Redis 脑裂问题是指,在 Redis 哨兵模式或集群模式中,由于网络原因,导致主节点(Master)与哨兵(Sentinel)和从节点(Slave)的通讯中断,此时哨兵就会误以为主节点已宕机,就会在从节点中选举出一个新的主节点,此时 Redis 的集群中就出现了两个主节点的问题,就是 Redis 脑裂问题。
脑裂问题影响
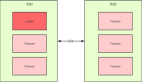
Redis 脑裂问题会导致数据丢失,为什么呢?来看脑裂问题产生的过程:

而最后一步,当旧的 Master 变为 Slave 之后,它的执行流程如下:
- Slave(旧 Master)会向 Master(新)申请全量数据。
- Master 会通过 bgsave 的方式生成当前 RDB 快照,并将 RDB 发送给 Slave。
- Slave 拿到 RDB 之后,先进行 flush 清空当前数据(此时第四步旧客户端给他的发送的数据就丢失了)。
- 之后再加载 RDB 数据,初始化自己当前的数据。
从以上过程中可以看出,在执行到第三步的时候,原客户端在旧 Master 写入的数据就丢失了,这就是数据丢失的问题。
如何解决脑裂问题?
脑裂问题只需要在旧 Master 恢复网络之后,切换身份为 Slave 期间,不接收客户端的数据写入即可,那怎么解决这个问题呢?
Redis 为我们提供了以下两个配置,通过以下两个配置可以尽可能的避免数据丢失的问题:
- min-slaves-to-write:与主节点通信的从节点数量必须大于等于该值主节点,否则主节点拒绝写入。
- min-slaves-max-lag:主节点与从节点通信的 ACK 消息延迟必须小于该值,否则主节点拒绝写入。
这两个配置项必须同时满足,不然主节点拒绝写入。
在假故障期间满足 min-slaves-to-write 和 min-slaves-max-lag 的要求,那么主节点就会被禁止写入,脑裂造成的数据丢失情况自然也就解决了。
课后思考
设置了参数之后,Redis 脑裂问题能完全被解决吗?为什么?Zookeeper 有脑裂问题吗?它是如何解决脑裂问题的?