














背景
当今社会,人们使用大量数据训练包含数百万和数十亿模型参数的大型语言模型(LLM),目标是生成文本,如文本完成、文本摘要、语言翻译和回答问题。虽然LLM都是从给定的训练数据源开始来开发知识库本身,但是其中总有一个截止训练日期的问题,这导致了LLM不会知道在以后的新日期内的任何新生成的数据。
例如,训练OpenAI的GPT-3.5-turbo-instruct LLM的截止日期为2021年9月(参考:https://platform.openai.com/docs/models/gpt-3-5-turbo);因此,GPT-3.5-turbo-instruct LLM可能无法准确回答与2022年、2023年或2024年中发生的事件有关的问题。这种不是LLM的原始训练数据的部分数据被称为外部数据。
正是在这种情况下出现了检索增强生成(RAG)技术,这种技术能够通过从授权的外部来源中检索与输入提示相关的适当信息,并能够增强输入,从而使LLM能够生成准确和相关的响应。实际上,RAG形成了LLM和外部数据之间的一个网关。这种增强消除了对LLM模型进行再训练或进一步微调的需要。
LLM的典型实现方案
LLM是自回归的,基于标记为标记序列的输入提示,从而生成新的标记。下一个最佳标记的生成是基于概率的,并且可以表示如下:
P( Yn∣X0, X1, ... Xn-1, θ )
本质上,新生成的第n个标记Yn的概率取决于n-1个先前标记序列X和学习的模型参数θ的出现概率。这里应该注意的是,标记化的输入序列X在生成下一个标记中起着至关重要的作用。此外,自注意机制补充了有效的自回归,其中序列中的每个输入标记通过关注和权衡序列中其他标记的重要性来计算其表示。
序列中的标记之间的这种复杂关系和依赖性也使LLM能够破译与输入序列中的标记“很好地结合”的最可能的次优标记。LLM将新的标记附加到先前的标记以形成新的输入序列,并重复自回归过程,直到满足完成条件,例如达到最大标记计数。
这种自关注驱动的自回归意味着,LLM主要依赖于输入序列来生成次优标记。只要输入序列有助于通过自我关注来确定下一个最佳标记,LLM就会继续处于“良性”循环中,从而产生连贯、可理解和相关的输出。相反,如果提示输入无助于确定下一个最佳标记,则LLM将开始依赖于模型参数。在这种情况下,如果模型已被训练为包含足够的输入提示上下文的“知识”,则该模型可能成功生成下一个最佳标记。相反,如果提示输入与LLM从未训练过的“外部数据”有关,则模型可能会进入“恶性循环”,导致产生不连贯、不可理解且可能不相关的输出。
当前人们已经研究出多种技术来解决这个问题。提示工程就是其中之一,其目标是通过调整提示来增强上下文,从而使LLM能够生成相关输出,从而解决“缺失的上下文”。RAG则是另一种技术,其目标是通过以自动化的方式从外部数据源检索与输入提示相关的最合适的信息并增强提示,来专门解决“由于外部数据而丢失的上下文”。
RAG面临的挑战
RAG的主要职责是从外部数据源(如信息数据库、API和维基百科等其他文档库)中搜索和检索与输入提示上下文相关的数据。一个简单的关键词搜索并不能解决这个问题。相反,RAG需要一个语义搜索。为了便于语义搜索,从外部来源检索的文本信息被转换为数字表示或向量,通常称为文本嵌入,并存储在向量数据库中。已经存在多种模型或算法,用于从文本创建这些嵌入。首先,提示被转换为其向量表示,以搜索和检索最匹配的外部数据向量。然后,计算提示向量和先前存储的外部数据向量之间的向量相似性(或向量距离)。使用阈值对最相似或最接近的向量进行排序和过滤,并检索它们对应的文本信息以增强提示的上下文。下面的概念图展示了启用RAG的不同组件之间的典型交互:
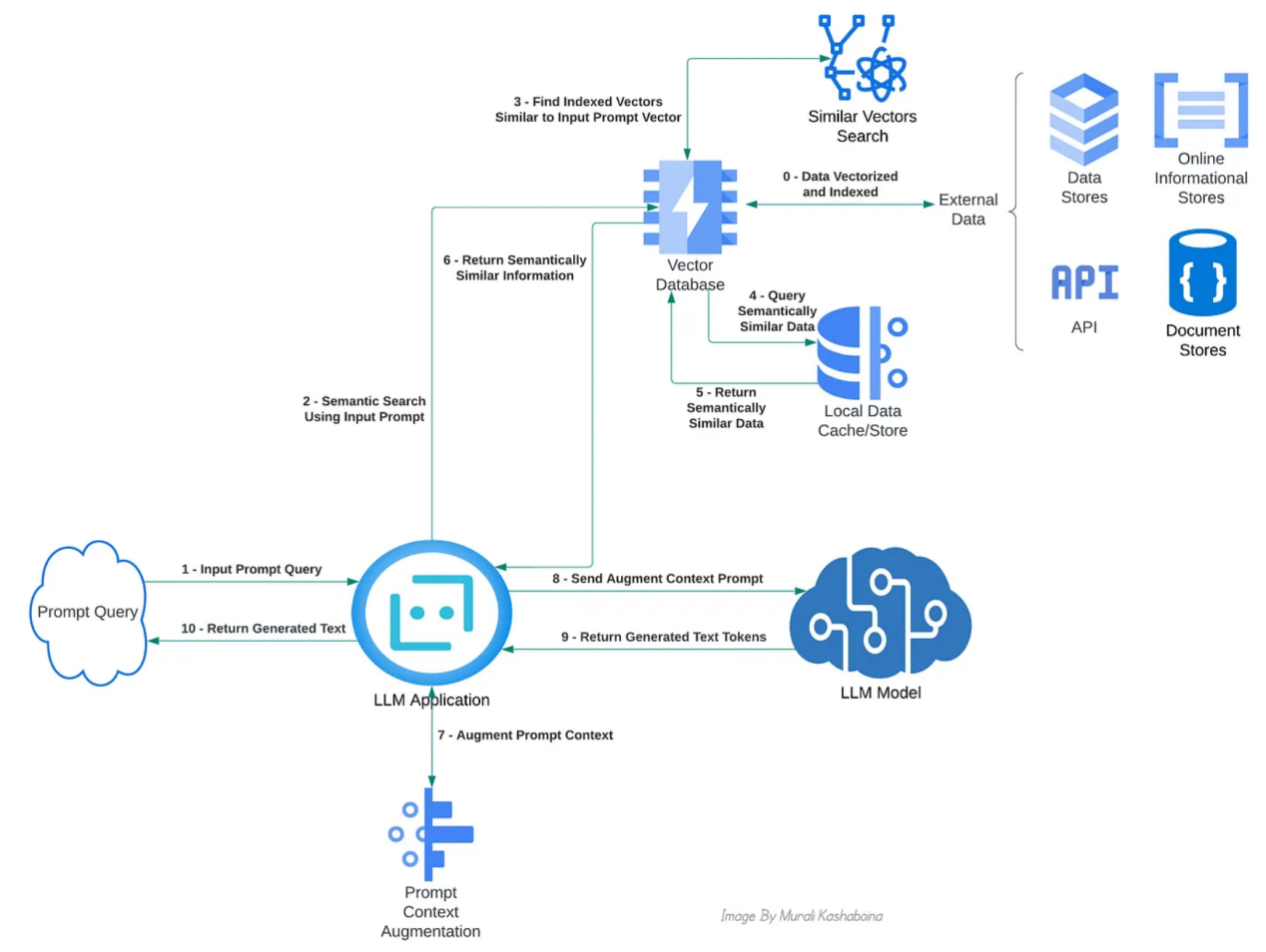
