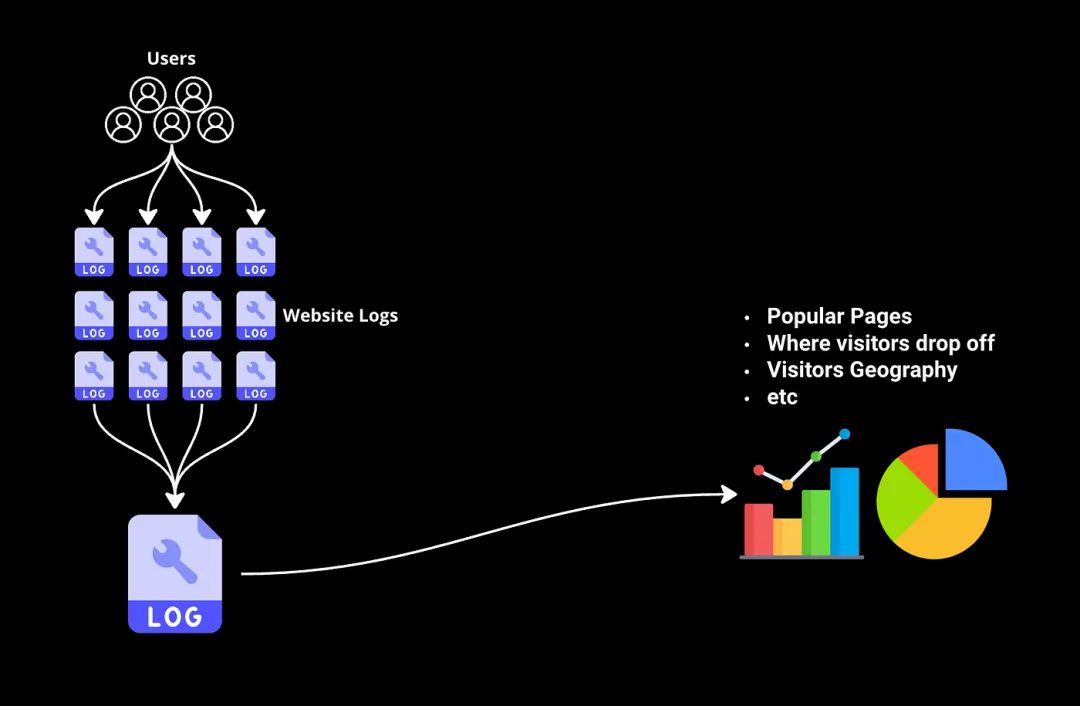
传统工具和数据库简直无法处理这种规模的数据集。这就是MapReduce派上用场的地方。
什么是MapReduce?
MapReduce是一种专门设计用于处理无法在单台计算机上处理的大规模数据挑战的编程模型。它由Google于2004年提出,旨在解决这类场景。让我们通过网站日志示例看看它是如何工作的…
二、MapReduce如何处理大数据
MapReduce分为两个主要阶段 —— Map阶段和Reduce阶段。
1.Map阶段
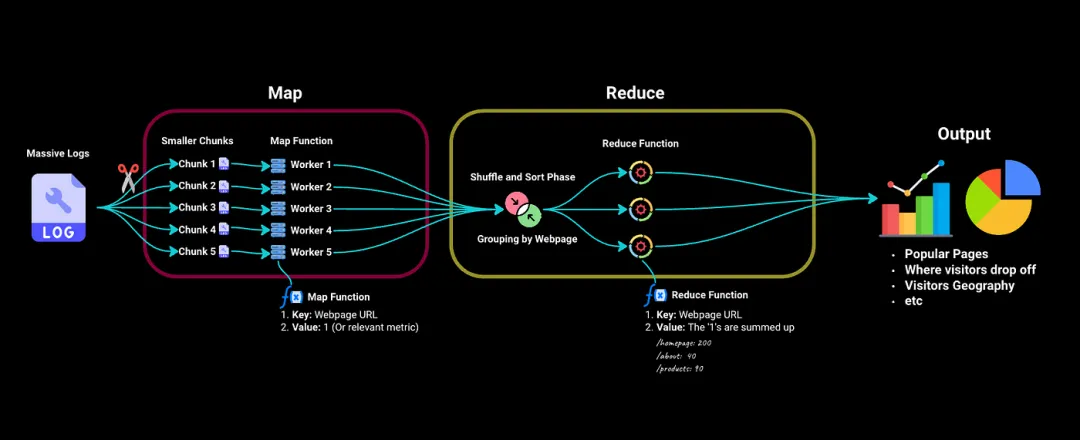
在Map阶段,我们首先将这些庞大的日志拆分为更小且易处理的块。然后将这些块发送到集群中的不同工作计算机。
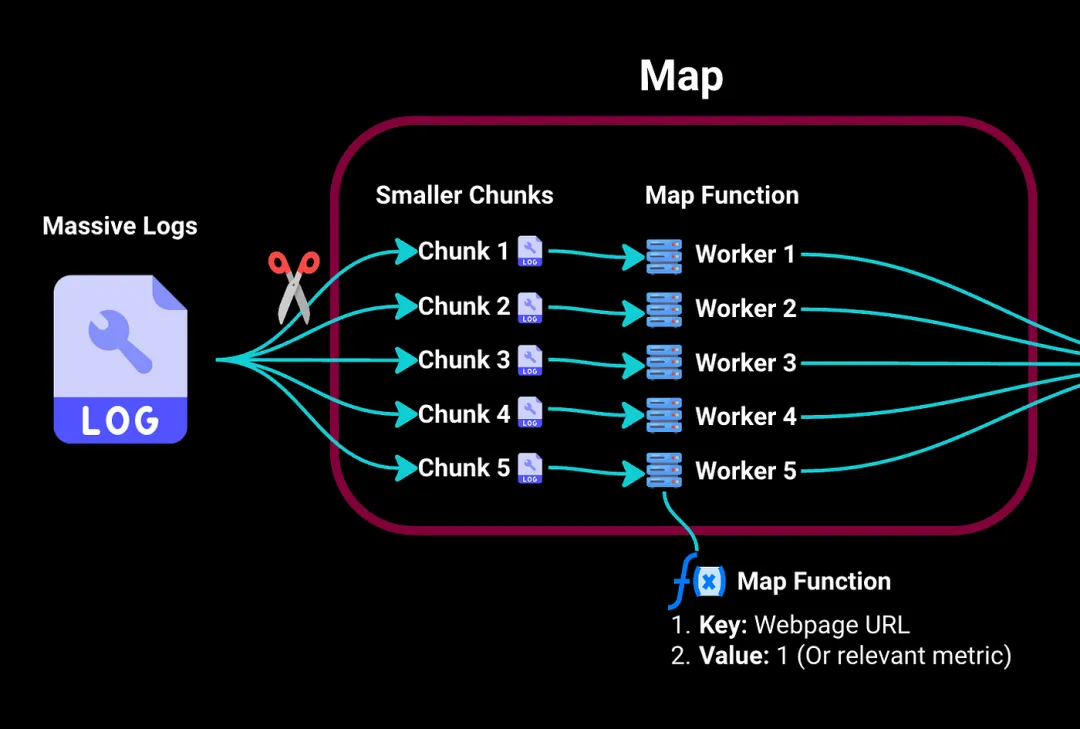
将每个工作计算机视为处理其分配块的独立服务器。它具有一个映射函数,用于提取关键信息:在我们的示例中,它将键(即特定访问的网页)映射到值,例如,如果我们要计算访问次数,值可以是访问该页面的次数(例如,1)。
