












本文经自动驾驶之心公众号授权转载,转载请联系出处。
写在前面&笔者个人理解
这篇论文介绍了一种名为LeGo-Drive的基于视觉语言模型的闭环端到端自动驾驶方法。该方法通过预测目标位置和可微分优化器规划轨迹,实现了从导航指令到目标位置的端到端闭环规划。通过联合优化目标位置和轨迹,该方法提高了目标位置预测的准确性,并生成了平滑、无碰撞的轨迹。在多个仿真环境中进行的实验表明,该方法在自动驾驶指标上取得了显著改进,目标到达成功率达到81%。该方法具有很好的可解释性,可用于实际自动驾驶车辆和智能交通系统中。
 图1:LeGo-Drive导航到基于语言的目标,该目标与轨迹参数共同优化。“将车停在左前方公交车站附近”等命令的预测目标可能会落在不理想的位置(右上:绿色),这可能会导致容易发生碰撞的轨迹。由于轨迹是唯一直接与环境“交互”的组件,因此我们建议让感知感知了解轨迹参数,从而将目标位置改善为可导航位置(右下角:红色)
图1:LeGo-Drive导航到基于语言的目标,该目标与轨迹参数共同优化。“将车停在左前方公交车站附近”等命令的预测目标可能会落在不理想的位置(右上:绿色),这可能会导致容易发生碰撞的轨迹。由于轨迹是唯一直接与环境“交互”的组件,因此我们建议让感知感知了解轨迹参数,从而将目标位置改善为可导航位置(右下角:红色)
开源地址:https://reachpranjal.github.io/lego-drive
相关工作回顾
视觉基础
视觉基础的目标是将自然语言查询与视觉场景中最相关的视觉元素或目标关联起来。早期的研究方法是将视觉基础任务视为参考表达理解(Referring Expression Comprehension, REC),这涉及到生成区域提案,然后利用语言表达来选择最佳匹配的区域。相对地,一种称为Referring Image Segmentation (RIS)的一阶段方法,则将语言和视觉特征集成在网络中,并直接预测目标框。参考文献使用了RIS方法,基于语言命令来识别可导航区域的任务。然而,这项工作仅限于场景理解,并且不包括导航仿真,因为轨迹规划依赖于精确的目标点位置,而这一点并未得到解决。
端到端自动驾驶
端到端学习研究在近年来备受关注,其目的是采用数据驱动的统一学习方式,确保安全运动规划,与传统基于规则的独立优化每个任务的设计相比,后者会导致累积误差。在nuScenes数据集上,UniAD是当前最先进的方法,使用栅格化场景表示来识别P3框架中的关键组件。ST-P3是先前的艺术,它探讨了基于视觉的端到端ADS的可解释性。由于计算限制,选择ST-P3作为我们的运动规划基准,而不是UniAD。
面向规划的视觉语言导航
