随着大模型的不断进化,LLM智能体——这些强大的算法实体已经展现出解决复杂多步骤推理任务的潜力。从自然语言处理到深度学习,LLM智能体正逐渐成为研究和工业界的焦点,它们不仅能够理解和生成人类语言,还能在多变的环境中制定策略、执行任务,甚至使用API调用和编码来构建解决方案。
在这样的背景下,AgentQuest框架的提出具有里程碑意义,它不仅为LLM智能体的评估和进步提供了一个模块化的基准测试平台,而且通过其易于扩展的API,为研究人员提供了一个强大的工具,以更细粒度地跟踪和改进这些智能体的性能。AgentQuest的核心在于其创新的评估指标——进展率和重复率,它们能够揭示智能体在解决任务过程中的行为模式,从而指导架构的优化和调整。
4月10日发表的论文《AgentQuest: A Modular Benchmark Framework to Measure Progress and Improve LLM Agents》由一支多元化的研究团队撰写,他们来自NEC欧洲实验室、都灵理工大学和北马其顿的圣西里尔与美多德大学。这篇论文并将在计算语言学协会北美分会2024年会议(NAACL-HLT 2024)上展示,这标志着该团队在人类语言技术领域的研究成果得到了同行的认可,这不仅是对AgentQuest框架价值的认可,也是对LLM智能体未来发展潜力的肯定。
AgentQuest框架作为衡量和改进大型语言模型(LLM)智能体性能的工具,其主要贡献在于提供了一个模块化、可扩展的基准测试平台。这一平台不仅能够评估智能体在特定任务上的表现,还能够通过进展率和重复率等指标,揭示智能体在解决问题过程中的行为模式。AgentQuest的优势在于其灵活性和开放性,使得研究人员可以根据自己的需求定制基准测试,从而推动LLM智能体技术的发展。
AgentQuest框架概述
AgentQuest框架是一个创新的研究工具,旨在衡量和改进大型语言模型(LLM)智能体的性能。它通过提供一系列模块化的基准测试和评估指标,使研究人员能够系统地跟踪智能体在执行复杂任务时的进展,并识别改进的潜在领域。
AgentQuest是一个支持多种基准测试和代理架构的模块化框架,它引入了两个新的指标——进展率和重复率——来调试代理架构的行为。这个框架定义了一个标准接口,用于将任意代理架构与多样的基准测试连接起来,并从中计算进展率和重复率。
在AgentQuest中实现了四个基准测试:ALFWorld、侧面思维谜题(Lateral Thinking Puzzles)、Mastermind和数独。后两者是AgentQuest新引入的。可以轻松添加额外的基凌测试,而无需对测试中的代理进行更改。
 图片
图片
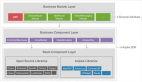
图1:现有框架和AgentQuest中的智能体基准交互概述。AgentQuest定义了一个通用接口,用于与基准交互和计算进度指标,从而简化了新基准的添加,并允许研究人员评估和调试其智能体架构。
基本构成和功能
AgentQuest框架的核心是其模块化设计,它允许研究人员根据需要添加或修改基准测试。这种灵活性是通过将基准测试和评估指标分离成独立的模块来实现的,每个模块都可以单独开发和优化。框架的主要组件包括:
基准测试模块:这些是预定义的任务,智能体必须执行。它们涵盖了从简单的文字游戏到复杂的逻辑谜题等多种类型。
评估指标模块:提供了一套量化智能体性能的工具,如进展率和重复率,这些指标帮助研究人员理解智能体在任务中的行为模式。
API接口:允许研究人员将自己的智能体架构与AgentQuest框架连接,以及与外部数据源和服务交互。
模块化基准测试和指标的重要性
模块化基准测试的一个关键优势是它们提供了一种标准化的方法来评估不同智能体的性能。这意味着研究人员可以在相同的条件下比较不同智能体的结果,从而确保结果的一致性和可比性。此外,模块化设计还允许研究人员根据特定研究的需求定制基准测试,这在传统的基准测试框架中往往难以实现。
评估指标同样重要,因为它们提供了对智能体性能的深入洞察。例如,进展率可以显示智能体在解决任务过程中的效率,而重复率则揭示了智能体是否在某些步骤上陷入重复,这可能表明需要改进决策过程。
AgentQuest的扩展性
AgentQuest的API接口是其扩展性的关键。通过API,研究人员可以轻松地将AgentQuest集成到现有的研究工作流中,无论是添加新的基准测试、评估指标,还是连接到外部数据源和服务。这种扩展性不仅加速了研究的迭代过程,还促进了跨学科合作,因为来自不同领域的专家可以共同工作,利用AgentQuest框架解决共同的研究问题。
AgentQuest框架通过其模块化的基准测试和评估指标,以及通过API实现的扩展性,为LLM智能体的研究和开发提供了一个强大的平台。它不仅促进了研究的标准化和可复制性,还为智能体未来的创新和合作铺平了道路。
基准测试与评估指标
