在数据分析和建模过程中,变量的选择和转换对于模型的性能至关重要。在这方面,证据权重(Weight of evidence,WoE)和信息价值(Information value,IV)是两种简单而强大的技术,它们在许多领域都有着广泛的应用。在信用风险领域、客户忠诚度分析等得到广泛使用。
信息价值(IV)通常用于评估分类模型中各个特征的预测能力。它是一种用来衡量预测模型的变量(通常是分类模型)对目标变量的影响程度的指标。信息价值越高,表示该变量对于预测目标变量越重要。
证据权重(WoE)通常用于衡量类别变量与目标变量之间的关联性,特别适用于逻辑回归等模型。它通过比较不同类别中目标事件的发生概率来评估每个类别对于预测目标变量的影响程度。WOE值的正负代表了该类别对于目标变量的“好坏”程度,越大的绝对值表示影响越显著。
证据权重WoE
WoE是一种衡量特征X(自变量)对目标y(因变量)的预测能力的方法。其理论最初用于风险评分分析,并通过以下公式计算:
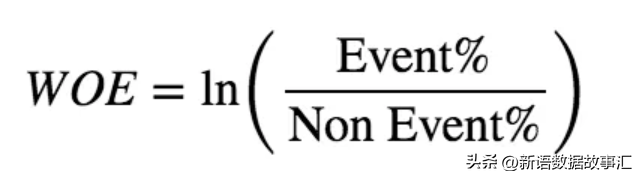
其中,Non Event%是特定群体中事件没有发生的分布(占比),Event%是特定群体中事件发生的分布(占比)。例如:信用风险分析中,Event%是指特定群体中发生信用违约的占比,Non Event% 是特定群体中正常的占比。或者在商品分析中,Event% 是特定群体中坏的商品分布/占比,Non Event% 是指特定群体中好的商品分布/占比。
