如您所见,人工智能(AI)应用在近年来得到了长足的发展。从语音助手到软件开发,人工智能已在我们的生活中无处不在,并得到了广泛应用。下面,我将为您介绍14个开源项目,您可以用它们来制作自己的人工智能应用程序,并使其更上一层楼。
12.Stable Diffusion -一种潜在的文本到图像的扩散模型

作为一种在生成模型中常被用到的技术,Stable Diffusion(https://github.com/CompVis/stable-diffusion)在文本到图像的合成中,能够将信息从文本描述逐步平稳地转移到图像。
在文本到图像的扩散模型中,Stable Diffusion可以确保来自文本的描述信息,在整个模型的潜空间中持续扩散或传播。这种扩散过程有助于生成与给定文本输入一致的高质量逼真图像。可见,稳定的扩散机制可以确保模型在生成过程中,不会出现突然的跳跃或不稳定情况。
如下代码段展示的是使用扩散器库(https://github.com/huggingface/diffusers/tree/main#new--stable-diffusion-is-now-fully-compatible-with-diffusers)下载和采样Stable Diffusion的简单方法:
通过链接--https://github.com/CompVis/stable-diffusion?tab=readme-ov-file#image-modification-with-stable-diffusion,您可以了解更多有关如何利用Stable Diffusion修改图像的方法。例如,根据下图的输入:
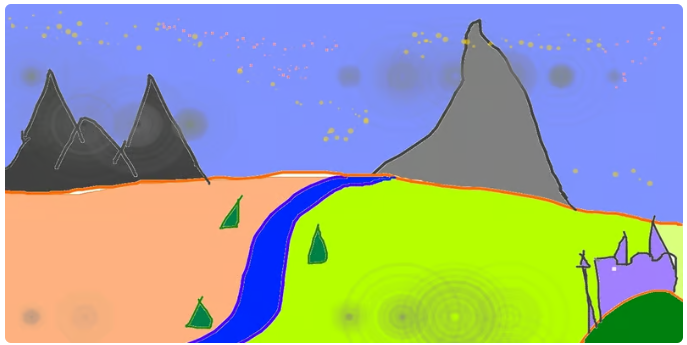
能够输出如下的提升效果:

Stable Diffusion v1是一种特定的模型配置。它采用了860M UNet和CLIP ViT-L/14文本编码器来建立扩散模型,并使用降采样因子为8的自动编码器。该模型在256x256图像上进行了预训练,随后在512x512图像上进行了微调。
目前,Stable Diffusion在GitHub代码库中拥有约六万四千多颗星。
13.MocapDrones-用于室内跟踪的低成本动作捕捉系统

由于Mocap Drones(https://github.com/jyjblrd/Mocap-Drones)项目需要使用 SFM(结构源于运动)的OpenCV模块,因此需要从源代码编译OpenCV。
在其computer_code目录下运行如下命令,您可以安装各个节点依赖项。
完成后,您将可以看到其前台界面的URL视图。
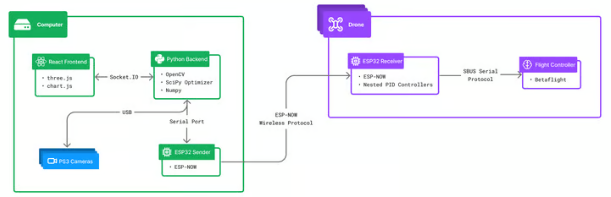
接着,您可以打开一个单独的终端窗口,运行python3 api/index.py命令,以启动后端服务器。该服务器负责接收摄像头的数据流,并执行动作捕捉的相关计算。其逻辑结构如下图所示:
若要了解Mocap drones的工作原理,您可以观看视频链接--https://www.youtube.com/watch?v=0ql20JKrscQ。此外,您还可以阅读其官方文档--https://github.com/jyjblrd/Mocap-Drones?tab=readme-ov-file#runing-the-code。
目前,其最新开源项目在GitHub存储库中有九百多颗星。
14.Whisper Speech通过反转Whisper建立从文本到语音的系统
Whisper Speech(https://github.com/collabora/WhisperSpeech)模型与Stable Diffusion相似,但是常被用于语音转换,且功能强大,可被高度定制。由于能够确保仅使用得到适当许可的语音录音,而且所有代码都是开源的,因此该模型可以被安全地用于商业应用。当然,这些模型尚只在英语LibreLight数据集上得到了训练。
您可以通过链接-- https://github.com/collabora/WhisperSpeech?tab=readme-ov-file#architecture,了解其架构信息。同时,您也可以通过链接-- https://github.com/collabora/WhisperSpeech/assets/107984/aa5a1e7e-dc94-481f-8863-b022c7fd7434,试听其样本声音。