在AgentQuest框架中,基准测试是评估LLM智能体性能的关键组成部分。这些测试不仅提供了一个标准化的环境来比较不同智能体的能力,而且还能够揭示智能体在解决特定问题时的行为模式。
AgentQuest公开了一个单一的统一Python界面,即驱动程序和两个反映代理-环境交互组件的类(即观察和行动)。观察类有两个必需属性:(i)输出,一个字符串,报告环境状态的信息;(ii)完成,一个布尔变量,指示最终任务当前是否完成。行动类有一个必需属性,行动值。这是智能体直接输出的字符串。一旦处理并提供给环境,它就会触发环境变化。为了定制交互,开发者可以定义可选属性。
Mastermind基准测试
Mastermind是一个经典的逻辑游戏,玩家需要猜测一个隐藏的颜色代码。在AgentQuest框架中,这个游戏被用作基准测试之一,智能体的任务是通过一系列的猜测来确定正确的代码。每次猜测后,环境会提供反馈,告诉智能体有多少个颜色是正确的,但位置错误,以及有多少个颜色和位置都正确。这个过程持续进行,直到智能体猜出正确的代码或达到预设的步数限制。
 图2:我们在这里提供了一个Mastermind实现交互的示例。
图2:我们在这里提供了一个Mastermind实现交互的示例。
Sudoku基准测试
Sudoku是另一个流行的逻辑谜题,它要求玩家在9x9的网格中填入数字,使得每一行、每一列以及每个3x3的子网格中的数字都不重复。在AgentQuest框架中,Sudoku被用作基准测试,以评估智能体在空间推理和规划方面的能力。智能体必须生成有效的数字填充策略,并且在有限的步数内解决谜题。
评估指标:进展率和重复率
AgentQuest引入了两个新的评估指标:进展率(PR)和重复率(RR)。进展率是一个介于0到1之间的数值,用来衡量智能体在完成任务过程中的进展。它是通过将智能体达到的里程碑数量除以总里程碑数量来计算的。例如,在Mastermind游戏中,如果智能体猜出了两个正确的颜色和位置,而总共需要猜出四个,那么进展率就是0.5。
重复率则衡量智能体在执行任务过程中重复相同或相似动作的倾向。在计算重复率时,会考虑到智能体之前的所有动作,并使用相似性函数来确定当前动作是否与之前的动作相似。重复率是通过将重复动作的数量除以总动作数量(减去第一步)来计算的。
通过指标评估和改进LLM智能体性能
这些指标为研究人员提供了一个强有力的工具,用于分析和改进LLM智能体的性能。通过观察进展率,研究人员可以了解智能体在解决问题方面的效率,并识别可能的瓶颈。同时,重复率的分析可以揭示智能体在决策过程中可能存在的问题,如过度依赖某些策略或缺乏创新。
 表1:AgentQuest中提供的基准概览。
表1:AgentQuest中提供的基准概览。
总的来说,AgentQuest框架中的基准测试和评估指标为LLM智能体的发展提供了一个全面的评估体系。通过这些工具,研究人员不仅能够评估智能体的当前性能,还能够指导未来的改进方向,从而推动LLM智能体在各种复杂任务中的应用和发展。
AgentQuest的应用案例
AgentQuest框架的实际应用案例提供了对其功能和效果的深入理解,通过Mastermind和其他基准测试,我们可以观察到LLM智能体在不同场景下的表现,并分析如何通过特定策略来改进它们的性能。
Mastermind的应用案例
在Mastermind游戏中,AgentQuest框架被用来评估智能体的逻辑推理能力。智能体需要猜测一个由数字组成的隐藏代码,每次猜测后,系统会提供反馈,指示正确数字的数量和位置。通过这个过程,智能体学习如何根据反馈调整其猜测策略,以更有效地达到目标。
在实际应用中,智能体的初始表现可能并不理想,经常重复相同或相似的猜测,导致重复率较高。然而,通过分析进展率和重复率的数据,研究人员可以识别出智能体决策过程中的不足,并采取措施进行改进。例如,通过引入记忆组件,智能体可以记住之前的猜测,并避免重复无效的尝试,从而提高效率和准确性。
其他基准测试的应用案例
除了Mastermind,AgentQuest还包括其他基准测试,如Sudoku、文字游戏和逻辑谜题等。在这些测试中,智能体的表现同样受到进展率和重复率指标的影响。例如,在Sudoku测试中,智能体需要填写一个9x9的网格,使得每行、每列和每个3x3的子网格中的数字都不重复。这要求智能体具备空间推理能力和策略规划能力。
在这些测试中,智能体可能会遇到不同的挑战。有些智能体可能在空间推理方面表现出色,但在策略规划方面存在缺陷。通过AgentQuest框架提供的详细反馈,研究人员可以针对性地识别问题所在,并通过算法优化或训练方法的调整来提高智能体的整体性能。
记忆组件的影响
记忆组件的加入对智能体的性能有显著影响。在Mastermind测试中,加入记忆组件后,智能体能够避免重复无效的猜测,从而显著降低重复率。这不仅提高了智能体解决问题的速度,也提高了成功率。此外,记忆组件还使智能体能够在面对类似问题时更快地学习和适应,从而在长期内提高其学习效率。
