引言
Redis作为一款高效的内存数据存储系统,凭借其优异的读写性能和丰富的数据结构支持,被广泛应用于缓存层以提升整个系统的响应速度和吞吐量。尤其是在与关系型数据库(如MySQL、PostgreSQL等)结合使用时,通过将热点数据存储在Redis中,可以在很大程度上缓解数据库的压力,提高整体系统的性能表现。
然而,在这种架构中,一个不容忽视的问题就是如何确保Redis缓存与数据库之间的双写一致性。所谓双写一致性,是指当数据在数据库中发生变更时,能够及时且准确地反映在Redis缓存中,反之亦然,以避免出现因缓存与数据库数据不一致导致的业务逻辑错误或用户体验下降。尤其在高并发场景下,由于网络延迟、并发控制等因素,保证双写一致性变得更加复杂。
在实际业务开发中,若不能妥善处理好缓存与数据库的双写一致性问题,可能会带来诸如数据丢失、脏读、重复读等一系列严重影响系统稳定性和可靠性的后果。本文将尝试剖析这一问题,介绍日常开发中常用的一些策略和模式,并结合具体场景分析不同的解决方案,为大家提供一些有力的技术参考和支持。
 图片
图片
谈谈分布式系统中的一致性
分布式系统中的一致性指的是在多个节点上存储和处理数据时,确保系统中的数据在不同节点之间保持一致的特性。在分布式系统中,一致性通常可以分为以下几个类别:
1. 强一致性:所有节点在任何时间都看到相同的数据。任何更新操作都会立即对所有节点可见,保证了数据的强一致性。这意味着,如果一个节点完成了写操作,那么所有其他节点读取相同的数据之后,都将看到最新的结果。强一致性通常需要付出更高的代价,例如增加通信开销和降低系统的可用性。
2. 弱一致性: 系统中的数据在某些情况下可能会出现不一致的状态,但最终会收敛到一致状态。弱一致性下的系统允许在一段时间内,不同节点之间看到不同的数据状态。弱一致性通常用于需要在性能和一致性之间进行权衡的场景,例如缓存系统等。
3. 最终一致性: 是弱一致性的一种特例,它保证了在经过一段时间后,系统中的所有节点最终都会达到一致状态。尽管在数据更新时可能会出现一段时间的不一致,但最终数据会收敛到一致状态。最终一致性通常通过一些技术手段来实现,例如基于版本向量或时间戳的数据复制和同步机制。
除此之外,还有一些其他的一致性类别,例如:因果一致性,顺序一致性,基于本篇文章讨论的重点,我们暂且只讨论以上三种一致性类别。
什么是双写一致性问题?
在分布式系统中,双写一致性主要指在一个数据同时存在于缓存(如Redis)和持久化存储(如数据库)的情况下,任何一方的数据更新都必须确保另一方数据的同步更新,以保持双方数据的一致状态。这一问题的核心在于如何在并发环境下正确处理缓存与数据库的读写交互,防止数据出现不一致的情况。
典型场景分析
1. 写数据库后忘记更新缓存:当直接对数据库进行更新操作而没有相应地更新缓存时,后续的读请求可能仍然从缓存中获取旧数据,导致数据的不一致。
2. 删除缓存后数据库更新失败: 在某些场景下,为了保证数据新鲜度,会在更新数据库前先删除缓存。但如果数据库更新过程中出现异常导致更新失败,那么缓存将长时间处于空缺状态,新的查询将会直接命中数据库,加重数据库压力,并可能导致数据版本混乱。
3. 并发环境下读写操作的交错执行:在高并发场景下,可能存在多个读写请求同时操作同一份数据的情况。比如,在删除缓存、写入数据库的过程中,新的读请求获取到了旧的数据库数据并放入缓存,此时就出现了数据不一致的现象。
4. 主从复制延迟与缓存失效时间窗口冲突:对于具备主从复制功能的数据库集群,主库更新数据后,存在一定的延迟才将数据同步到从库。如果在此期间缓存刚好过期并重新从数据库加载数据,可能会从尚未完成同步的从库读取到旧数据,进而导致缓存与主库数据的不一致。
数据不一致不仅会导致业务逻辑出错,还可能引发用户界面展示错误、交易状态不准确等问题,严重时甚至会影响系统的正常运行和用户体验。
解决双写一致性问题的主要策略
在解决Redis缓存与数据库双写一致性问题上,有多种策略和模式。我们主要介绍以下几种主要的策略:
Cache Aside Pattern(旁路缓存模式)
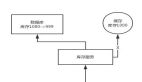
Cache Aside Pattern 是一种在分布式系统中广泛采用的缓存和数据库协同工作策略,在这个模式中,数据以数据库为主存储,缓存作为提升读取效率的辅助手段。也是日常中比较常见的一种手段。其工作流程如下:
 图片
图片
由上图我们可以看出Cache Aside Pattern的工作原理:
• 读取操作:首先尝试从缓存中获取数据,如果缓存命中,则直接返回;否则,从数据库中读取数据并将其放入缓存,最后返回给客户端。
• 更新操作:当需要更新数据时,首先更新数据库,然后再清除或使缓存中的对应数据失效。这样一来,后续的读请求将无法从缓存获取数据,从而迫使系统从数据库加载最新的数据并重新填充缓存。
我们从更新操作上看会发现两个很有意思的问题:
为什么操作缓存的时候是删除旧缓存而不是直接更新缓存?