实现RAG的主要系统组件交互的概念视图(作者本人图片)
RAG面临的挑战是,进行向量驱动的语义搜索并不简单,需要大量的计算资源,因为它涉及到针对数据库中潜在的大量向量计算向量相似性或距离。对于每个输入提示,从庞大的向量数据库中计算每个存储向量的相似性或距离指标将变得不可行。此外,语义匹配质量越低,LLM的生成输出质量就越低。因此,找到一种有效地进行语义搜索的方法变得至关重要。
解决方案
当前,可以采用几种算法解决方案来进行高效的语义搜索。这些算法的典型思路是,将外部数据向量分组或聚类为最近邻居,并通过映射到这样的聚类来对它们进行索引。大多数向量数据库都提供这种索引作为内置功能。在语义搜索期间,首先针对输入提示向量来评估匹配的聚类。对于每个评估的簇,都会选择索引向量。然后计算输入提示向量和所选向量之间的相似性。这里的期望是,找到“最近的邻居”作为中间步骤,可以显著减少相似性计算的数量。最后,检索与通过阈值滤波的最相似或最接近的向量相对应的文本信息。诸如k-最近邻、半径球-R、位置敏感哈希、DBSCAN聚类、类树层次结构和类图层次结构之类的算法通常由向量数据库实现,以便于语义搜索。
当然,不存在一刀切的解决方案,因为不同的算法族在内存效率、计算效率、延迟、准确性、向量维度、数据集大小等方面有不同的权衡。例如,聚类方法通过缩小语义搜索的向量空间来提高速度,而类树或类图方法则提高了低维向量数据的准确性。
自组织映射
自组织映射(SOM)是芬兰神经网络专家Teuvo Kohonen在20世纪80年代开发的一种基于神经网络的降维算法。它通常用于将高维特征向量减少为低维(通常是二维)特征向量。SOM背后的核心思想是,将高维数据向量表示为低维空间中的特定节点,同时保留向量在原始空间中的拓扑结构。低维空间中的节点数(SOM节点)是固定的(超参数)。通过多个训练时期来评估SOM节点的确切位置。迭代训练的目标是调整低维空间中SOM节点的位置,以便将它们映射到高维特征空间中最近的相邻向量。换言之,目标是将高维空间中的最近邻向量映射到也是低维空间中最近邻的SOM节点。
RAG的SOM
在这篇文章中,我想分享我用SOM作为一种可能的算法来推动RAG的语义搜索的实验笔记和有关发现。与其他算法相比,SOM可能更为理想一些,这基于以下三个关键原因:
- 向量的高维度可能会成为大多数其他算法的瓶颈,如树和图,即所谓的维度诅咒。相反,SOM是为降维而构建的;因此,它可以有效地应用于高维和低维场景。
- SOM对可能渗入原始高维向量空间的随机变化不太敏感,从而导致噪声。其他算法可能对这种噪声敏感,影响它们将高维向量聚类或分组为最近邻的方式。由于SOM在低维向量空间中使用中间SOM节点,这些节点被评估为来自高维空间的映射向量的局部平均值,因此它有效地减少了噪声。
- 外部数据集的大尺寸可能会约束其他算法来创建语义向量空间,这可能会影响语义匹配的延迟和准确性。另一方面,SOM可以处理海量数据集,因为低维空间中的SOM节点数量可以通过与底层数据集大小成比例的超参数进行微调。虽然使用大型数据集训练SOM可能需要更长的时间,但一旦训练完成,查询时间映射仍然更快。
对此,我展示了一个简单的例子。在这个例子中,使用SOM进行RAG的语义搜索,以使用OpenAI的GPT-3.5-turbo-instruct LLM来增加问答的上下文。使用OpenAI的GPT-3.5-turbo-instruct LLM的主要原因是,训练OpenAI的GPT-3.5-turbo-instruct LLM的截止日期是2021年9月(参考:https://platform.openai.com/docs/models/gpt-3-5-turbo);因此,GPT-3.5-turbo-instruct LLM可能无法准确回答2022年、2023年或2024年发生的事件相关的问题。因此,关于2022年、2023年或2024年发生的事件的信息可以成为OpenAI的GPT-3.5-turbo-instruct LLM的“外部数据”。我使用维基百科API作为这种“外部数据”的来源来获取事件的信息。以下展示我用来开发和训练示例的步骤,以及示例代码。