2.Reduce阶段
然后,我们进入Reduce阶段,其中由Map阶段生成的所有键值对都会按网页('key')进行排序和分组。
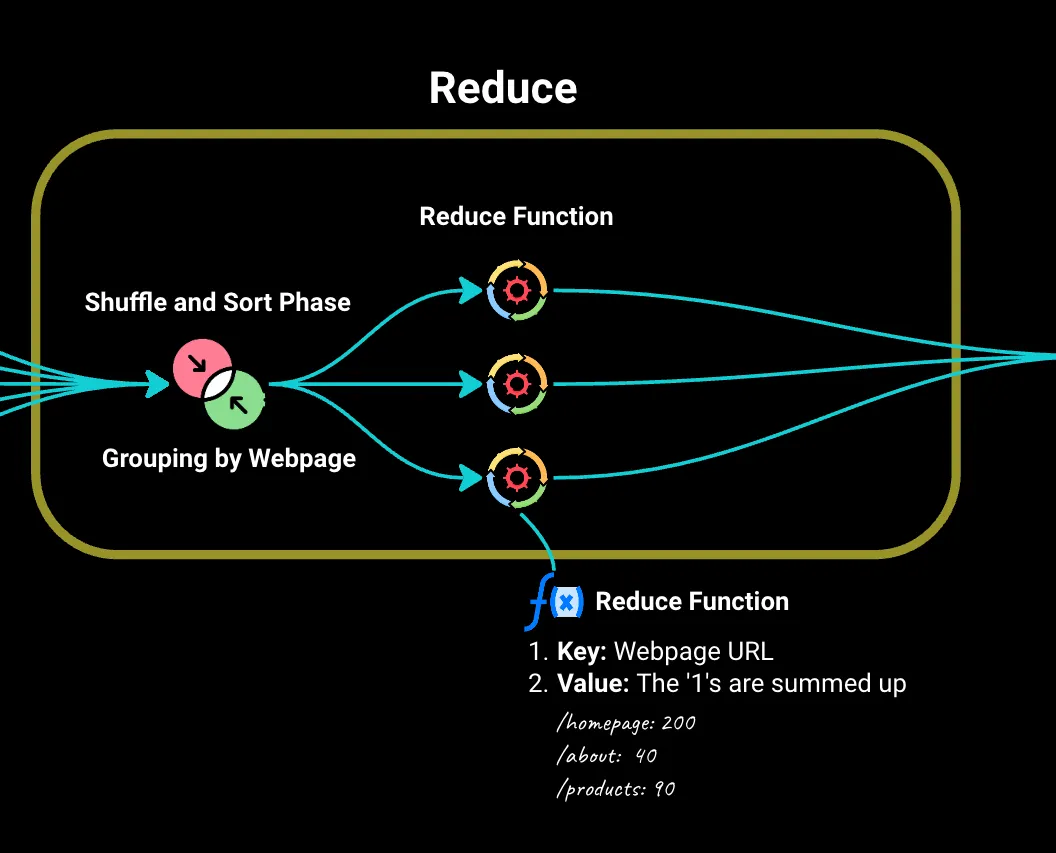
我们将这些发送到Reduce函数。对于每个唯一的网页,它会将‘1’值相加以找到总访问量。它还可以处理更复杂的问题,如平均停留时间、访客人口统计等。
现在,使用这些信息,我们可以通过图表和其他可视化方式展示。
MapReduce在日志分析中的优势:
- 并行处理能力: 分发工作使处理速度比单台计算机更快。
- 可扩展性: 有更多的日志数据?只需向集群中添加更多计算机,MapReduce就可以跟上。
- 容错性: 如果计算机在作业过程中发生故障,MapReduce会自动将其工作重新分配给网络中的其他计算机。这确保所有任务都能成功完成,而不会中断。
三、批处理与流处理
为了理解MapReduce的独特之处,让我们简要谈谈批处理与流处理:
1.批处理
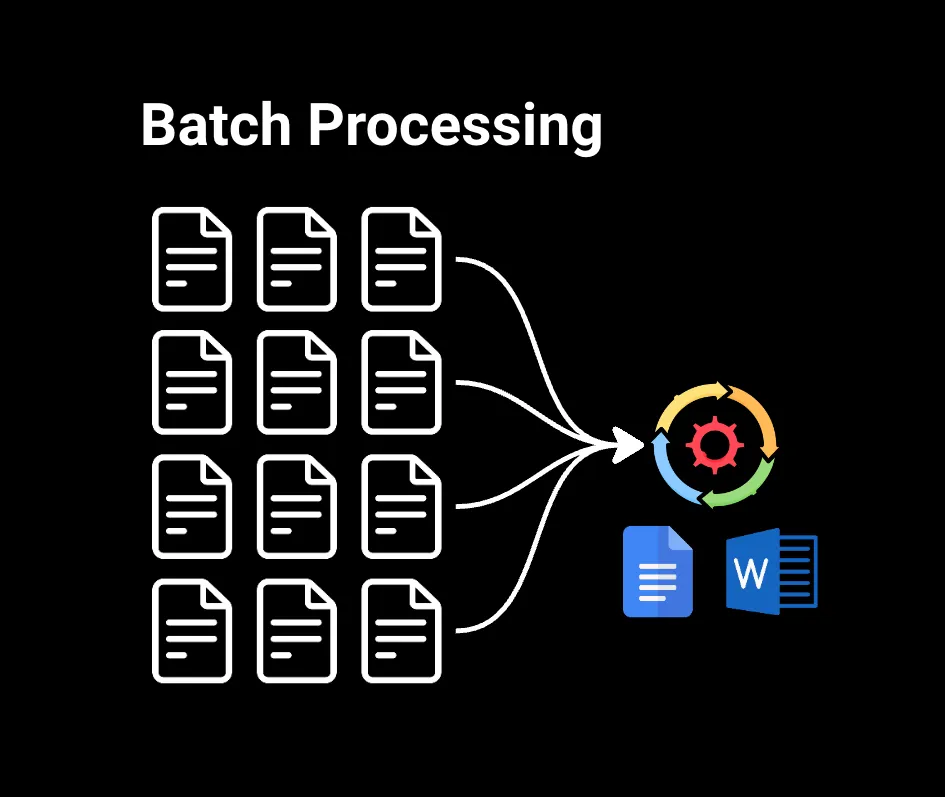