证据权重(WoE)计算步骤:
- 对于连续变量,将数据分为 10 个部分(或更少,具体取决于分布)。
- 计算每组中事件和非事件的数量(bin)
- 计算每组中事件的百分比和非事件的百分比。
- 通过非事件百分比和事件百分比除以自然对数来计算 WOE
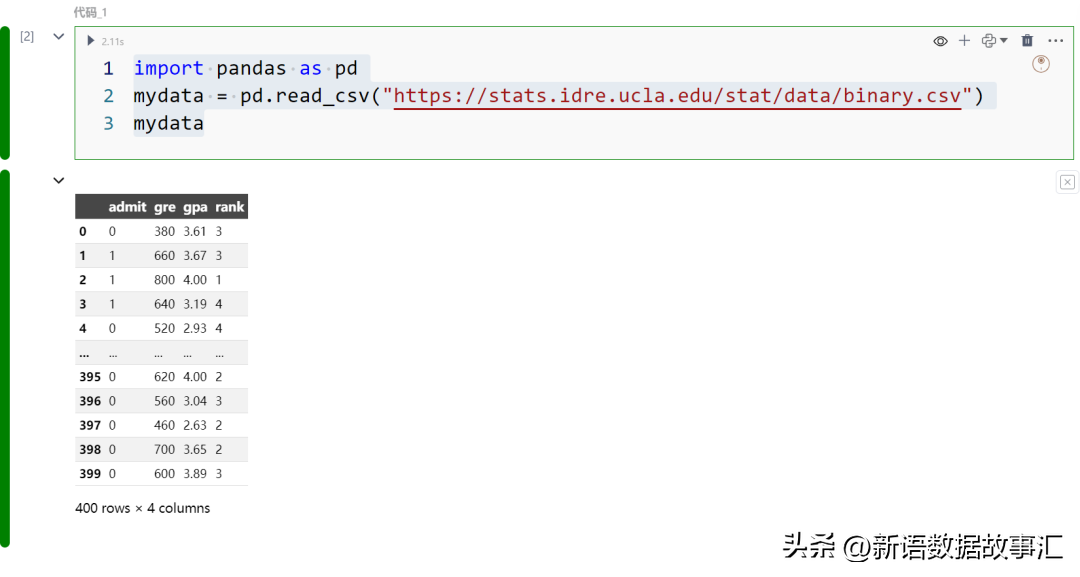
接下来我们以UCLA统计网站中的研究生入学申请的数据集为例进行计算WoE,字段含义如下:
- admit: 二元变量,表示学生是否被录取,其中1代表被录取,0代表未被录取。
- gre: 数值变量,表示学生的GRE(研究生入学考试)成绩。
- gpa: 数值变量,表示学生的GPA(平均学分绩点)成绩。
- rank: 数值变量,表示申请学生所在的本科院校排名,可能的取值范围为1至4,其中1代表最高排名,4代表最低排名。
下面是计算WoE 和IV 的过程函数:
计算上面的数据集的WoE ,目标变量为admit:
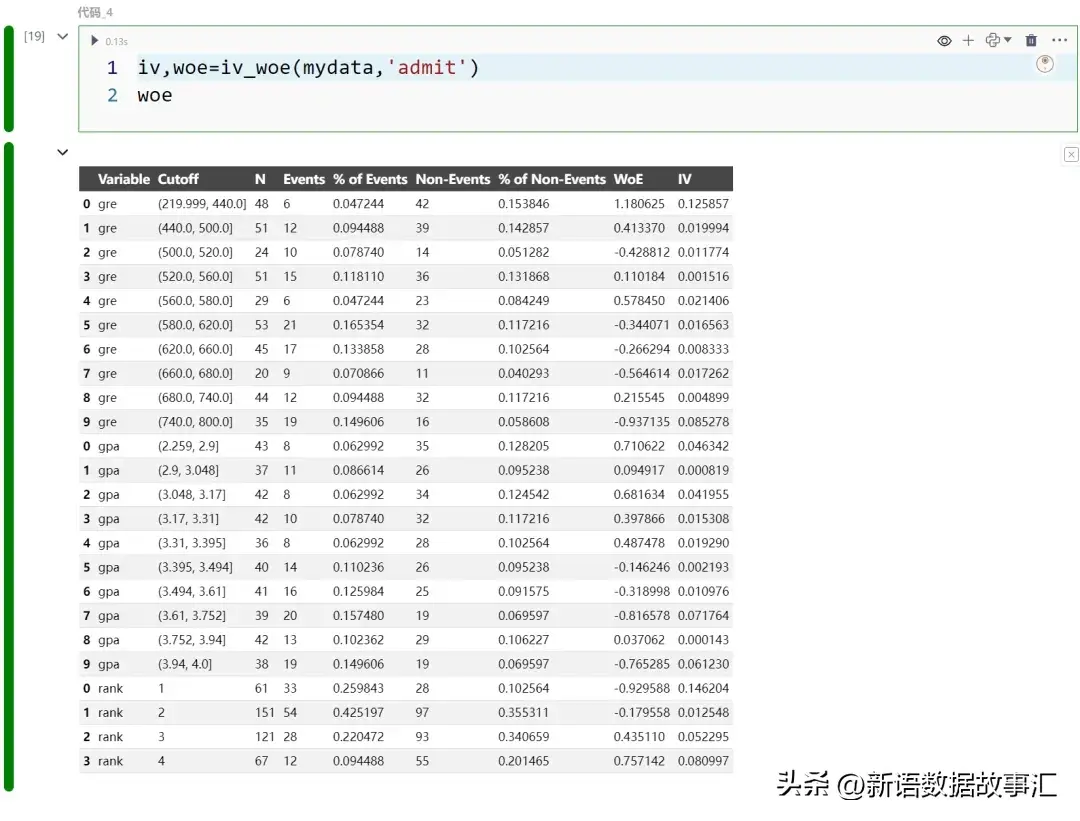
正 WOE 意味着被拒绝录取的可能性更高(非事件,拒绝录取),负 WOE 则相反。
权重证据 WoE的好处
以下是一些权重证据的好处以及它如何可以用来改善您的预测模型。
- 它可以处理异常值。假设您有一个连续变量,比如年薪,而极端值超过了5亿美元。这些值将被分组到一个类别中(比如说25-50亿美元)。随后,我们将使用每个类别的WOE分数,而不是使用原始值。