步骤1:基于PyTorch的Kohonen的SOM实现
示例中,我利用PyTorch张量来表示向量,并使用PyTorch实现了Kohonen的SOM。该算法使用了一个二维晶格,其大小变为超参数。该算法的数学方面是从精心设计的角度得出的,并在以下文章中进行了清晰的解释:
下面的代码片段显示了Kohonen的SOM的Python类。完整的代码可在GitHub(https://github.com/kbmurali/som-driven-qa-rag/blob/main/kohonen_som.py)获得。值得注意的是,这个实现是独立的,所以它可以在RAG示例之外使用。
class KohonenSOM():
"""
该代码是基于以下文章开发的:
http://www.ai-junkie.com/ann/som/som1.html
向量和矩阵运算是使用PyTorch张量进行的。
"""
def __init__( ... )
...
def find_topk_best_matching_units( self, data_points : torch.Tensor, topk : int = 1 ) -> List[ List[ int ] ] :
if len( data_points.size() ) == 1:
#batching
data_points = data_points.view( 1, data_points.shape[0] )
topk = int( topk )
distances = self.dist_evaluator( data_points, self.lattice_node_weights )
topk_best_matching_unit_indexes = torch.topk( distances, topk, dim=1, largest=False ).indices
topk_best_matching_units = []
for i in range( data_points.shape[0] ):
best_matching_unit_indexes = topk_best_matching_unit_indexes[i]
best_matching_units = [ self.lattice_coordinates[ bmu_index.item() ].tolist() for bmu_index in best_matching_unit_indexes ]
topk_best_matching_units.append( best_matching_units )
return topk_best_matching_units步骤2:基于SOM的向量索引器实现
向量索引器是一种实用程序,它使用Kohonen的SOM来使用外部数据集的数据向量训练SOM节点。它的主要目的是将每个数据向量映射到最近的top-k SOM节点,从而实现数据向量的高效索引。下面的代码片段显示了向量索引器Python类的train和索引函数。它的完整代码可在GitHub(https://github.com/kbmurali/som-driven-qa-rag/blob/main/vector_indexer.py)获得。尽管它的实现目前仅限于示例的需要,但它可以扩展以满足其他要求。
class SOMBasedVectorIndexer():
...