我们举例模拟下并发环境下的更新DB&缓存:
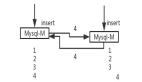
• 线程A先发起一个写操作,第一步先更新数据库,然后更新缓存
• 线程B再发起一个写操作,第二步更新了数据库,然后更新缓存 当以上两个线程的执行,如果严格先后顺序执行,那么对于更新缓存还是删除缓存去操作缓存都可以,但是如果两个线程同时执行时,由于网络或者其他原因,导致线程B先执行完更新缓存,然后线程A才会更新缓存。如下图:
 图片
图片
这时候缓存中保存的就是线程A的数据,而数据库中保存的是线程B的数据。这时候如果读取到的缓存就是脏数据。但是如果使用删除缓存取代更新缓存,那么就不会出现这个脏数据。这种方式可以简化并发控制、保证数据一致性、降低操作复杂度,并能更好地适应各种潜在的异常场景和缓存策略。尽管这种方法可能会增加一次数据库访问的成本,但在实际应用中,考虑到数据的一致性和系统的健壮性,这是值得付出的折衷。
并且在写多读少的情况下,数据很多时候并不会被读取到,但是一直被频繁的更新,这样也会浪费性能。实际上,写多的场景,用缓存也不是很划算。只有在读多写少的情况下使用缓存才会发挥更大的价值。
为什么是先操作数据库再操作缓存?
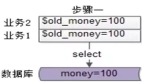
在操作缓存时,为什么要先操作数据库而不是先操作缓存?我们同样举例模拟两个线程,线程A写入数据,先删除缓存在更新DB,线程B读取数据。流程如下:
1. 线程A发起一个写操作,第一步删除缓存
2. 此时线程B发起一个读操作,缓存中没有,则继续读DB,读出来一个老数据
3. 然后线程B把老数据放入缓存中
4. 线程A更新DB数据
 图片
图片
所以这样就会出现缓存中存储的是旧数据,而数据库中存储的是新数据,这样就出现脏数据,所以我们一般都采取先操作数据库,在操作缓存。这样后续的读请求从数据库获取最新数据并重新填充缓存。这样的设计降低了数据不一致的风险,提升了系统的可靠性。同时,这也符合CAP定理中对于一致性(Consistency)和可用性(Availability)权衡的要求,在很多场景下,数据一致性被优先考虑。
Cache Aside Pattern相对简单直观,容易理解和实现。只需要简单的判断和缓存失效逻辑即可,对已有系统的改动较小。并且由于缓存是按需加载的,所以不会浪费宝贵的缓存空间存储未被访问的数据,同时我们可以根据实际情况决定何时加载和清理缓存。
尽管Cache Aside Pattern在大多数情况下可以保证最终一致性,但它并不能保证强一致性。在数据库更新后的短暂时间内(还未开始操作缓存),如果有读请求发生,缓存中仍是旧数据,但是实际数据库中已是最新数据,造成短暂的数据不一致。在并发环境下,特别是在更新操作时,有可能在更新数据库和删除缓存之间的时间窗口内,新的读请求加载了旧数据到缓存,导致不一致。
Read-Through/Write-Through(读写穿透)
Read-Through 和 Write-Through 是两种与缓存相关的策略,它们主要用于缓存系统与持久化存储之间的数据交互,旨在确保缓存与底层数据存储的一致性。
Read-Through(读穿透)
Read-Through 是一种在缓存中找不到数据时,自动从持久化存储中加载数据并回填到缓存中的策略。具体执行流程如下:
- • 客户端发起读请求到缓存系统。
- • 缓存系统检查是否存在请求的数据。
- • 如果数据不在缓存中,缓存系统会透明地向底层数据存储(如数据库)发起读请求。
- • 数据库返回数据后,缓存系统将数据存储到缓存中,并将数据返回给客户端。
- • 下次同样的读请求就可以直接从缓存中获取数据,提高了读取效率。
 图片
图片
整体简要流程类似Cache Aside Pattern,但在缓存未命中的情况下,Read-Through 策略会自动隐式地从数据库加载数据并填充到缓存中,而无需应用程序显式地进行数据库查询。