批处理处理已收集的大块数据。例如,如果您在Google Docs或Microsoft Word中搜索大型文件中的单词,数据已经准备好,因此可以立即进行处理。这对于需要处理大型数据集且不需要立即结果的情况非常有用,比如生成月度销售报告、分析客户购买历史记录或对数据进行机器学习模型训练。
2.流处理
流处理以连续流的形式处理数据。例如,观看YouTube视频时,您点击‘播放’,视频几乎立即开始播放。这是因为视频的微小片段以连续流的方式发送到您的计算机,让您在其余视频还在传输中时即可观看。
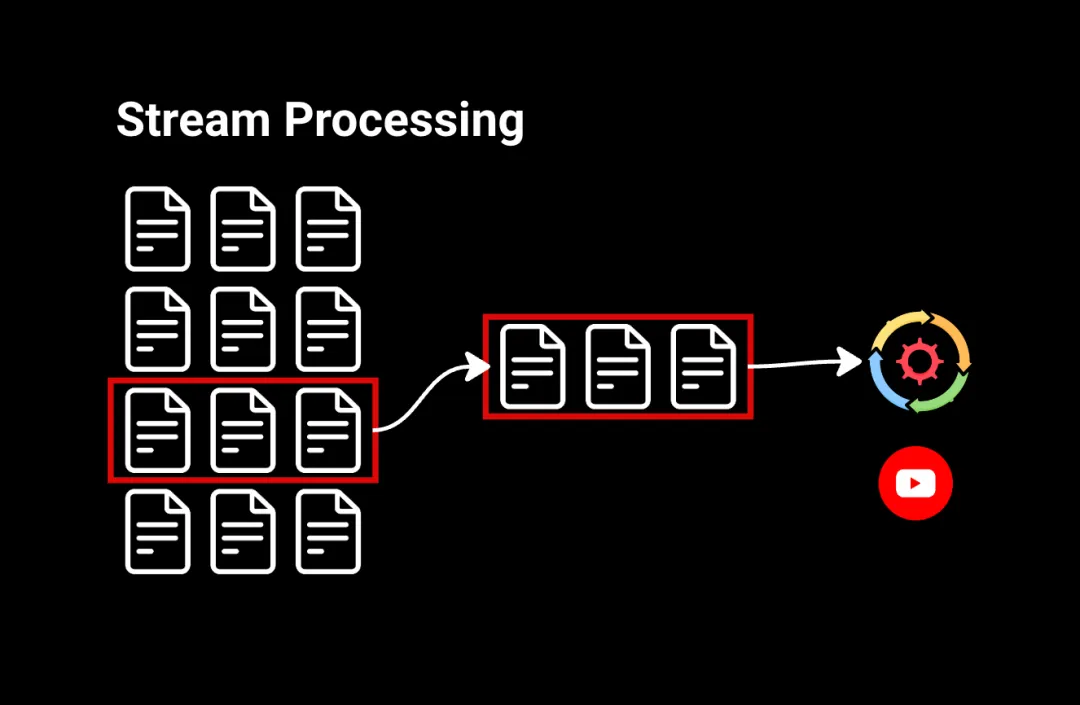
流处理适用于需要对数据流进行即时操作的情况,比如识别金融交易中的可疑活动或在社交媒体信息流中进行实时分析。
3.微批处理
我们还有微批处理,这是一种混合方法,弥合了传统批处理和流处理之间的差距。
微批处理不是将所有数据一次性处理,而是将数据拆分为非常小的批次。这些批次在短时间的固定间隔内(通常是几秒或几分钟)进行处理。
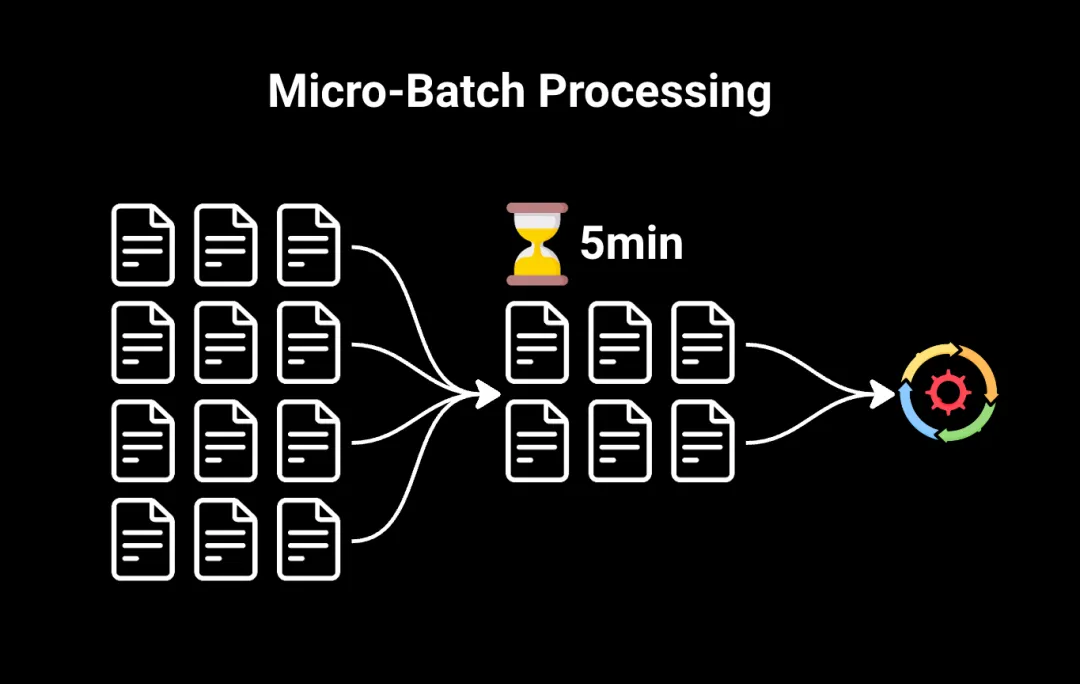
