作者 | 吴守阳
审校 | 重楼
简介

RedisShake 是一个用于处理和迁移 Redis 数据的工具,它提供以下特性:
- Redis 兼容性:RedisShake 兼容从 2.8 到 7.2 的 Redis 版本,并支持各种部署方式,包括单机、主从、哨兵和集群。
- 云服务兼容性:RedisShake 与主流云服务提供商提供的流行 Redis-like 数据库无缝工作,包括但不限于:
阿里云-云数据库 Redis 版
阿里云-云原生内存数据库Tair
AWS - ElastiCache
AWS - MemoryDB
- Module 兼容:RedisShake 与 TairString,TairZSet 和 TairHash 模块兼容。
- 多种导出模式:RedisShake 支持 PSync,RDB 和 Scan 导出模式。
- 数据处理:RedisShake 通过自定义脚本实现数据过滤和转换。
迁移模式介绍
目前, RedisShake 有三种迁移模式:PSync、RDB 和 SCAN,分别对应 sync_reader、rdb_reader 和 scan_reader。
- 对于从备份中恢复数据的场景,可以使用 rdb_reader。
- 对于数据迁移场景,优先选择 sync_reader。一些云厂商没有提供 PSync 协议支持,可以选择scan_reader。
- 对于长期的数据同步场景,RedisShake 目前没有能力承接,因为 PSync 协议并不可靠,当复制连接断开时,RedisShake 将无法重新连接至源端数据库。如果对于可用性要求不高,可以使用 scan_reader。如果写入量不大,且不存在大 key,也可以考虑 scan_reader。不同模式各有优缺点,需要查看各 Reader 章节了解更多信息。
Redis Cluster 架构
当源端 Redis 以 cluster 架构部署时,可以使用 sync_reader 或者 scan_reader。两者配置项中均有开关支持开启 cluster 模式,会通过 cluster nodes 命令自动获取集群中的所有节点,并建立连接。
Redis Sentinel 架构
当源端 Redis 以 sentinel 架构部署且 RedisShake 使用 sync_reader 连接主库时,会被主库当做 slave,从而有可能被 sentinel 选举为新的 master。
为了避免这种情况,应选择备库作为源端。
云 Redis 服务
主流云厂商都提供了 Redis 服务,不过有几个原因导致在这些服务上使用 RedisShake 较为复杂:
- 引擎限制。存在一些自研的 Redis-like 数据库没有兼容 PSync 协议。
- 架构限制。较多云厂商支持代理模式,即在用户与 Redis 服务之间增加 Proxy 组件。因为 Proxy 组件的存在,所以 PSync 协议无法支持。
- 安全限制。在原生 Redis 中 PSync 协议基本会触发 fork(2),会导致内存膨胀与用户请求延迟增加,较坏情况下甚至会发生 out of memory。尽管这些都有方案缓解,但并不是所有云厂商都有这方面的投入。
- 商业策略。较多用户使用 RedisShake 是为了下云或者换云,所以部分云厂商并不希望用户使用 RedisShake,从而屏蔽了 PSync 协议。
下文会结合实践经验,介绍一些特殊场景下的 RedisShake 使用方案。
阿里云「云数据库 Redis」与「云原生内存数据库Tair」
「云数据库 Redis」与「云原生内存数据库Tair」都支持 PSync 协议,推荐使用 sync_reader。用户需要创建一个具有复制权限的账号(可以执行 PSync 命令),RedisShake 使用该账号进行数据同步,具体创建步骤见 创建与管理账号。
例外情况:
- 2.8 版本的 Redis 实例不支持创建复制权限的账号,需要 升级大版本。
- 集群架构的 Reids 与 Tair 实例在 代理模式 下不支持 PSync 协议。
- 读写分离架构不支持 PSync 协议。
在不支持 PSync 协议的场景下,可以使用 scan_reader。需要注意的是,scan_reader 会对源库造成较大的压力。
AWS ElastiCache and MemoryDB
优选 sync_reader, AWS ElastiCache and MemoryDB 默认情况下没有开启 PSync 协议,但是可以通过提交工单的方式请求开启 PSync 协议。AWS 会在工单中给出一份重命名的 PSync 命令,比如 xhma21yfkssync 和 nmfu2bl5osync。此命令效果等同于 psync 命令,只是名字不一样。 用户修改 RedisShake 配置文件中的 aws_psync 配置项即可。对于单实例只写一对 ip:port@cmd 即可,对于集群实例,需要写上所有的 ip:port@cmd,以逗号分隔。
不方便提交工单时,可以使用 scan_reader。需要注意的是,scan_reader 会对源库造成较大的压力。
安装
Wget https://github.com/tair-opensource/RedisShake/archive/refs/tags/v4.0.5.tar.gz
yum install go
tar -xvf redis-shake-linux-amd64.tar.gz
cd redis-shark
[root@ redis-shark]# ls
1shake_online.toml 2shake_rdb.toml data redis-shake shake.toml.bak迁移配置
在线迁移SYNC模式
[root@idc-zabbix12 redis-shark]# vim 1shake_online.toml
function = ""
[sync_reader]
version = "7.0" ###source集群版本
cluster = true ###集群
address = "10.0.0.8:9101" ###source只需填写一个主节点地址即可
username = ""
password = "Bj***w"