def train_n_gen_indexes(
self, input_vectors : torch.Tensor,
train_epochs : int = 100
):
if self.generated_indexes:
print( "WARNING: Indexes were already generated. Ignoring the request..." )
return
self.som.train( input_vectors, train_epochs )
topk_bmu_indexes = self.som.find_topk_best_matching_units( input_vectors, topk = self.topk_bmu_for_indexing )
for idx in tqdm( range( len( topk_bmu_indexes ) ), desc="SOM-Based Indexed Vectors" ):
bmu_indexes = topk_bmu_indexes[ idx ]
for bmu_index in bmu_indexes:
bmu_index_key = tuple( bmu_index )
idx_set = self.som_node_idx_map.get( bmu_index_key, set() )
idx_set.add( idx )
self.som_node_idx_map[ bmu_index_key ] = idx_set
self.generated_indexes = True步骤3:基于OpenAI嵌入的文本到向量编码器
编码器的主要功能是使用OpenAI的文本嵌入API将文本转换为向量表示。值得注意的是,使用嵌入API需要一个OpenAI帐户和API密钥。首次开立账户后,OpenAI提供补充信贷,足以访问API进行测试。下面是一个代码片段,展示了OpenAI编码器Python类的批处理编码功能。完整的代码也可在GitHub(https://github.com/kbmurali/som-driven-qa-rag/blob/main/openai_vector_encoder.py)获得。
import openai
from openai.embeddings_utils import get_embedding
...
from vector_encoder_parent import VectorEncoder
...
class OpenAIEmbeddingsVectorEncoder( VectorEncoder ):
def __init__( ... )
...
def encode_batch( self, list_of_text : List[ str ] ) -> torch.Tensor :
if list_of_text == None or len( list_of_text ) == 0:
raise ValueError( "ERROR: Required list_of_text is None or empty" )
list_of_text = [ str( text ) for text in list_of_text ]
openai.api_key = self.openai_key
response = openai.Embedding.create(
input = list_of_text,
engine = self.vector_encoder_id
)
embeddings = [ data["embedding"] for data in response["data"] ]
vectors = torch.tensor( embeddings, dtype=torch.float )
return vectors请注意,OpenAI向量编码器类扩展了一个通用父类“VectorEncoder”,该类定义了要通过继承实现的抽象编码函数。通过从这个父类继承其他编码方案的可插入性,可以实现其他类型的向量编码器。父向量编码器类的完整代码可以在GitHub(https://github.com/kbmurali/som-driven-qa-rag/blob/main/vector_encoder_parent.py)找到。
步骤4:Wikipedia API驱动的数据源实现
该实用程序类旨在封装与Wikipedia API集成的数据检索逻辑。它的主要功能是获取一个指定的日历年数组中的事件,格式化检索到的事件,并将它们加载到Pandas数据帧中。下面的代码片段捕获了实用程序类的主要函数,完整的代码也可在同上一致的GitHub位置获得。
import requests
import pandas as pd
from dateutil.parser import parse
...
class WikiEventsDataSource():
...
def fetch_n_prepare_data( self ):
if self.fetched:
print( "WARNING: Wiki events for the specified years already fetched. Ignoring the request..." )
return
main_df = pd.DataFrame()
for year in self.event_years_to_fetch:
wiki_api_params = {
"action": "query",
"prop": "extracts",
"exlimit": 1,
"titles": year,
"explaintext": 1,
"formatversion": 2,
"format": "json"
}
response = requests.get( "https://en.wikipedia.org/w/api.php", params=wiki_api_params )
response_dict = response.json()
df = pd.DataFrame()
df[ "text" ] = response_dict["query"]["pages"][0]["extract"].split("\n")
df = self.__clean_df__( df, year )
main_df = pd.concat( [ main_df, df ] )
self.df = main_df.reset_index(drop=True)
self.fetched = True步骤5:基于SOM的RAG实用程序实现
基于SOM的RAG实用程序是示例实现的关键环节。它利用向量编码器、索引器和数据源来实现底层语义搜索的核心逻辑。基于SOM的RAG实用程序的完整代码可在同上一致的GitHub位置获得。
该实用程序实现三个主要函数。第一个函数是从外部数据源加载数据,并将其编码为向量,如下面的代码片段所示。
...
