引言
之前遇到过 mysqldump 导致锁表,后来才发现 insert select 也会给源表加锁,具体加锁类型是 S 型 next-key lock。本文分析加锁现象与原因,并提供优化建议。
现象
时间:20231124 09:58
数据库版本:MySQL 5.7.24
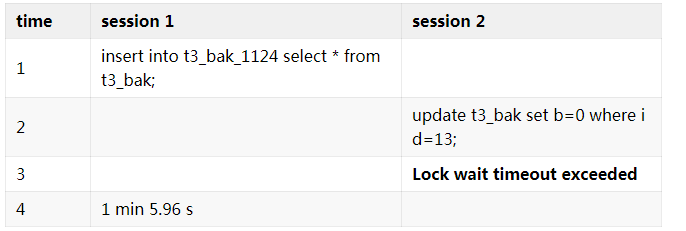
现象:insert select 备份表导致 update 锁等待
查看监控

其中:
- 锁等待显示每秒平均等待时间将近一小时
- 慢 SQL 显示 insert select 期间锁表,阻塞业务 update 语句
测试
测试准备
mysql> show create table t3_bak \G
*************************** 1. row ***************************
Table: t3_bak
Create Table: CREATE TABLE `t3_bak` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`a` int(10) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL,
`b` int(11) DEFAULT '0',
PRIMARY KEY (`id`),
KEY `idx_name_a` (`name`,`a`)
) ENGINE=InnoDB AUTO_INCREMENT=10000000 DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
mysql> select * from t3_bak limit 3;
+----+------+------+------+
| id | a | name | b |
+----+------+------+------+
| 11 | 11 | test | 0 |
| 12 | 12 | abc | 0 |
| 13 | 13 | test | 0 |
+----+------+------+------+
3 rows in set (0.00 sec)
mysql> create table t3_bak_1124 like t3_bak;
Query OK, 0 rows affected (0.02 sec)复现
操作流程,其中事务 1 备份全表,事务 2 update 其中一行数据。
时刻 2 查看锁信息

其中:
- information_schema.innodb_locks 表中记录锁等待相关信息,显示事务 1 持有主键 S 型 next-key lock,事务 2 申请同一行数据的 X 型 next-key lock,因此发生锁等待。
由于查询全表时加锁过多,为了查看事务 1 insert select 完整的锁信息,下面单独执行 insert select limit 语句。
SQL
mysql> insert into t3_bak_1124 select * from t3_bak limit 3;
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0查看锁等待信息

其中:
- 给 t3_bak 表中扫描的每行数据的主键索引加 S 型 next-key lock。
分析
执行流程
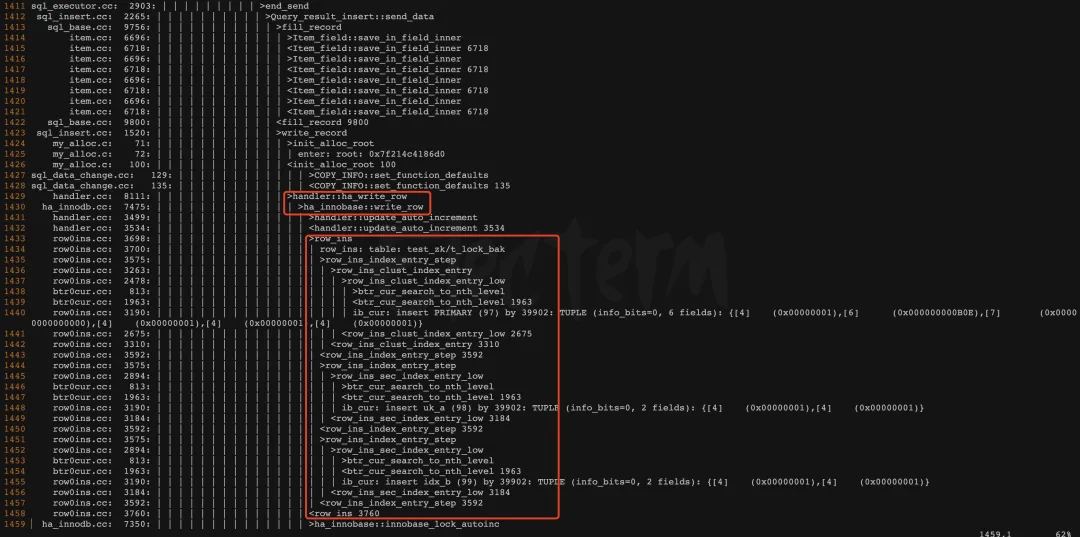
从 trace 中可以明确看到 insert select 的执行可以分两步:
- select
- insert
详见下图。
select