- 它可以处理缺失值,因为缺失值可以单独分组。
- 由于WOE转换处理分类变量,因此无需虚拟变量。
- WOE转换可以帮助您建立严格的对数几率的线性关系。否则,使用其他转换方法(如对数、平方根等)很难实现线性关系。简而言之,如果不使用WOE转换,您可能需要尝试多种转换方法来实现这一点。
信息价值 IV
信息价值(IV)是选择预测模型中重要变量的最有用技术之一。它有助于根据其重要性对变量进行排序。IV是使用以下公式计算的:
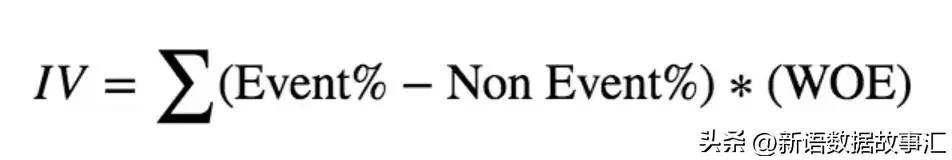
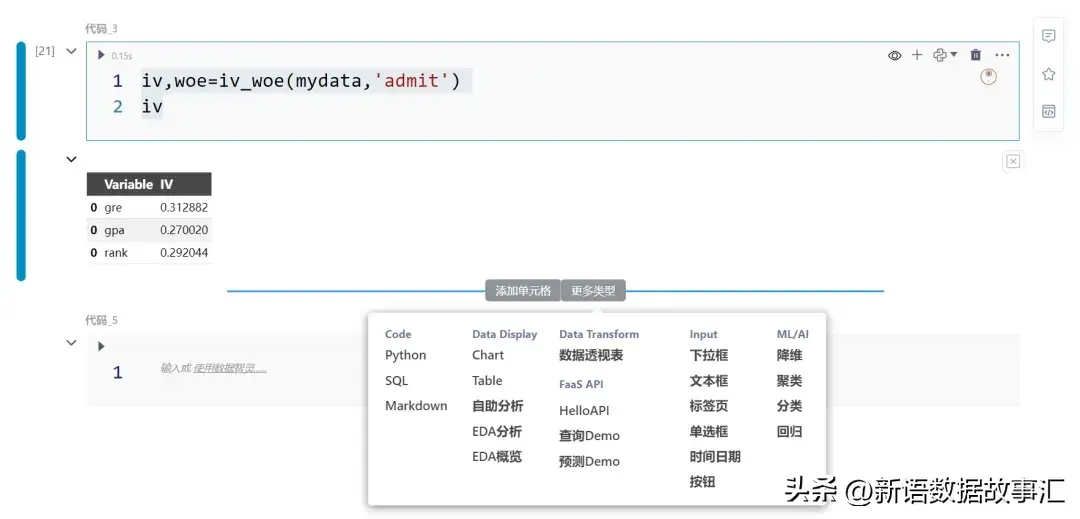
以上面的计算函数和数据集计算各个特征变量的IV 如下:
信息价值IV 规则
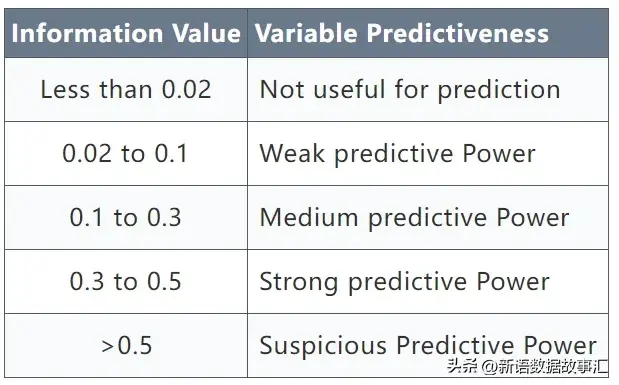
根据Siddiqi(2006)的说法,在信用评分中,IV统计量的值可以按照以下方式解释。如果IV统计量为:
- 小于0.02,则预测变量对建模(区分好坏)没有用处
- 0.02到0.1,则预测变量与好坏比的关系较弱
- 0.1到0.3,则预测变量与好坏比的关系中等强度
- 0.3到0.5,则预测变量与好坏比的关系较强
- 大于0.5,则关系可疑(请检查一次)
WOE和IV是数据分析和建模中的重要工具,它们能够帮助我们发现特征与目标变量之间的关系,并指导我们做出更好的决策。通过深入理解这些技术的原理和应用,我们可以更好地优化模型,提高预测准确性,从而实现更好的业务结果。