from vector_encoder_parent import VectorEncoder
from vector_indexer import SOMBasedVectorIndexer
class SOM_Based_RAG_Util():
...
def load_n_vectorize_data( self, data_source ):
if self.data_loaded_n_vectorized:
print( "WARNING: Data already loaded and vectorized. Ignoring the request..." )
return
data_source.fetch_n_prepare_data()
self.df = data_source.get_data()
vectors = None
for i in tqdm( range(0, len(self.df), self.vectorize_batch_size ), desc="Vectorized Data Batch" ):
list_of_text = self.df.iloc[ i:i+self.vectorize_batch_size ]["text"].tolist()
batch_encoded_vectors = self.vector_encoder.encode_batch( list_of_text )
if vectors == None:
vectors = batch_encoded_vectors
else:
vectors = torch.cat( [ vectors, batch_encoded_vectors], dim=0 )
self.vectors = vectors.to( self.device )
self.data_loaded_n_vectorized = True第二个函数是训练基于SOM的索引器来构造Kohonen的SOM节点,然后对数据向量进行索引,如下面的代码片段所示。
def train_n_index_data_vectors( self, train_epochs : int = 100 ):
if not self.data_loaded_n_vectorized:
raise ValueError( "ERROR: Data not loaded and vectorized." )
if self.data_vectors_indexed:
print( "WARNING: Data vectors already indexed. Ignoring the request..." )
return
self.vector_indexer.train_n_gen_indexes( self.vectors, train_epochs )
self.data_vectors_indexed = True第三个函数是基于查询文本从先前存储的外部数据集中查找类似信息。此函数使用编码器将查询文本转换为向量,然后在基于SOM的索引器中搜索最可能的匹配项。然后,该函数使用余弦相似性或另一个指定的相似性评估器来计算查询向量和所发现的数据向量之间的相似性。最后,该函数对相似度大于或等于指定相似度阈值的数据向量进行滤波。下面的代码片段捕获了函数实现。
def find_semantically_similar_data( self, query: str, sim_evaluator = None, sim_threshold : float = 0.8 ):
if not self.data_vectors_indexed:
raise ValueError( "ERROR: Data vectors not indexed." )
if query == None or len( query.strip() ) == 0:
raise ValueError( "ERROR: Required query text is not specified." )
sim_threshold = float( sim_threshold )
if sim_evaluator == None:
sim_evaluator = nn.CosineSimilarity(dim=0, eps=1e-6)
query_vector = self.vector_encoder.encode( query )
query_vector = query_vector.view( self.vector_encoder.get_encoded_vector_dimensions() )
query_vector = query_vector.to( self.device )
nearest_indexes = self.vector_indexer.find_nearest_indexes( query_vector )
nearest_indexes = nearest_indexes[0]
sim_scores = []
for idx in nearest_indexes:
data_vector = self.vectors[ idx ]
data_vector = data_vector.view( self.vector_encoder.get_encoded_vector_dimensions() )
sim_score = sim_evaluator( query_vector, data_vector )
if sim_score >= sim_threshold:
sim_score_tuple = (idx, sim_score.item() )
sim_scores.append( sim_score_tuple )
sim_scores.sort( key = lambda x: x[1], reverse=True )
semantically_similar_data = [
{
'text': self.df[ 'text' ][ idx ],
'sim_score' : sim_score
} for idx, sim_score in sim_scores
]
return semantically_similar_data基于SOM的RAG实用函数的语义搜索的示例输出如下所示:

一个示例语义搜索输出(作者本人图像)
步骤6:抽象问答/聊天机器人及其基于OpenAI的实现
我开发了一个抽象的“QuestionAnswerChatBot”Python类,以便加快类聊天机器人的实现。这个类通过使用标准指令模板并使用从RAG实用程序检索到的上下文相似信息来填充提示问题。
指定的新标记的最大数量限制了上下文增强的文本大小,而标记计数则推迟到底层实现。在LLM经济学中,标记就像货币。模型处理的每个标记都需要计算资源——内存、处理能力和时间。因此,LLM必须处理的标记越多,计算成本就越大。
最后,一旦提供了QA指令,这个类就将LLM模型的提示委托给底层实现。下面的代码片段给出了关键部分的函数实现代码;完整的代码可在同上面代码相同的GitHub位置获得。
from abc import ABC, abstractmethod
import torch
import math
class QuestionAnswerChatBot( ABC ):
...
