多任务机器人学习在应对多样化和复杂情景方面具有重要意义。然而,当前的方法受到性能问题和收集训练数据集的困难的限制。
这篇论文提出了GeRM(通用机器人模型),研究人员利用离线强化学习来优化数据利用策略,从演示和次优数据中学习,从而超越了人类演示的局限性。

作者:宋文轩,赵晗,丁鹏翔,崔灿,吕尚可,范亚凝,王东林
单位:西湖大学、浙江大学
论文地址:https://arxiv.org/abs/2403.13358
项目地址:https://songwxuan.github.io/GeRM/
之后采用基于Transformer的视觉-语言-动作模型来处理多模态输入并输出动作。
通过引入专家混合结构,GeRM实现了更快的推理速度和更高的整体模型容量,从而解决了强化学习参数量受限的问题,提高了多任务学习中的模型性能,同时控制了计算成本。
通过一系列实验证明,GeRM在所有任务中均优于其他方法,同时验证了其在训练和推理过程中的效率。
此外,研究人员还提供了QUARD-Auto数据集以支持训练,该数据集的构建遵循文中提出的数据自动化收集的新范式,该方法可以降低收集机器人数据的成本,推动多任务学习社区的进步。
主要贡献:
1. 首次提出了用于四足强化学习的混合专家模型,其在混合质量的数据上进行训练,从而具备习得最优策略的潜力。
2. 与现有方法相比,GeRM在只激活自身1/2参数的情况下展现出更高的成功率,激活了涌现能力,同时在训练过程中展现了更优的数据利用策略。
3.提出了一个全自动机器人数据集收集的范式,并收集了一个大规模开源数据集。
方法
GeRM网络结构如图1所示,包含示范数据和失败数据的视觉-语言输入,分别经过编码器和tokenizer后输入到8层混合专家结构的decoder中,并生成动作token,最终转化为离散的机器人动作数据并通过底层策略部署到机器人上,此外我们用强化学习的方式进行训练。
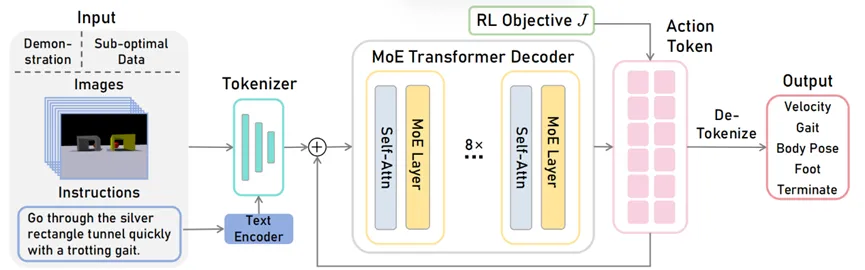
图1 GeRM网络结构图
GeRM Decoder是一个包含 Transformer Decoder架构模型,其中前馈网络(FFN)从一组 8 个不同的专家网络中选择。
在每一层,对于每一个标记,门控网络选择两个专家来处理token,并将它们的输出加权组合。
不同的专家擅长不同的任务/不同的动作维度,以解决不同场景中的问题,从而学习跨多个任务的通用模型。该架构扩大了网络参数量,同时保持计算成本基本不变。

图2 Decoder结构图
我们提出了一个自动的范式来收集机器人多模态数据。通过这种方式,我们构建了一个大规模的机器人数据集QUARD-Auto,其中包含演示和次优数据的组合。它包括5个任务和99个子任务,总共有257k条轨迹。我们将进行开源以促进机器人社区发展。