总体而言,AgentQuest框架通过提供模块化的基准测试和评估指标,为LLM智能体的性能评估和改进提供了强有力的工具。通过实际应用案例的分析,我们可以看到,通过调整策略和引入新的组件,如记忆模块,可以显著提高智能体的性能。
实验设置与结果分析
在AgentQuest框架的实验设置中,研究人员采用了一种参考架构,该架构基于现成的聊天智能体,由GPT-4等大型语言模型(LLM)驱动。这种架构的选择是因为它直观、易于扩展,并且是开源的,这使得研究人员能够轻松地集成和测试不同的智能体策略。
 图片
图片
图4:Mastermind和LTP的平均进度率PRt和重复率RRt。Mastermind:一开始RRt很低,但在第22步后会增加,同时进度也会停滞在55%。LTP:起初,更高的RRt允许代理通过进行小的变化来取得成功,但后来这种变化趋于平稳。
实验设置
实验的设置包括了多个基准测试,如Mastermind和ALFWorld,每个测试都旨在评估智能体在特定领域的性能。实验中设定了执行步骤的最大数量,通常为60步,以限制智能体在解决问题时可以尝试的次数。这种限制模拟了现实世界中资源有限的情况,并迫使智能体必须在有限的尝试中找到最有效的解决方案。
实验结果分析
在Mastermind基准测试中,实验结果显示,智能体在没有记忆组件的情况下,其重复率相对较高,进展率也受到限制。这表明智能体在尝试解决问题时,往往会陷入重复无效的猜测。然而,当引入记忆组件后,智能体的性能得到显著提升,成功率从47%提高到60%,重复率降至0%。这说明记忆组件对于提高智能体的效率和准确性至关重要。
 图片
图片
图5:Mastermind和LTP中重复操作的示例。Mastermind:一开始有一系列独特的动作,但后来却被困在一遍又一遍地重复相同的动作。LTP:重复的动作是同一问题的微小变化,会导致进步。
在ALFWorld基准测试中,智能体需要在一个文本世界中探索以定位对象。实验结果表明,尽管智能体在探索解决方案空间时限制了行动重复(RR60 = 6%),但它未能解决所有游戏(PR60 = 74%)。这种差异可能是由于智能体在发现对象时需要更多的探索步骤。当将基准测试的运行时间延长到120步时,成功率和进展率都有所提高,这进一步证实了AgentQuest在理解智能体失败方面的用处。
智能体架构的调整
根据AgentQuest的指标,研究人员可以对智能体架构进行调整。例如,如果发现智能体在某个基准测试中重复率较高,可能需要改进其决策算法,以避免重复无效的尝试。同样,如果进展率低,可能需要优化智能体的学习过程,以更快地适应环境并找到解决问题的方法。
AgentQuest框架提供的实验设置和评估指标为LLM智能体的性能提供了深入的洞察。通过分析实验结果,研究人员可以识别智能体的强项和弱点,并据此调整智能体架构,以提高其在各种任务中的表现。
讨论与未来工作
AgentQuest框架的提出,为大型语言模型(LLM)智能体的研究和发展开辟了新的道路。它不仅提供了一个系统的方法来衡量和改进LLM智能体的性能,而且还推动了研究社区对于智能体行为的深入理解。
AgentQuest在LLM智能体研究中的潜在影响
AgentQuest通过其模块化的基准测试和评估指标,使研究人员能够更精确地衡量LLM智能体在特定任务上的进展和效率。这种精确的评估能力对于设计更高效、更智能的智能体至关重要。随着LLM智能体在各个领域的应用越来越广泛,从客户服务到自然语言处理,AgentQuest提供的深入分析工具将帮助研究人员优化智能体的决策过程,提高其在实际应用中的表现。
AgentQuest在促进透明度和公平性方面的作用
AgentQuest的另一个重要贡献是提高了LLM智能体研究的透明度。通过公开的评估指标和可复制的基准测试,AgentQuest鼓励了开放科学的实践,使研究结果更容易被验证和比较。此外,AgentQuest的模块化特性允许研究人员自定义基准测试,这意味着可以根据不同的需求和背景设计测试,从而促进了研究的多样性和包容性。
AgentQuest未来的发展和研究社区的可能贡献
紧跟技术的推进,AgentQuest框架有望继续扩展和完善。随着新的基准测试和评估指标的加入,AgentQuest将能够覆盖更多类型的任务和场景,为LLM智能体的评估提供更全面的视角。此外,随着人工智能技术的进步,AgentQuest也可能会集成更先进的功能,如自动调整智能体架构的能力,以实现更高效的性能优化。
研究社区对AgentQuest的贡献也是其发展不可或缺的一部分。开源的特性意味着研究人员可以共享他们的改进和创新,从而加速AgentQuest框架的进步。同时,研究社区的反馈和实践经验将帮助AgentQuest更好地满足实际应用的需求,推动LLM智能体技术向前发展。
参考资料:https://arxiv.org/abs/2404.06411