在自动驾驶系统(ADS)领域,大型语言模型(LLMs)因其多模态理解和与人类的自然交互而展现出有前景的结果。现有工作使用LLM来推理驾驶场景并预测控制输入。然而,这些工作仅限于开环设置。更近的工作关注于适应闭环解决方案。它们要么直接估计控制动作,要么将它们映射到一组离散的动作空间。这些方法较为粗糙,容易受到感知错误的影响,因为它们严重依赖于VLMs的知识检索能力,这可能导致在需要复杂控制动作组合的复杂情况下(如泊车、高速公路并线等)产生不流畅的运动。
数据集
详细阐述了作者为开发结合视觉数据和导航指令的智能驾驶agent而创建的数据集和标注策略。作者利用CARLA仿真器提供的视觉中心数据,并辅以导航指令。他们假设agent拥有执行成功闭环导航所需的特权信息。
数据集概览:先前的工作,如Talk2Car数据集,主要关注通过为目标引用标注边界框来进行场景理解。进一步的工作,如Talk2Car-RegSeg,则通过标注可导航区域的分割mask来包含导航。作者在此基础上扩展了数据集,涵盖各种驾驶操作,包括车道变更、速度调整、转弯、绕过其他物体或车辆、通过交叉口以及在行人横道或交通信号灯处停车,并在其中演示了闭环导航。创建的LeGo-Drive数据集包含4500个训练点和1000个验证点。作者使用复杂和简单的命令标注进行了结果、基准比较和消除实验。
仿真器设置:LeGo-Drive数据集收集过程包括两个阶段:
- 同步记录驾驶agent状态与相机传感器数据,随后记录交通agent,
- 解析和标注收集的数据,以导航指令为标注。
作者以10 FPS的速率录制数据,为避免连续帧之间的冗余,数据点在10米的距离间隔内进行过滤。对于每个帧,他们收集了自车的状态(位置和速度)、自车车道(前后各50米范围)、前RGB相机图像,以及使用基于规则的专家agent收集的交通agent状态(位置和速度),所有这些都以自车帧为单位。数据集涵盖了6个不同的城镇,具有各种独特的环境,代表不同的驾驶场景,包括不同的车道配置、交通密度、光照和天气条件。此外,数据集还包括了户外场景中常见的各种物体,如公交车站、食品摊位和交通信号灯。
语言命令标注:每个帧都手动标注了适当的导航命令,以目标区域分割mask的形式,以涵盖各种驾驶场景。作者考虑了3种不同的命令类别:
- 以目标为中心的命令,直接指向当前相机帧中可见的目标,
- 车道操作命令,与车道变更或车道内调整相关的指令,
- 复合命令,连接多个指令以模拟实际驾驶场景。
作者利用ChatGPT API生成具有相似语义含义的不同变体。表I展示了他们数据集中的一些示例指令。值得注意的是,作者并未涵盖误导性指令的处理。这种能力对于场景推理模型至关重要,可能被视为未来的扩展范围;然而,它超出了当前研究的范围。
表I:LeGo-Drive数据集的导航指令示例
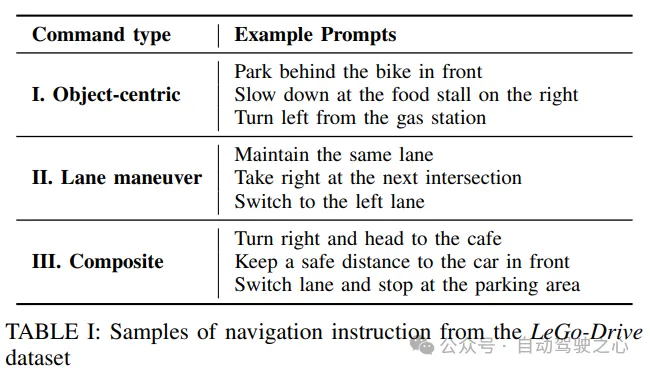