insert
加锁函数
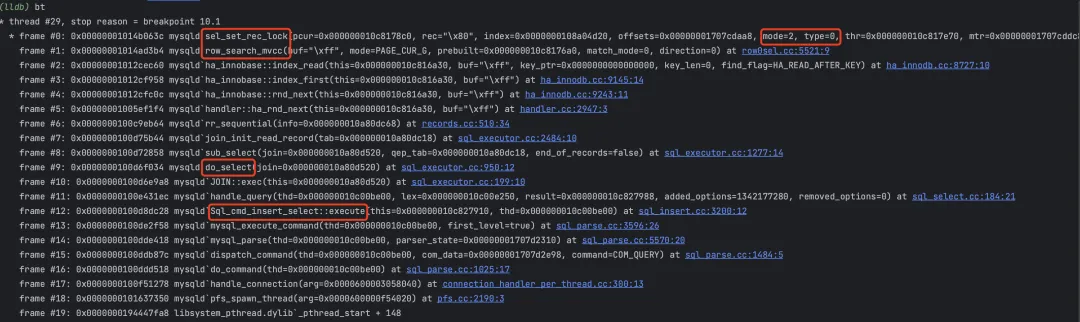
给 sel_set_rec_lock 函数设置断点,查看堆栈用于定位加锁操作。
其中:
- sel_set_rec_lock 函数入参 mode=2, type=0,表示 S 型 next-key lock;
- row_search_mvcc 调用 sel_set_rec_lock 函数加锁,因此给 row_search_mvcc 函数设置断点,堆栈如下所示。
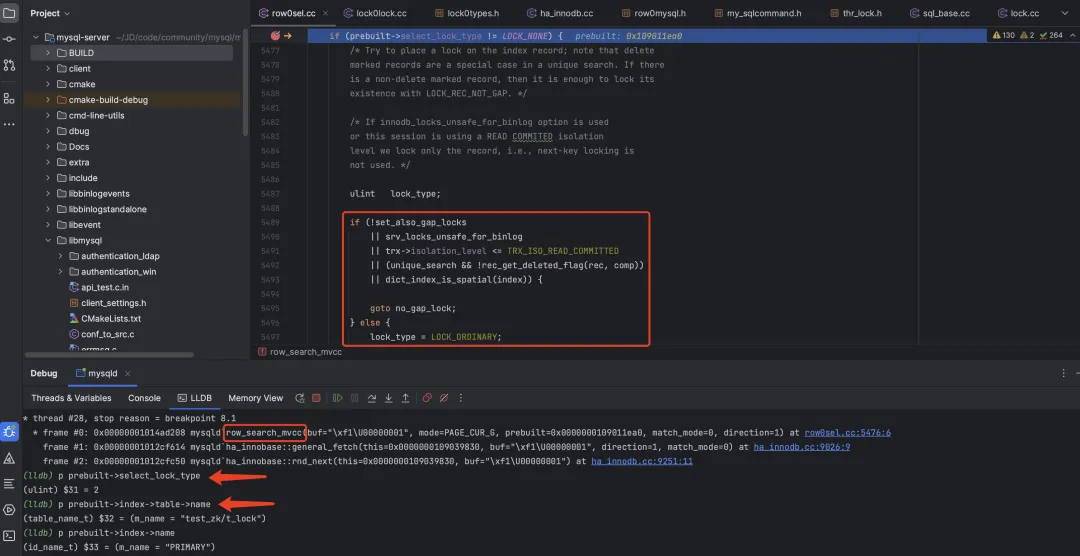
其中:
- row_search_mvcc 函数用于行记录加锁判断,相关代码如下所示,其中判断是否加 gap lock。
if (prebuilt->select_lock_type != LOCK_NONE) {
/* Try to place a lock on the index record; note that delete
marked records are a special case in a unique search. If there
is a non-delete marked record, then it is enough to lock its
existence with LOCK_REC_NOT_GAP. */
/* If innodb_locks_unsafe_for_binlog option is used
or this session is using a READ COMMITED isolation
level we lock only the record, i.e., next-key locking is
not used. */
ulint lock_type;
// 不加gap锁的场景
if (!set_also_gap_locks
|| srv_locks_unsafe_for_binlog
|| trx->isolation_level <= TRX_ISO_READ_COMMITTED
|| (unique_search && !rec_get_deleted_flag(rec, comp))
|| dict_index_is_spatial(index)) {
goto no_gap_lock;
} else {
lock_type = LOCK_ORDINARY;
}
}其中:
- 对于 RR,未开启 innodb_locks_unsafe_for_binlog 时,根据 prebuilt->select_lock_type 字段判断是否加 gap lock,如果为空,使用 record lock,否则使用 next-key lock;
- prebuilt->select_lock_type 表示加锁的类型,对应 lock_mode 枚举类型,常见取值包括:
- 5(LOCK_NONE),如普通 select 快照读;
- 2(LOCK_S),如 select lock in share mode 当前读禁止写;
- 3(LOCK_X),如 select for update 当前读禁止读写。
- 对于 insert select 语句,由于 prebuilt->select_lock_type = 2,因此加锁类型为 S 型 next-key lock。
如下所示,sel_set_rec_lock 函数中加锁时 lock_mode 同样使用 prebuilt->select_lock_type,个人判断行锁类型与表锁类型有关。
err = sel_set_rec_lock(pcur,
rec, index, offsets,
prebuilt->select_lock_type,
lock_type, thr, &mtr);因此重点在于 prebuilt->select_lock_type 字段的赋值操作,定位到对应堆栈如下所示。