tls = false
sync_rdb = true
sync_aof = true
prefer_replica = true
# [scan_reader]
# cluster = false # set to true if source is a redis cluster
# address = "127.0.0.1:6379" # when cluster is true, set address to one of the cluster node
# username = "" # keep empty if not using ACL
# password = "" # keep empty if no authentication is required
# ksn = false # set to true to enabled Redis keyspace notifications (KSN) subscription
# tls = false
# dbs = [] # set you want to scan dbs such as [1,5,7], if you don't want to scan all
# prefer_replica = true # set to true if you want to sync from replica node
##文件依次执行
[rdb_reader]
#filepath = "/opt/bakredis-shake.bak/local_dump.0"
#filepath = "/opt/bakredis-shake.bak/local_dump.1"
#filepath = "/opt/bakredis-shake.bak/local_dump.2"
# [aof_reader]
# filepath = "/tmp/.aof"
# timestamp = 0 # subsecond
[redis_writer]
version = "7.0" ###目标集群版本
cluster = true ###集群
address = "10.28.29.51:9101" ###target集群只需填写一个主节点地址即可
username = ""
password = "B***Zw"
tls = false
off_reply = false
[advanced]
dir = "data" ###生成的数据目录
ncpu = 4 # runtime.GOMAXPROCS, 0 means use runtime.NumCPU() cpu cores
pprof_port = 0 # pprof port, 0 means disable
status_port = 0 # status port, 0 means disable
# log
log_file = "shake.log" ###日志文件
log_level = "info" # debug, info or warn
log_interval = 5 # in seconds
rdb_restore_command_behavior = "panic" # panic, rewrite or skip
pipeline_count_limit = 1024
target_redis_client_max_querybuf_len = 1024_000_000
target_redis_proto_max_bulk_len = 512_000_000
aws_psync = "" # example: aws_psync = "10.0.0.1:6379@nmfu2sl5osync,10.0.0.1:6379@xhma21xfkssync"
empty_db_before_sync = false
[module]
target_mbbloom_version = 20603执行:
[root@idc-zabbix12 redis-shark]# ./redis-shake 1shake_online.tomlRDB文件导入模式
[root@idc-zabbix12 redis-shark]# cat 2shake_rdb.toml
function = ""
#[sync_reader]
#version = "7.0"
#cluster = true
#address = "10.28.29.8:9101"
#username = ""
#password = "Bjmr0cakP7Zw"
#tls = false
#sync_rdb = true
#sync_aof = true
#prefer_replica = true
# [scan_reader]
# cluster = false # set to true if source is a redis cluster
# address = "127.0.0.1:6379" # when cluster is true, set address to one of the cluster node
# username = "" # keep empty if not using ACL
# password = "" # keep empty if no authentication is required
# ksn = false # set to true to enabled Redis keyspace notifications (KSN) subscription
# tls = false
# dbs = [] # set you want to scan dbs such as [1,5,7], if you don't want to scan all
# prefer_replica = true # set to true if you want to sync from replica node
##文件依次执行 0、1、2
[rdb_reader]
filepath = "/opt/bakredis-shake.bak/local_dump.0" ###rdb文件,source集群是3分片集群