表1 数据集介绍
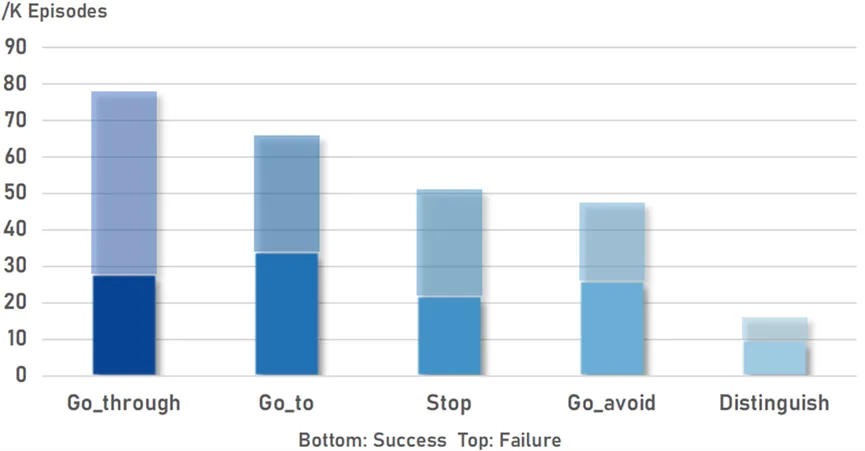
图3 数据量统计
实验
我们进行了一系列全面而可靠的实验,涵盖了所有 99 个子任务,每个子任务进行了 400 条轨迹的精心测试。
如表1所示,GeRM在所有任务中具有最高的成功率。与 RT-1 和其他GeRM 的变体相比,它有效地从混合质量的数据中学习,优于其他方法,并在多任务中展现出优越的能力。与此同时,MoE 模块通过在推理时激活部分参数来平衡计算成本和性能。
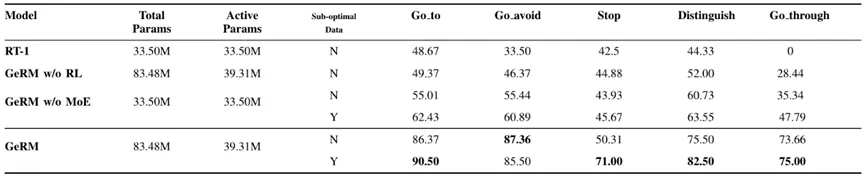
表2 多任务对比实验
GeRM表现出令人称赞的训练效率。与其他方法相比,GeRM 仅需极少的batch就获得了极低的Loss和较高的成功率,凸显了GeRM优化数据利用策略的能力。
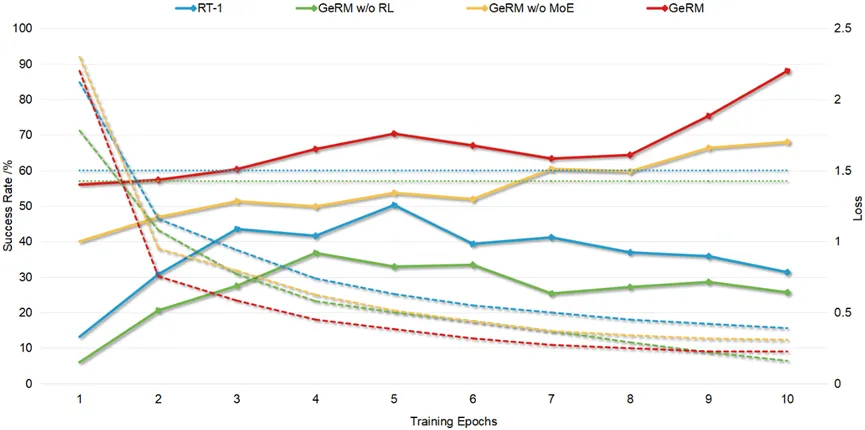
图4 成功率/Loss变化曲线
GeRM 在动态自适应路径规划方面展现出了涌现能力。如视频所示,四足机器人在初始位置视野受限,难以确定移动方向。为了避开障碍物,它随机选择向左转。
随后,在遇到错误的视觉输入后,机器人执行了大幅度的重新定向,以与原始视野之外的正确目标对齐。然后,它继续向目的地驶去,最终完成任务。
值得注意的是,这样的轨迹不属于我们的训练数据集分布之内。这表明 GeRM 在场景背景下的动态自适应路径规划方面具有涌现能力,即它能够根据视觉感知进行决策、规划未来路径,并根据需要改变下一步行动。

图5 涌现能力