本文经自动驾驶之心公众号授权转载,转载请联系出处。
标注之殇
静态物体检测(Static object detection,SOD),包括交通信号灯、导向牌和交通锥,大多数算法是数据驱动深度神经网络,需要大量的训练数据。现在的做法通常是对大量的训练样本在 LIDAR 扫描的点云数据上进行手动标注,以修复长尾案例。

手动标注难以捕捉真实场景的变异性和复杂性,通常无法考虑遮挡、不同的光照条件和多样的视角(如图1中的黄色箭头)。整个过程链路长、极其耗时、容易出错、成本颇高(如图2)。所以目前公司都寻求自动标注方案,特别是基于纯视觉,毕竟不是每辆车都有激光雷达。
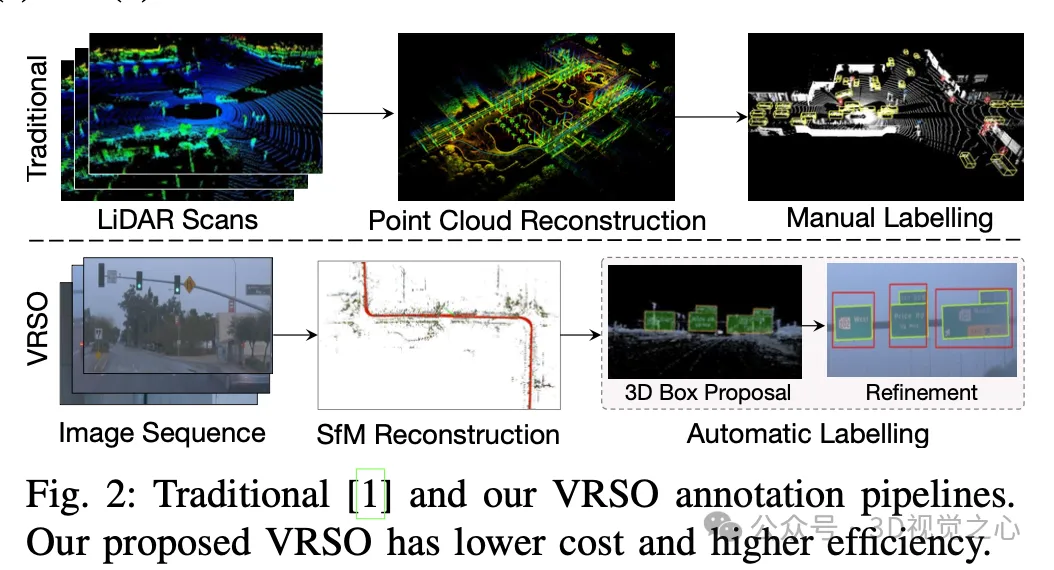
VRSO 是一种以视觉为主、面向静态对象标注的标注系统,主要利用了 SFM、2D 物体检测和实例分割结果的信息,整体效果:
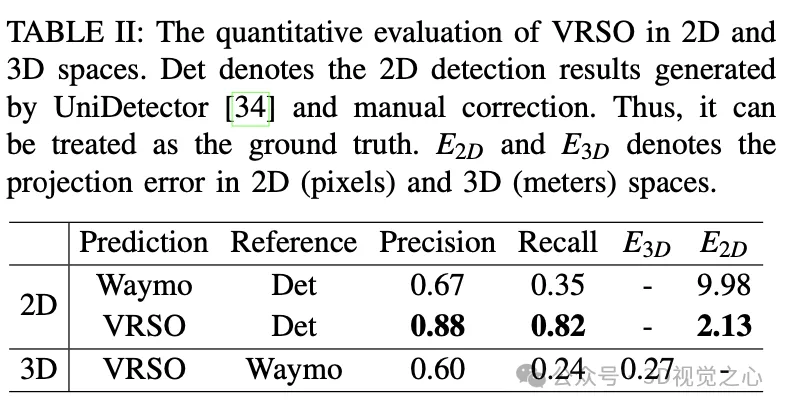
- 标注的平均投影误差仅为2.6像素,约为Waymo标注的四分之一(10.6像素)
- 与人工标注相比,速度提高了约16倍
对于静态物体,VRSO通过实例分割和轮廓提取关键点,解决了从不同视角集成和去重静态对象的挑战,以及由于遮挡问题而导致观察不足的困难,从而提高了标注的准确性。从图1上看,与Waymo Open数据集的手动标注结果相比,VRSO展示了更高的鲁棒性和几何精度。
(都看到这里了,不如大拇指往上滑,点击最上方的卡片关注我,整个操作只会花你 1.328 秒,然后带走未来所有干货,万一有用呢~)
破局之法
VRSO系统主要分为两部分:场景重建和静态对象标注。
重建部分不是重点,就是基于 SFM 算法来恢复图像 pose 和稀疏的 3D 关键点。
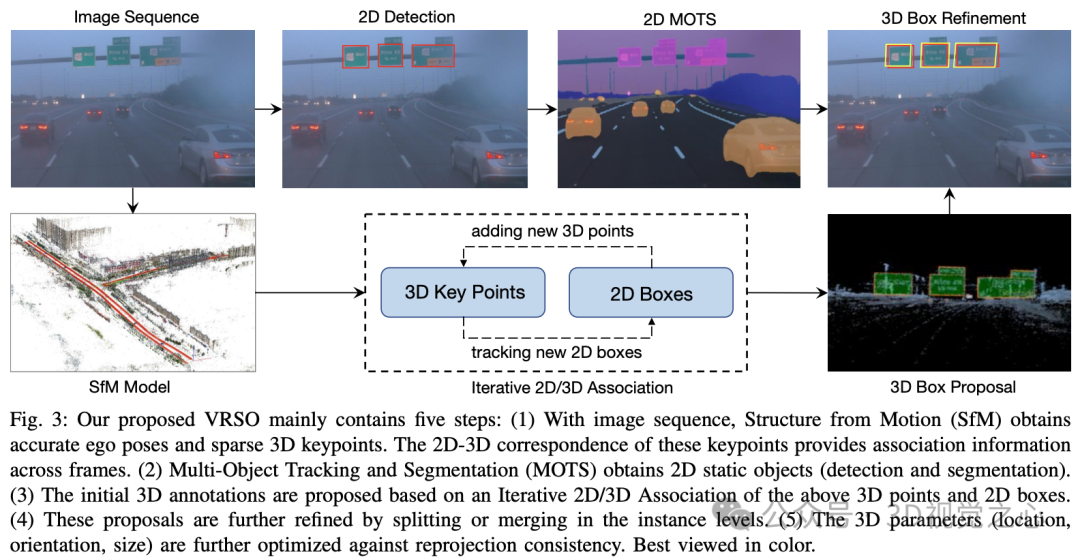
静态对象标注算法,配合伪代码,大致流程是(以下会分步骤详细展开):
- 采用现成的2D物体检测和分割算法生成候选
- 利用 SFM 模型中的 3D-2D 关键点对应关系来跟踪跨帧的 2D 实例
- 引入重投影一致性来优化静态对象的3D注释参数