def find_answer_to_question( self, question : str, sim_threshold = 0.68, max_new_tokens : int = 5 ):
if question == None or len( question.strip() ) == 0:
raise ValueError( "ERROR: Required question is not specified" )
sim_threshold = float( sim_threshold )
max_new_tokens = int( max_new_tokens )
qa_instruction = self.get_qa_instruction( question, sim_threshold = sim_threshold )
answer_text = self.__get_answer_text__( qa_instruction, max_new_tokens = max_new_tokens )
answer_text = self.__clean_answer_text__( qa_instruction, answer_text )
return answer_text
...
def __qa_template__( self ):
qa_template = """Context:
{}
---
Question: {}
Answer:"""
return qa_templatePython类“OpenAIQuestionAnswerChatBot”扩展了抽象类“QuestionAnnswerChatbot”,并使用OpenAI LLM API实现聊天机器人功能。下面的代码片段显示了该类的关键函数代码。完整的代码也可在上面GitHub位置获得。
import openai
import tiktoken
from qa_chatbot import QuestionAnswerChatBot
class OpenAIQuestionAnswerChatBot( QuestionAnswerChatBot ):
...
def __get_answer_text__( self, qa_instruction : str, max_new_tokens : int = 5 ) -> str :
openai.api_key = self.openai_key
basic_answer = openai.Completion.create(
model = self.openai_model_name,
prompt = qa_instruction,
)
answer_text = basic_answer[ "choices" ][0][ "text" ]
return answer_text
def __token_count__( self, text : str ):
return len( self.tokenizer.encode( text ) )以下是如何使用通过语义搜索检索到的类似信息来增强提示问题的上下文的示例:
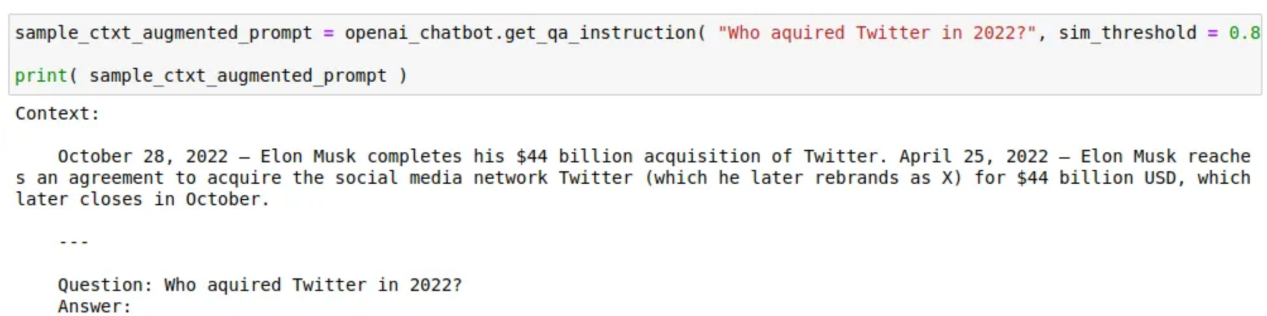
一个样本版本的上下文增强的问题提示(作者图片)
步骤7:测试中使用的示例问题
以下是使用OpenAI的GPT-3.5-turbo-instruct LLM测试RAG的示例问题。指定这些示例的目的,是为了确保它们的答案与2022年、2023年和2024年发生的事件有关。
sample_questions = [
"Who won the 2022 soccer world cup?",
"When did Sweden join NATO?",
"Who joined NATO in 2023?",
"Who joined NATO in 2024?",
"Which is the 31st member of NATO?",
"Which is the 32nd member of NATO?",
"Who won the Cricket World Cup in 2023?",
"Who defeated India in Cricket World Cup final in 2023?",
"Name the former prime minister of Japan that was assassinated in 2022?",
"When did Chandrayaan-3 land near the south pole of the Moon?",
"Where did Chandrayaan-3 land on the Moon?",
"Who acquired Twitter in 2022?",
"Who owns Twitter?",
"Who acquired Activision Blizzard in 2023?"
]第8步:把所有内容组合起来
将所有组件整合在一起的完整Jupyter笔记本可以在GitHub(https://github.com/kbmurali/som-driven-qa-rag/blob/main/OpenAI_Based_SOM_GPT2_Bot.ipynb)找到。以下代码片段显示了主要的基于OpenAI的QA聊天机器人的启动过程。请注意,OpenAI的文本嵌入算法“text-embedding-ada-002”用于向量编码。同样,聊天机器人使用OpenAI的标记器“cl100k_base”来计数标记,以限制上下文文本,从而通过利用TikToken Python库的内置功能来增强问题提示。
openai_vector_encoder_id = "text-embedding-ada-002"
openai_encoded_vector_dimensions = 1536
openai_tokenizer_name = "cl100k_base"
openai_model_name = "gpt-3.5-turbo-instruct"
vector_encoder = OpenAIEmbeddingsVectorEncoder( openai_encoded_vector_dimensions, openai_vector_encoder_id, openai_key )
event_years_to_fetch = [ 2022, 2023, 2024 ]
data_source = WikiEventsDataSource( event_years_to_fetch )
...