LeGo-Drive架构
本文提出了LeGo-Drive框架,旨在解决从VLA进行控制动作的粗略估计的问题,将这一问题视为一个短期目标实现问题。这是通过学习轨迹优化器的参数和行为输入,生成并改进与导航指令一致的可实现目标来实现的。
图3:LeGo-Drive架构
如图3所示,架构由两个主要部分组成:
- 目标预测模块,接受前视图图像和相应的语言命令,生成或预测一个分割mask ,然后是一个目标位置。
- 可微优化器,生成一个轨迹,共同优化估计的目标和轨迹优化器的参数,当进行端到端训练时,导致所需位置坐标到可导航位置的改进。
目标预测模块
为编码给定的导航命令,作者使用CLIP 标记器对语言命令进行标记,并经过CLIP文本编码器获得文本嵌入。为了从给定的前摄像头图像中获得图像特征,使用带有ResNet-101骨干网络的CLIP图像编码器。提取不同视觉特征,通过卷积块ConvBlocki进行处理,以标准大小和相等的通道尺寸、高度和宽度进行重塑。
为捕捉图像和文本特征的跨模态上下文,作者进一步使用来自DETR架构的transformer编码器。文本特征与不同的个体拼接,得到多模态特征,然后单独通过transformer编码器,其中多头自注意力层帮助跨模态交互不同类型的特征,以获得形状相同的编码器输出。
有两个解码头,一个用于分割mask预测,另一个用于目标点预测。分割mask预测头将进行重塑和重组,得到,并使用ASPP解码器。目标点预测解码器由卷积层和全连接层组成,输出形状为表示图像上的像素位置。
首先,分割mask预测头与真实分割mask之间的BCE损失进行端到端训练。在几个epoch之后,目标点预测头以平滑L1损失与真实目标点之间的差异进行类似端到端的训练。
复杂命令和场景理解:为处理最终目标位置在当前帧中不可见的复合指令,通过将复杂命令分解为需要顺序执行的原子命令列表来适应他们的方法。例如,“切换到左车道然后跟着黑色汽车”可以分解为“切换到左车道”和“跟着黑色汽车”。为分解这种复杂命令,作者构建了一个原子命令列表L,涵盖广泛的简单操作,如车道变更、转弯、速度调整和目标引用。在收到复杂命令后,作者利用小样本学习技术提示LLM将给定复杂命令分解为原子命令列表li,来自L。这些原子命令随后迭代执行,预测的目标点位置作为中间路点帮助我们达到最终目标点。
神经可微优化器
计划采用优化问题的形式,其中嵌入有可学习参数,以改进由VLA生成的下游任务的跟踪目标,并加速其收敛。作者首先介绍了他们轨迹优化器的基本结构,然后介绍了其与网络的集成。
基本问题公式:作者假设可以获得车道中心线,并使用它来构建Frenet框架。在Frenet框架中,轨迹规划具有优势,即汽车在纵向和横向运动与Frenet框架的X和Y轴对齐。在给定这种表示的情况下,他们的轨迹优化问题具有以下形式:
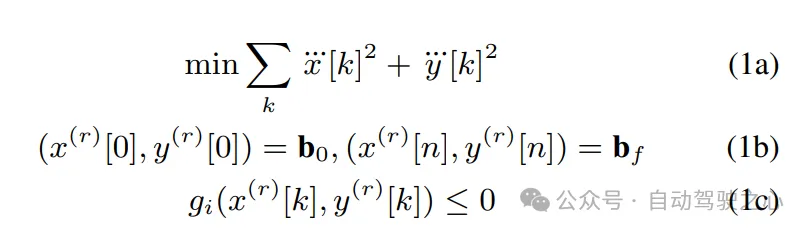
等式约束(1b)确保计划的轨迹满足初始和最终边界条件,在r阶导数上。在公式中使用r={0,1,2}。不等式约束(1c)也依赖于r阶导数的上界,包括速度、加速度、车道偏移以及避碰和曲率约束。的代数结构取自先前的工作。
为确保他们在平滑轨迹的空间中优化,作者以以下形式参数化沿X-Y方向的运动:
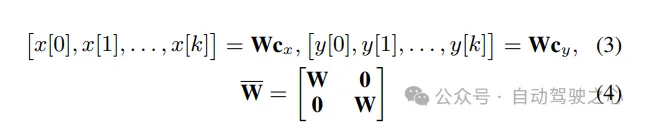
使用(4),优化(1a)-(1c)可以写成以下紧凑形式
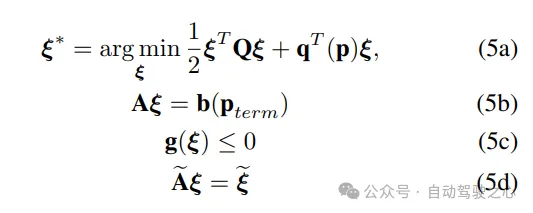
端到端训练
LeGo-Drive E2E:表示目标预测模块和规划器模块的联合训练。模型在组合损失上训练,其中目标损失是预测目标与预测轨迹端点之间的均方误差损失,规划器损失Lplanner是违反非凸约束g的组合,涉及车道偏移、避碰和运动学约束。梯度从规划器流向目标预测部分。
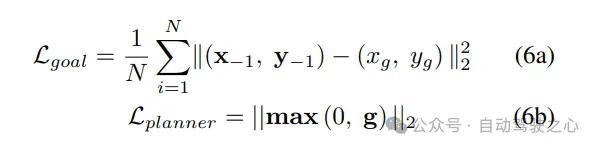
LeGo-Drive Decoupled:表示目标预测模块和规划器模块分别训练的过程。首先,目标预测模块在预测目标与真实目标之间的均方误差损失上进行训练。然后,规划器在上训练,同时冻结目标预测模块的参数。
端到端训练需要通过优化层建模轨迹规划过程进行反向传播,可以通过隐式微分和算法展开两种方式进行。作者建立了一个自定义的反向传播程序,遵循算法展开,这种方法可以处理约束,并且反向传播可以避免矩阵分解。两种方法的性能在表II中展示,并在后面章节中进行分析。该方法的核心创新在于其模块化的端到端规划框架,其中框架优化目标预测模块,同时优先考虑轨迹优化,确保获取的行为输入有效地促进优化器的收敛。不同模块的迭代改进形成系统设计的基础,确保系统内部的协同和迭代改进循环。
表II:模型比较:
实验
实现细节
感知模块输入:模型输入包括1600x1200像素的RGB图像和最大长度为20个词的语言指令。使用CLIP提取视觉和文本特征,并使用Transformer进行多模态交互,输出分割mask和目标点预测。
规划模块:基于优化器的可微规划器在道路对齐的Frenet坐标系中操作,考虑50米范围内的5个最近障碍物。规划器以车辆控制和动力学约束为条件,并输出满足约束的平滑轨迹
训练:使用Adam优化器,权重衰减为,batch size为16,学习率初始化为,进行100个epoch的训练。训练过程中需要通过算法展开进行反向传播
评估指标
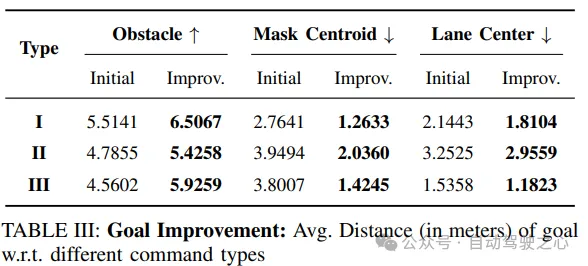
目标评估:评估预测目标与mask质心和车道中心的接近程度,以及与最近障碍物的距离。这些指标用于衡量模型在理解语言指令并准确预测目标位置方面的性能。