Cache Aside Pattern 更多地依赖于应用程序自己来管理缓存与数据库之间的数据流动,包括缓存填充、失效和更新。而Read-Through Pattern 则是在缓存系统内部实现了一个更加自动化的过程,使得应用程序无需关心数据是从缓存还是数据库中获取,以及如何保持两者的一致性。在Read-Through 中,缓存系统承担了更多的职责,实现了更紧密的缓存与数据库集成,从而简化了应用程序的设计和实现。
Write-Through(写穿透)
Write-Through 是一种在缓存中更新数据时,同时将更新操作同步到持久化存储的策略。具体流程如下:
• 当客户端向缓存系统发出写请求时,缓存系统首先更新缓存中的数据。
• 同时,缓存系统还会把这次更新操作同步到底层数据存储(如数据库)。
• 当数据在数据库中成功更新后,整个写操作才算完成。
• 这样,无论是从缓存还是直接从数据库读取,都能得到最新一致的数据。
 图片
图片
Read-Through 和 Write-Through 的共同目标是确保缓存与底层数据存储之间的一致性,并通过自动化的方式隐藏了缓存与持久化存储之间的交互细节,简化了客户端的处理逻辑。这两种策略经常一起使用,以提供无缝且一致的数据访问体验,特别适用于那些对数据一致性要求较高的应用场景。然而,需要注意的是,虽然它们有助于提高数据一致性,但在高并发或网络不稳定的情况下,仍然需要考虑并发控制和事务处理等问题,以防止数据不一致的情况发生。
Write behind (异步缓存写入)
Write Behind(异步缓存写入),也称为 Write Back(回写)或 异步更新策略,是一种在处理缓存与持久化存储(如数据库)之间数据同步时的策略。在这种模式下,当数据在缓存中被更新时,并非立即同步更新到数据库,而是将更新操作暂存起来,随后以异步的方式批量地将缓存中的更改写入持久化存储。其流程如下:
• 应用程序首先在缓存中执行数据更新操作,而不是直接更新数据库。
• 缓存系统会将此次更新操作记录下来,暂存于一个队列(如日志文件或内存队列)中,而不是立刻同步到数据库。
• 在后台有一个独立的进程或线程定期(或者当队列积累到一定大小时)从暂存队列中取出更新操作,然后批量地将这些更改写入数据库。
 图片
图片
使用 Write Behind 策略时,由于更新并非即时同步到数据库,所以在异步处理完成之前,如果缓存或系统出现故障,可能会丢失部分更新操作。并且对于高度敏感且要求强一致性的数据,Write Behind 策略并不适用,因为它无法提供严格的事务性和实时一致性保证。Write Behind 适用于那些可以容忍一定延迟的数据一致性场景,通过牺牲一定程度的一致性换取更高的系统性能和扩展性。
解决双写一致性问题的3种方案
以上我们主要讲解了解决双写一致性问题的主要策略,但是每种策略都有一定的局限性,所以我们在实际运用中,还要结合一些其他策略去屏蔽上述策略的缺点。
1. 延时双删策略
延时双删策略主要用于解决在高并发场景下,由于网络延迟、并发控制等原因造成的数据库与缓存数据不一致的问题。
当更新数据库时,首先删除对应的缓存项,以确保后续的读请求会从数据库加载最新数据。但是由于网络延迟或其他不确定性因素,删除缓存与数据库更新之间可能存在时间窗口,导致在这段时间内的读请求从数据库读取数据后写回缓存,新写入的缓存数据可能还未反映出数据库的最新变更。
所以为了解决这个问题,延时双删策略在第一次删除缓存后,设定一段短暂的延迟时间,如几百毫秒,然后在这段延迟时间结束后再次尝试删除缓存。这样做的目的是确保在数据库更新传播到所有节点,并且在缓存中的旧数据彻底过期失效之前,第二次删除操作可以消除缓存中可能存在的旧数据,从而提高数据一致性。
public class DelayDoubleDeleteService {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private TaskScheduler taskScheduler;
public void updateAndScheduleDoubleDelete(String key, String value) {
// 更新数据库...