som_driven_rag_util = SOM_Based_RAG_Util(
vector_encoder = vector_encoder,
som_lattice_height = 20,
som_lattice_width = 30,
learning_rate = 0.3,
topk_bmu_for_indexing = 10,
device = device
)
...
openai_chatbot = OpenAIQuestionAnswerChatBot(
vector_db_util = som_driven_rag_util,
openai_tokenizer_name = openai_tokenizer_name,
openai_model_name = openai_model_name,
openai_key = openai_key,
question_input_max_token_count = 100,
context_trim_percent = 0.1,
device = device
)以下序列图有助于可视化初始化和实际问答阶段的所有组件交互。
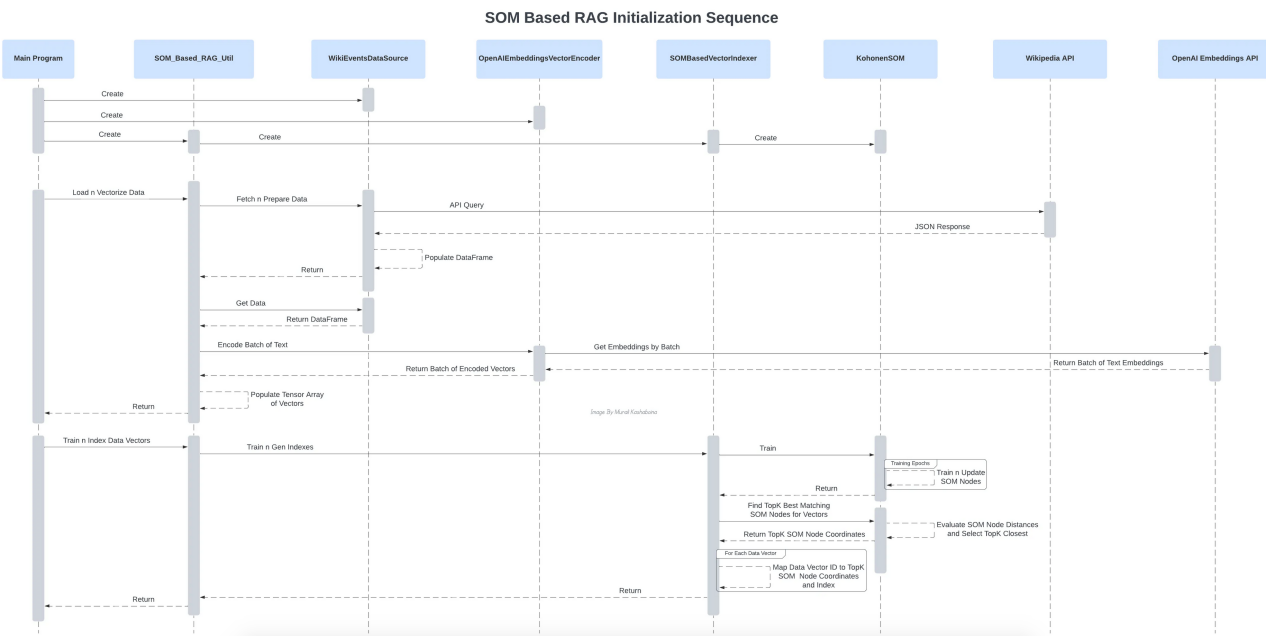
初始化过程中各种组件的相互作用(作者本人图片)
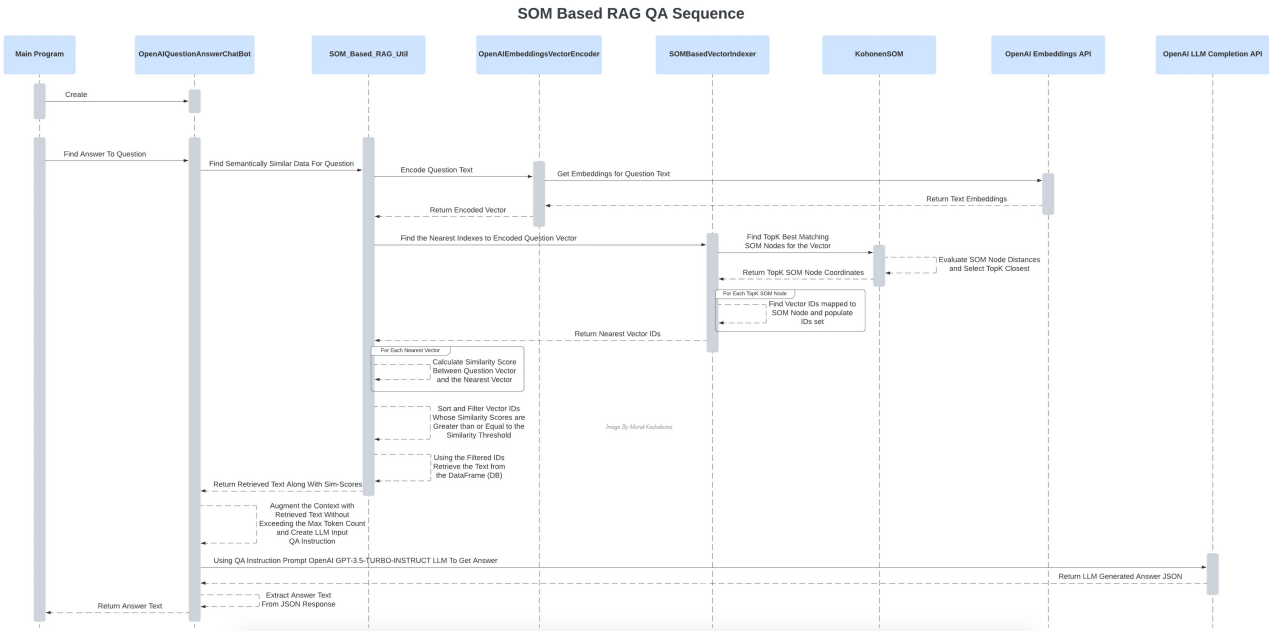
问答过程中各种组件的相互作用(作者本人图片)
调查结果
下图展示了OpenAI的GPT-3.5-turbo-instruct LLM中的问题/答案,分别相应于包括上下文增强和不包括上下文增强的情形。

OpenAI的GPT-3.5-turbo-instruct LLM在有和没有上下文增强的情况下给出的答案(作者本人图片)
可以理解的是,LLM发现回答有关2021年9月截止日期后发生的事件的问题很有挑战性。在大多数情况下,它清楚地回答说,这些问题来自与其训练截止日期相关的未来时间。相反,当提示问题的上下文被从维基百科检索到的2022年、2023年和2024年的相关信息所扩充时,相同的LLM准确地完美地回答了所有问题。这里真正值得称赞的是SOM,它构成了RAG语义搜索的基础,以检索并用相关信息增强提示问题的上下文。
下一步行动建议
虽然上述例子是评估自组织图是否适合LLM进行文本检索增强生成的概念验证,但与使用更大外部数据集的其他算法相比,建议使用更全面的基准测试来评估其性能,其中性能是根据LLM输出的质量来衡量的(有点像困惑+准确性)。此外,由于当前示例支持可插入框架,因此建议使用其他开源和免费的QA LLM来进行此类基准测试,以最大限度地减少LLM的使用费用。
为了帮助在本地环境中运行该示例,我示例中包含了一个“requirements.txt”文件,其中包含我在环境中用于运行和测试上述示例的各种版本的Python库。此文件可在GitHub(https://github.com/kbmurali/som-driven-qa-rag/blob/main/requirements.txt)找到。