1.跟踪关联
- step 1:根据 SFM 模型的关键点提取 3D 边界框内的 3D 点。
- step 2:根据 2D-3D 匹配关系计算每个 3D 点在 2D 地图上的坐标。
- step 3:基于 2D 地图坐标和实例分割角点确定当前 2D 地图上 3D 点的对应实例。
- step 4:确定每个 2D 图像的 2D 观察与 3D 边界框之间的对应关系。
2.proposal 生成
对静态物体的 3D 框参数(位置、方向、大小)进行整个视频剪辑的初始化。SFM 的每个关键点都有准确的3D位置和对应的 2D 图像。对于每个 2D 实例,提取 2D 实例掩码内的特征点。然后,一组对应 3D 关键点可以被视为 3D 边界框的候选。
路牌被表示为在空间中具有方向的矩形,它有6个自由度,包括平移(、、)、方向(θ)和大小(宽度和高度)。考虑到其深度,交通信号灯具有7个自由度。交通锥的表示方式与交通信号灯类似。
3.proposal refine
- step 1:从 2D 实例分割中提取每个静态物体的轮廓。
- step 2:为轮廓轮廓拟合最小定向边界框(OBB)。
- step 3:提取最小边界框的顶点。
- step 4:根据顶点和中心点计算方向,并确定顶点顺序。
- step 5:基于2D检测和实例分割结果进行了分割和合并过程。
- step 6:检测并拒绝包含遮挡的观察。从2D实例分割蒙版中提取顶点要求每个标牌的四个角都可见。如果有遮挡,从实例分割中提取轴对齐边界框(AABB),并计算AABB与2D检测框之间的面积比。如果没有遮挡,这两种面积计算方法应该是接近的。

4.三角化
通过三角化在3D条件下获取静态物体的初始顶点值。
通过检查在场景重建期间由 SFM 和实例分割获得的3D边界框中的关键点数量,只有关键点数量超过阈值的实例被认为是稳定且有效的观测。对于这些实例,相应的 2D 边界框被视为有效的观测。通过多幅图像的 2D 观测,将 2D边界框顶点进行三角化,以获取边界框的坐标。
对于没有在掩模上区分“左下、左上、右上、右上和右下”顶点的圆形标牌,需要识别这些圆形标牌。使用 2D 检测结果作为圆形物体的观测结果,使用 2D 实例分割掩模进行轮廓提取。通过最小二乘拟合算法计算出中心点和半径。圆形标牌的参数包括中心点(、、)、方向(θ)和半径()。
5.tracking refine
跟踪基于 SFM 的特征点匹配。根据 3D 边界框顶点的欧式距离和 2D 边界框投影 IoU 来确定是否合并这些分开的实例。一旦合并完成,实例内的 3D 特征点可以聚集以关联更多的2D特征点。进行迭代2D-3D关联,直到无法添加任何2D特征点为止。
6.最终参数优化
以矩形标牌为例,可优化的参数包括位置(、、)、方向(θ)和大小(、),总共六个自由度。主要步骤包括:
- 将六个自由度转换为四个 3D 点,并计算旋转矩阵。
- 将转换后的四个 3D 点投影到2D图像上。
- 计算投影结果与实例分割得到的角点结果之间的残差。
- 使用 Huber 进行优化更新边界框参数
标注效果


也有一些具有挑战性的长尾案例,例如极低的分辨率和照明不足。

总结一下
VRSO 框架实现了静态物体高精度和一致的3D标注,紧密集成了检测、分割和 SFM 算法,消除了智能驾驶标注中的人工干预,提供了与基于LiDAR的手动标注相媲美的结果。和被广泛认可的Waymo Open Dataset进行了定性和定量评估:与人工标注相比,速度提高了约16倍,同时保持了最佳的一致性和准确性。