目前,由于Whisper Speech推出时间不长,因此在GitHub上只有大约三千多颗星。
15.eSpeak NG -支持100多种语言和口音的语音合成器
作为一款小巧的、开源的、从文本到语音的合成器,eSpeak NG(https://github.com/espeak-ng/espeak-ng)适用于Linux、Windows、Android、以及其他操作系统。由于是基于Jonathan Duddington创建的eSpeak引擎,因此它能够支持100多种语言和口音。鉴于模型可以将文本转化为音素代码(phoneme codes),因此它具有作为语音合成引擎前端的潜在能力。
您可以阅读其针对各种系统的安装指南(https://github.com/espeak-ng/espeak-ng/blob/master/docs/guide.md)。其中,对于Debian之类的发行版(如Ubuntu、Mint等)而言,您可以使用如下命令:
通过链接-- https://github.com/espeak-ng/espeak-ng/blob/master/docs/languages.md,您可以查看其支持的语言列表,阅读其官方文档(https://github.com/espeak-ng/espeak-ng/tree/master?tab=readme-ov-file#documentation),并查看其各项功能(https://github.com/espeak-ng/espeak-ng/tree/master?tab=readme-ov-file#features)。
目前,eSpeak NG在GitHub上有两千七百多颗星。
16. ChatbotUI- 适用各种模型的AI聊天场景