微批处理通常是需要比传统批处理更快结果的情况下的首选方法,但不需要完全的流处理。
4.MapReduce使用的处理方法是什么?
MapReduce是一种批处理模型,因为它处理的是已经存储的数据,而不是实时连续流的数据。在MapReduce的Map阶段开始之前,输入数据需要被划分和分发。
可以想象,批处理比流处理更慢,因为需要在处理之前积累数据。但是,批处理通常更简单易用,而流处理可能更复杂,因为数据不断流动,存在错误或不一致性的可能性。
四、MapReduce的局限性和现代替代方案
尽管MapReduce具有革命性,但在迭代和复杂数据处理任务的速度和灵活性方面存在局限性。这就是Apache Spark等工具发挥作用的地方。
1.Apache Spark
Spark利用内存处理,即将数据保留在RAM中进行非常快速的计算,与MapReduce依赖磁盘存储相比。它处理更广泛的任务,包括SQL查询、机器学习和实时数据处理(流处理)。
2.Apache Flink
Apache Flink是另一个用于实时数据处理(流处理)的强大框架。它提供类似于Spark Streaming的功能,允许在数据到达时立即进行分析。这是专门用于需要实时数据分析的场景的工具,通常与Spark配合使用,构建完整的大数据处理工具包。
3.Hadoop
Hadoop是一个更广泛的生态系统,为Spark和MapReduce等工具提供运行基础。它包括一个分布式文件系统(HDFS)用于在多台计算机上存储大型数据集,以及一个资源管理系统(YARN**)用于将资源(CPU、内存)分配给应用程序,如Spark或MapReduce。
可以将其视为Spark和其他工具用于管理和存储大数据的基础设施。
4.云服务(AWS、Azure、GCP)
AWS、Azure和Google等云提供商提供托管的数据处理解决方案,通常简化了MapReduce框架的使用。这些包括支持Hadoop的AWS EMR、Azure HDInsight和Google Cloud Dataflow(Google对经典MapReduce的后继产品,旨在处理批处理和流处理数据)。
五、总结
尽管对于大多数现代大数据批处理任务来说,Spark取代了MapReduce,但理解MapReduce仍然很重要,因为它为理解这些强大工具的工作原理提供了坚实的基础。