轨迹评估:使用最小最终位移误差(minFDE)和成功率(SR)评估轨迹性能。minFDE表示预测轨迹终点与目标位置的欧氏距离,SR表示车辆在3米范围内成功到达目标的比例。这些指标用于评估模型在生成可行、平滑的轨迹方面的性能。
平滑性:评估轨迹接近目标的平稳程度,采用平滑指数度量。较低的平滑指数表示轨迹更平滑地接近目标,该指标用于衡量模型生成轨迹的平滑性。
实验结果
目标改进:通过比较解耦训练和端到端训练的目标预测指标,结果显示端到端训练方法在所有指标上表现更好。特别是在复合指令下,目标改进幅度更大,证明了该方法的有效性。
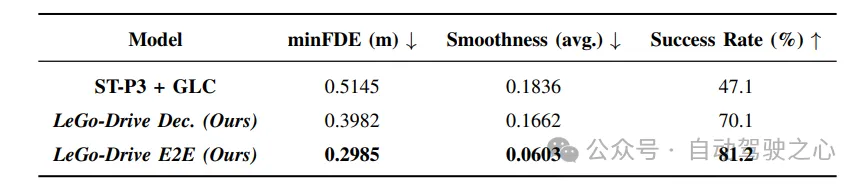
轨迹改进:与基准方法ST-P3相比,LeGo-Drive模型在目标可达性、轨迹平滑性等方面明显优于基准方法。特别是复合指令下的最小最终位移误差降低了60%,进一步证明了端到端训练的优势。
模型比较:通过比较端到端方法、解耦训练和基准方法,结果显示端到端方法在目标可达性和轨迹平滑性方面明显优于其他方法。
定性结果:定性结果直观展示了端到端方法生成的轨迹比基准方法更平滑,进一步验证了实验结果。
表Ⅲ: Goal Improvement
表IV: Trajectory Evaluation
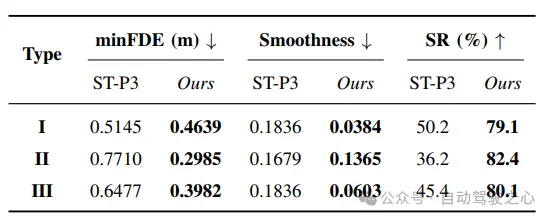

图4:不同以目标为中心的停车命令的目标改进。(左)查询命令的前视图图像。(右)场景的俯视图。目标位置从绿色中不理想的位置((a)中的汽车顶部和(b)中的路边边缘)改进为红色中的可到达位置
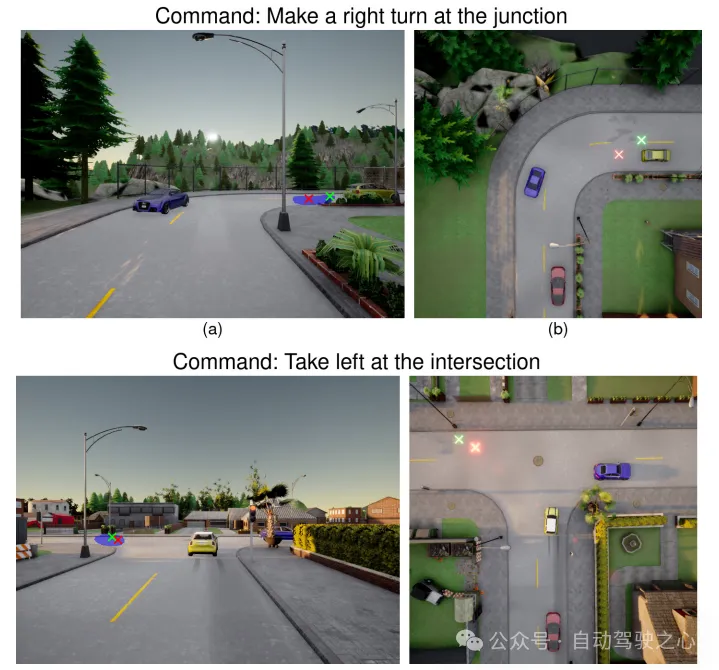
图5:车削指令情况下的结果。在这两幅图中(上、下),绿色的初始目标与车道中心的偏移量较大。该模型近似于改进版本的红色显示到车道中心

图6:不同导航指令下轨迹改进的定性结果。与我们的(绿色)相比,红色显示的基线ST-P3轨迹始终规划着一个不光滑的轨迹。所有行中的第三张图显示了我们在Frenet框架中的规划,其中红色矩形表示自我车辆,蓝色表示周围车辆,红色十字表示目标位置以及用黑色实线表示的车道边界
实验结果证明了端到端训练方法的有效性,能够提高目标预测的准确性和轨迹的平滑性。
结论
本文通过将所提出的端到端方法作为目标点导航问题来解决,揭示了其与传统解耦方法相比的明显优势。目标预测模块与基于可微分优化器的轨迹规划器的联合训练突出了方法的有效性,从而提高了准确性和上下文感知目标预测,最终产生更平滑、无碰撞的可导航轨迹。此外,还证明了所提出的模型适用于当前的视觉语言模型,以丰富的场景理解和生成带有适当推理的详细导航指令。
