#filepath = "/opt/bakredis-shake.bak/local_dump.1"
#filepath = "/opt/bakredis-shake.bak/local_dump.2"
# [aof_reader]
# filepath = "/tmp/.aof"
# timestamp = 0 # subsecond
[redis_writer]
version = "7.0"
cluster = true
address = "10.0.0.51:9101" ####目标导入集群
username = ""
password = "Bj***Zw"
tls = false
off_reply = false
[advanced]
dir = "data"
ncpu = 4 # runtime.GOMAXPROCS, 0 means use runtime.NumCPU() cpu cores
pprof_port = 0 # pprof port, 0 means disable
status_port = 0 # status port, 0 means disable
# log
log_file = "shake.log"
log_level = "info" # debug, info or warn
log_interval = 5 # in seconds
rdb_restore_command_behavior = "panic" # panic, rewrite or skip
pipeline_count_limit = 1024
target_redis_client_max_querybuf_len = 1024_000_000
target_redis_proto_max_bulk_len = 512_000_000
aws_psync = "" # example: aws_psync = "10.0.0.1:6379@nmfu2sl5osync,10.0.0.1:6379@xhma21xfkssync"
empty_db_before_sync = false
[module]
target_mbbloom_version = 20603执行:
恢复/opt/bakredis-shake.bak/local_dump.0文件
[root@idc-zabbix12 redis-shark]# ./redis-shake 2shake_rdb.toml恢复/opt/bakredis-shake.bak/local_dump.1文件
[root@idc-zabbix12 redis-shark]# ./redis-shake 2shake_rdb.toml恢复/opt/bakredis-shake.bak/local_dump.2文件
[root@idc-zabbix12 redis-shark]# ./redis-shake 2shake_rdb.tomlscan_reader
scan_reader 通过 SCAN 命令遍历源端数据库中的所有 Key,并使用 DUMP 与 RESTORE 命令来读取与写入 Key 的内容。
注意:
Redis 的 SCAN 命令只保证 SCAN 的开始与结束之前均存在的 Key 一定会被返回,但是新写入的 Key 有可能会被遗漏,期间删除的 Key 也可能已经被写入目的端。这可以通过 ksn 配置解决。
SCAN 命令与 DUMP 命令会占用源端数据库较多的 CPU 资源。
[scan_reader]
cluster = false # set to true if source is a redis cluster
address = "127.0.0.1:6379" # when cluster is true, set address to one of the cluster node
username = "" # keep empty if not using ACL
password = "" # keep empty if no authentication is required
tls = false
ksn = false # set to true to enabled Redis keyspace notifications (KSN) subscription
dbs = [] # set you want to scan dbs, if you don't want to scan all其中:
cluster:源端是否为集群。
address:源端地址,当源端为集群时,address 为集群中的任意一个节点即可。
鉴权:
当源端使用 ACL 账号时,配置 username 和 password。
当源端使用传统账号时,仅配置 password。
当源端无鉴权时,不配置 username 和 password。
tls:源端是否开启 TLS/SSL,不需要配置证书。因为 RedisShake 没有校验服务器证书。
ksn:开启 ksn 参数后, RedisShake 会在 SCAN 之前使用 Redis keyspace notifications 能力来订阅 Key 的变化。当 Key 发生变化时,RedisShake 会使用 DUMP 与 RESTORE 命令来从源端读取 Key 的内容,并写入目标端。
dbs:源端为非集群模式时,支持指定DB库。
WARNING
Redis keyspace notifications 不会感知到 FLUSHALL 与 FLUSHDB 命令,因此在使用 ksn 参数时,需要确保源端数据库不会执行这两个命令。
function模式
RedisShake 通过提供 function 功能,实现了的 ETL(提取-转换-加载) 中的 transform 能力。通过利用 function 可以实现类似功能:
- 更改数据所属的 db,比如将源端的 db 0 写入到目的端的 db 1。
- 对数据进行筛选,例如,只将 key 以 user: 开头的源数据写入到目标端。
- 改变 Key 的前缀,例如,将源端的 key prefix_old_key 写入到目标端的 key prefix_new_key。
...