参考文献
- 《SOM教程1》,简明英语神经网络教程:www.ai-junkie.com
- 《用Python代码理解自组织映射神经网络》,通过竞争、合作和适应实现大脑启发的无监督机器学习:https://towardsdatascience.com/understanding-self-organising-map-neural-network-with-python-code-7a77f501e985?source=post_page-----5d739ce21e9c--------------------------------
- 《知识密集型NLP任务的检索增强生成》,大型预先训练的语言模型已被证明可以将事实知识存储在其参数中与具体实现:https://arxiv.org/abs/2005.11401?source=post_page-----5d739ce21e9c--------------------------------
- 《什么是检索增强生成(RAG)?》,检索增强生成(RAG)是一种提高生成人工智能模型准确性和可靠性的技术:https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/?source=post_page-----5d739ce21e9c--------------------------------
- https://www.sciencedirect.com/topics/engineering/self-organizing-map
- https://platform.openai.com/docs/models/gpt-3-5-turbo
- https://platform.openai.com/docs/guides/text-generation/chat-completions-api
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Using Self-Organizing Map To Bolster Retrieval-Augmented Generation In Large Language Models,作者:Murali Kashaboina
链接:https://towardsdatascience.com/using-self-organizing-map-to-bolster-retrieval-augmented-generation-in-large-language-models-5d739ce21e9c。



