顾名思义,Chatbot UI(https://github.com/mckaywrigley/chatbot-ui)可以协助我们为各种AI聊天机器人设置用户界面。您可以阅读其安装指南(https://github.com/mckaywrigley/chatbot-ui?tab=readme-ov-file#1-install-docker),来完成Docker和supabase CLI等安装。
通过阅读其文档(https://dev.to/taipy/all-the-tools-i-need-to-build-a-perfect-ai-app-2oeh),并观看演示程序(https://twitter.com/mckaywrigley/status/1738273242283151777?s=20),您会发现它其实使用的是Supabase(Postgres)。
目前,Chatbot UI在GitHub上拥有约两万五千多颗星。可见,它仍然是开发者为其聊天机器人构建用户界面的首选。
17.GPT-4 & LangChain -用于大型PDF文档的GPT4 & LangChain聊天机器人
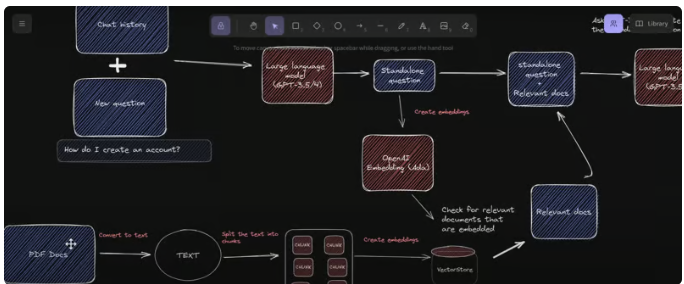
GPT-4 & LangChain(https://github.com/mayooear/gpt4-pdf-chatbot-langchain)使用LangChain、Pinecone、Typescript、OpenAI和Next.js构建。其中,LangChain是一个简化的、可扩展的AI大模型应用和聊天机器人开发的框架。而Pinecone是一个向量存储库,可用于存储各种嵌入和文本式PDF文件,以便日后检索类似的文件。
该架构可被用于新的GPT-4 API,为多个大型PDF文件构建ChatGPT聊天机器人。您可以阅读其开发指南(https://github.com/mayooear/gpt4-pdf-chatbot-langchain?tab=readme-ov-file#development),以了解克隆、安装依赖项、以及设置环境API的密钥。
目前,GPT-4 & LangChain在GitHub上拥有一万四千多颗星,以及34次提交。
18.Amica -可让你在浏览器中轻松地与3D角色聊天
Amica(https://github.com/semperai/amica)是一个开源的界面,可用于与带有语音合成和识别功能的3D动画形象进行互动交流。
由于使用了three.js、OpenAI、Whisper、以及Bakllava for vision等技术,因此您可以导入各种VRM文件,调整语音以适应选中角色,并生成包含情感表达的回应文本。Amica使用Tauri(下文会介绍到)来构建桌面应用。您也可以通过阅读《Amica是如何工作的(https://docs.heyamica.com/overview/how-amica-works)》,来了解其中涉及到的核心概念。
您可以克隆其存储库(repo)并使用如下命令以开始使用:
当然,您也可以参考其演示视频(https://amica.arbius.ai/)与相关文档(https://docs.heyamica.com/)。
目前,Amica在GitHub上有四百多颗星。
19. Hugging Face Transformers - Pytorch、TensorFlow和JAX的最先进机器学习
Hugging Face Transformers(https://github.com/huggingface/transformers)可以为文本分类、语言生成、以及问题解答等任务,提供最先进的预训练模型和算法。该库建立在PyTorch和TensorFlow的基础之上,允许用户以最小的工作量,将高级的NLP功能无缝地集成到自己的应用中。
由于拥有大量预训练模型和对应的支持性社区,因此Hugging Face Transformers简化了基于NLP方案的开发。这些模型可用于执行与文本相关的任务,如:对100多种语言进行文本分类、信息提取、问题解答、摘要、翻译以及文本生成。同时,它们也可以处理各种与图像相关的任务,如:图像分类、对象检测和分割,语音识别,以及音频分类等任务。此外,Hugging Face Transformers还可以对各种模型执行多任务处理,如:表格问题解答、光学字符识别(OCR)、从扫描文档中提取信息、视频分类、以及视觉问题解答等。
您不但可以通过链接-- https://huggingface.co/models了解更多可用的模型,而且能够在文档链接(https://huggingface.co/docs/transformers/task_summary)中查看到适合各种任务的完整目标和示例。如下代码段展示了如何使用管道方法来进行图像的分割:
如您所知,Transformers由三种最被广泛使用的深度学习库(即:Jax、PyTorch和TensorFlow)提供支持,它们之间实现了无缝的集成,因此这种集成可以使用一个库去轻松地训练模型,然后再将它们加载到另一个库进行推理。
目前,Hugging Face Transformers在GitHub上拥有约十二万多颗星,且被十四万二千多开发人员所广泛使用。
20.LLaMA - LLaMA模型的推理代码

作为Facebook研究中心开发的一项尖端技术,Llama 2(https://github.com/facebookresearch/llama)可以让个人、创作者、研究人员和各种规模的企业,都能够利用大模型进行实验、创新、以及负责任地去扩展其想法。
Llama 2的最新版本包含了各种模型权重和启动代码,它们都是参数范围从7B到70B的预训练和微调的Llama语言模型。根据安装指南--https://github.com/facebookresearch/llama?tab=readme-ov-file#quick-start,您可以遵循如下步骤来完成安装:
- 克隆并下载软件源。
- 安装所需的依赖项。
- 注册并从Meta网站处下载模型。
- 运行已提供的脚本下载模型。
- 使用已提供的命令在本地运行所需的模型。
您也可以在Hugging Face(https://huggingface.co/meta-llama)和Meta官方网页(https://llama.meta.com/)上查看更多的模型名单信息。
目前,Llama在GitHub上有五万多颗星。
21.Fonoster - Twilio的开源替代品

作为一种创新的可编程电信栈,Fonoster(https://github.com/fonoster/fonoster)能够为企业提供一种完全基于云的实用程序,以将电话服务与互联网连接起来。
您可以根据不同的实现目标,以不同的方式开启使用。例如,您可以使用如下npm命令:
同时,您可以将Fonoster与Google Speech API结合起来使用 (当然,您需要有服务账户的密钥)。
如下代码段展示的是使用插件配置语音服务器(Voice Server)的方法。
您可以阅读文档(https://fonoster.com/docs/overview/)。
他们提供免费层级,足以满足入门需求。
目前,Fonoster在GitHub上有大约六千多颗星,并且发布了250多个版本。
22. DIPY - Python中的Paragon 3D/4D+成像库