要使用 function 功能,只需编写一份 lua 脚本。RedisShake 在从源端获取数据后,会将数据转换为 Redis 命令。然后,它会处理这些命令,从中解析出 KEYS、ARGV、SLOTS、GROUP 等信息,并将这些信息传递给 lua 脚本。lua 脚本会处理这些数据,并返回处理后的命令。最后,RedisShake 会将处理后的数据写入到目标端。
以下是一个具体的例子:
function = """
shake.log(DB)
if DB == 0
then
return
end
shake.call(DB, ARGV)
"""
[sync_reader]
address = "127.0.0.1:6379"
[redis_writer]
address = "127.0.0.1:6380"DB 是 RedisShake 提供的信息,表示当前数据所属的 db。shake.log 用于打印日志,shake.call 用于调用 Redis 命令。上述脚本的目的是丢弃源端 db 0 的数据,将其他 db 的数据写入到目标端。
除了 DB,还有其他信息如 KEYS、ARGV、SLOTS、GROUP 等,可供调用的函数有 shake.log 和 shake.call,具体请参考 function API。
function API
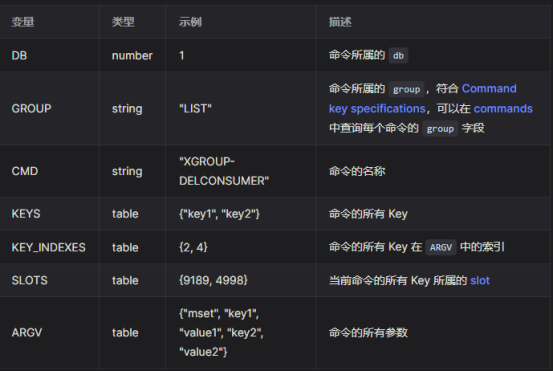
变量
因为有些命令中含有多个 key,比如 mset 等命令。所以,KEYS、KEY_INDEXES、SLOTS 这三个变量都是数组类型。如果确认命令只有一个 key,可以直接使用 KEYS[1]、KEY_INDEXES[1]、SLOTS[1]。
函数
- shake.call(DB, ARGV):返回一个 Redis 命令,RedisShake 会将该命令写入目标端。
- shake.log(msg):打印日志。
最佳实践
过滤 Key
local prefix = "user:"
local prefix_len = #prefix
if string.sub(KEYS[1], 1, prefix_len) ~= prefix then
return
end
shake.call(DB, ARGV)效果是只将 key 以 user: 开头的源数据写入到目标端。没有考虑 mset 等多 key 命令的情况。
过滤 DB
shake.log(DB)
if DB == 0
then
return
end
shake.call(DB, ARGV)效果是丢弃源端 db 0 的数据,将其他 db 的数据写入到目标端。
过滤某类数据结构
可以通过 GROUP 变量来判断数据结构类型,支持的数据结构类型有:STRING、LIST、SET、ZSET、HASH、SCRIPTING 等。
过滤 Hash 类型数据
if GROUP == "HASH" then
return
end
shake.call(DB, ARGV)效果是丢弃源端的 hash 类型数据,将其他数据写入到目标端。
过滤 LUA 脚本
if GROUP == "SCRIPTING" then
return
end
shake.call(DB, ARGV)效果是丢弃源端的 lua 脚本,将其他数据写入到目标端。常见于主从同步至集群时,存在集群不支持的 LUA 脚本。
修改 Key 的前缀
local prefix_old = "prefix_old_"
local prefix_new = "prefix_new_"
shake.log("old=" .. table.concat(ARGV, " "))
for i, index in ipairs(KEY_INDEXES) do
local key = ARGV[index]
if string.sub(key, 1, #prefix_old) == prefix_old then
ARGV[index] = prefix_new .. string.sub(key, #prefix_old + 1)
end
end
shake.log("new=" .. table.concat(ARGV, " "))
shake.call(DB, ARGV)效果是将源端的 key prefix_old_key 写入到目标端的 key prefix_new_key。
交换 DB
local db1 = 1
local db2 = 2
if DB == db1 then
DB = db2
elseif DB == db2 then
DB = db1
end
shake.call(DB, ARGV)效果是将源端的 db 1 写入到目标端的 db 2,将源端的 db 2 写入到目标端的 db 1, 其他 db 不变。
注意事项
- 不要在同一个目录运行两个 RedisShake 进程,因为运行时产生的临时文件可能会被覆盖,导致异常行为。
- 不要降低 Redis 版本,比如从 6.0 降到 5.0,因为 RedisShake 每个大版本都会引入一些新的命令和新的编码方式,如果降低版本,可能会导致不兼容。
作者简介
吴守阳,51CTO社区编辑,拥有8年DBA工作经验,熟练管理MySQL、Redis、MongoDB等开源数据库。精通性能优化、备份恢复和高可用性架构设计。善于故障排除和自动化运维,保障系统稳定可靠。具备良好的团队合作和沟通能力,致力于为企业提供高效可靠的数据库解决方案。