updateDatabase(key, value);
// 删除缓存
redisTemplate.delete(key);
// 延迟执行第二次删除
taskScheduler.schedule(() -> {
redisTemplate.delete(key);
}, new CronTrigger("0/1 * * * * ?")); // 假设1秒后执行,实际应根据需求设置定时表达式
}
// 更新数据库的逻辑
private void updateDatabase(String key, String value) {
}
}这种方式可以较好地处理网络延迟导致的数据不一致问题,较少的并发写入数据库和缓存,降低系统的压力。但是,延迟时间的选择需要权衡,过短可能导致实际效果不明显,过长可能影响用户体验。并且对于极端并发场景,仍可能存在数据不一致的风险。
2. 删除缓存重试机制
删除缓存重试机制是在删除缓存操作失败时,设定一个重试策略,确保缓存最终能被正确删除,以维持与数据库的一致性。
在执行数据库更新操作后,尝试删除关联的缓存项。如果首次删除缓存失败(例如网络波动、缓存服务暂时不可用等情况),系统进入重试逻辑,按照预先设定的策略(如指数退避、固定间隔重试等)进行多次尝试。直到缓存删除成功,或者达到最大重试次数为止。通过这种方式,即使在异常情况下也能尽量保证缓存与数据库的一致性。
@Service
public class RetryableCacheService {
@Autowired
private CacheManager cacheManager;
@Retryable(maxAttempts = 3, backoff = @Backoff(delay = 1000L))
public void deleteCacheWithRetry(String key) {
((org.springframework.data.redis.cache.RedisCacheManager) cacheManager).getCache("myCache").evict(key);
}
public void updateAndDeleteCache(String key, String value) {
// 更新数据库...
updateDatabase(key, value);
// 尝试删除缓存,失败时自动重试
deleteCacheWithRetry(key);
}
// 更新数据库的逻辑,此处仅示意
private void updateDatabase(String key, String value) {
// ...
}
}这种重试方式确保缓存删除操作的成功执行,可以应对网络抖动等导致的临时性错误,提高数据一致性。但是可能占用额外的系统资源和时间,重试次数过多可能会阻塞其他操作。
监听并读取biglog异步删除缓存
在数据库发生写操作时,将变更记录在binlog或类似的事务日志中,然后使用一个专门的异步服务或者监听器订阅binlog的变化(比如Canal),一旦检测到有数据更新,便根据binlog中的操作信息定位到受影响的缓存项。讲这些需要更新缓存的数据发送到消息队列,消费者处理消息队列中的事件,异步地删除或更新缓存中的对应数据,确保缓存与数据库保持一致。
@Service
public class BinlogEventHandler {
@Autowired
private RocketMQTemplate rocketMQTemplate;
public void handleBinlogEvent(BinlogEvent binlogEvent) {
// 解析binlogEvent,获取需要更新缓存的key
String cacheKey = deriveCacheKeyFromBinlogEvent(binlogEvent);
// 发送到RocketMQ
rocketMQTemplate.asyncSend("cacheUpdateTopic", cacheKey, new SendCallback() {
@Override
public void onSuccess(SendResult sendResult) {
// 发送成功处理
}
@Override
public void onException(Throwable e) {
// 发送失败处理
}
});
}
// 从binlog事件中获取缓存key的逻辑,这里仅为示意
private String deriveCacheKeyFromBinlogEvent(BinlogEvent binlogEvent) {
// ...
}
}
@RocketMQMessageListener(consumerGroup = "myConsumerGroup", topic = "cacheUpdateTopic")
public class CacheUpdateConsumer {
@Autowired
private StringRedisTemplate redisTemplate;
@Override
public void onMessage(MessageExt messageExt) {
String cacheKey = new String(messageExt.getBody());
redisTemplate.delete(cacheKey);
}
}这种方法的好处是将缓存的更新操作与主业务流程解耦,避免阻塞主线程,同时还能处理数据库更新后由于网络问题或并发问题导致的缓存更新滞后情况。当然,实现这一策略相对复杂,需要对数据库的binlog机制有深入理解和定制开发。
总结
在分布式系统中,为了保证缓存与数据库双写一致性,可以采用以下方案:
1. 读取操作:
• 先尝试从缓存读取数据,若缓存命中,则直接返回缓存中的数据。
• 若缓存未命中,则从数据库读取数据,并将数据放入缓存。
2. 更新操作:
• 在更新数据时,首先在数据库进行写入操作,确保主数据库数据的即时更新。
• 为了减少数据不一致窗口,采用异步方式处理缓存更新,具体做法是监听数据库的binlog事件,异步进行删除缓存。
• 在一主多从的场景下,为了确保数据一致性,需要等待所有从库的binlog事件都被处理后才删除缓存(确保全部从库均已更新)。
同时,还需注意以下要点:
• 对于高并发环境,可能需要结合分布式锁、消息队列或缓存失效延时等技术,进一步确保并发写操作下的数据一致性。
• 异步处理binlog时,务必考虑异常处理机制和重试策略,确保binlog事件能够正确处理并执行缓存更新操作。