作为业界领先的Python 3D/4D+成像库,DIPY(https://github.com/dipy/dipy)包含各种用于空间归一化、信号处理、机器学习、统计分析、以及医学图像可视化的方法。同时,它也包含了诸如:扩散、灌注和结构成像等用于计算解剖学的专门方法。
您可以从如下命令开始上手DIPY:
DIPY提供的官方文档(https://docs.dipy.org/stable/)提供了如下图所示的各种详细示例(https://docs.dipy.org/stable/examples_built/index.html)。

目前,DIPY在GitHub存储库中有四十二万八千多下载量和六百多颗星。
23.Elastic Search -免费、开放、分布式的RESTful搜索引擎
Elastic Search(https://github.com/elastic/elasticsearch)是一个分布式的RESTful搜索和分析引擎,能够处理大量的用例。而作为Elastic Stack的核心,它可以集中式地存储您的数据,以实现闪电般快速的搜索、相关性微调、强大的分析功能,以及可以轻松地扩展。下图展示了各种可以使用Elastic Search的用例。

由于Elastic Search使用的是标准化的RESTful API和JSON,因此我们也使用Java、Python、.NET、SQL和PHP等多种语言来构建和维护客户端。下面展示了其基本结构:
您可以通过阅读文档(https://dev.to/taipy/all-the-tools-i-need-to-build-a-perfect-ai-app-2oeh),来查看其功能列表(https://www.elastic.co/elasticsearch/features)。尽管Elastic Search功能强大,但是其主要缺点是并非免费。当然,你仍然可以利用其免费的试用版,来探究该开源项目的架构。
目前,Elastic Search已经发布了第8版,并正在不断开发和完善中。在GitHub上它有超过六万七千多颗星,有近1900名贡献者。
24. Tauri -利用Web前端构建更小、更快、更安全的桌面应用
Tauri(https://github.com/tauri-apps/tauri)是一个工具包,旨在帮助开发人员利用几乎所有可用的前端框架,为桌面平台创建应用程序。其内核是使用Rust开发的,而CLI则使用Node.js为开发和维护应用提供了一种真正的多语言方法。
Tauri应用的用户界面目前在macOS、Windows、Linux、Android和iOS上都使用Tao作为窗口处理库。而为了应用,Tauri也使用了WRY库,这一为系统WebView所提供的统一接口库。也就是说,它会利用macOS和iOS上的WKWebView、Windows上的WebView2、Linux上的WebKitGTK、以及Android上的Android System WebView。
您可以使用如下npm命令开始使用Tauri。
您既可以阅读其文档--https://tauri.app/v1/guides/getting-started/prerequisites,也可以通过查看其功能列表--https://tauri.app/v1/guides/features/,来制作自己的CLI。
目前,Tauri在GitHub上拥有七万五千多颗星,并已发布了800多个版本。
25.AutoGPT- 比ChatGPT更刺激
AutoGPT(https://github.com/Significant-Gravitas/AutoGPT)的核心是一个由大模型(LLM)驱动的半自主代理项目。该项目由如下四个主要部分(https://docs.agpt.co/#agent)组成:
- 代理- 也称为“AutoGPT”
- 基准 - 又名agbenchmark
- 构建台(Forge)
- 前台
通过阅读链接--https://docs.agpt.co/autogpt/setup/,您可以了解如何使用OpenAI的密钥来设置AutoGPT。同时,您也可以阅读其官方文档(https://docs.agpt.co/)、以及查看项目板(https://github.com/orgs/Significant-Gravitas/projects/1),了解目前正在开发的内容。
由于其出色的用例和自动化功能,AutoGPT目前在GitHub库上拥有约十五万九千多颗星。
译者介绍
陈峻(Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。
原文标题:All the tools I need to build a perfect AI app. ,作者:Anmol Baranwal
链接:https://dev.to/taipy/all-the-tools-i-need-to-build-a-perfect-ai-app-2oeh。