其中:
- sql_command = 6 = SQLCOM_INSERT_SELECT,表示 insert select 语句;
- thr_lock_type = TL_WRITE_CONCURRENT_INSERT,对应表锁,表示允许在表的末尾进行插入操作,同时其他线程可以读取表中的数据;
- m_prebuilt->select_lock_type = LOCK_S,对应行锁,表示使用行共享锁。
ha_innobase::store_lock 函数中根据 lock_type 与 sql_command 判断需要是否加 S 锁,相关代码如下所示。
// storge/innobase/handler/ha_innodb.cc
/* Check for LOCK TABLE t1,...,tn WITH SHARED LOCKS */
// 首先根据 lock_type 判断
} else if ((lock_type == TL_READ && in_lock_tables)
|| (lock_type == TL_READ_HIGH_PRIORITY && in_lock_tables)
|| lock_type == TL_READ_WITH_SHARED_LOCKS
|| lock_type == TL_READ_NO_INSERT
|| (lock_type != TL_IGNORE
&& sql_command != SQLCOM_SELECT)) {
/* The OR cases above are in this order:
1) MySQL is doing LOCK TABLES ... READ LOCAL, or we
are processing a stored procedure or function, or
2) (we do not know when TL_READ_HIGH_PRIORITY is used), or
3) this is a SELECT ... IN SHARE MODE, or
4) we are doing a complex SQL statement like
INSERT INTO ... SELECT ... and the logical logging (MySQL
binlog) requires the use of a locking read, or
MySQL is doing LOCK TABLES ... READ.
5) we let InnoDB do locking reads for all SQL statements that
are not simple SELECTs; note that select_lock_type in this
case may get strengthened in ::external_lock() to LOCK_X.
Note that we MUST use a locking read in all data modifying
SQL statements, because otherwise the execution would not be
serializable, and also the results from the update could be
unexpected if an obsolete consistent read view would be
used. */
/* Use consistent read for checksum table */
// 然后根据 sql_command 判断
if (sql_command == SQLCOM_CHECKSUM
|| ((srv_locks_unsafe_for_binlog
|| trx->isolation_level <= TRX_ISO_READ_COMMITTED)
&& trx->isolation_level != TRX_ISO_SERIALIZABLE
&& (lock_type == TL_READ
|| lock_type == TL_READ_NO_INSERT)
&& (sql_command == SQLCOM_INSERT_SELECT // insert select 语句
|| sql_command == SQLCOM_REPLACE_SELECT
|| sql_command == SQLCOM_UPDATE
|| sql_command == SQLCOM_CREATE_TABLE))) {
/* If we either have innobase_locks_unsafe_for_binlog
option set or this session is using READ COMMITTED
isolation level and isolation level of the transaction
is not set to serializable and MySQL is doing
INSERT INTO...SELECT or REPLACE INTO...SELECT
or UPDATE ... = (SELECT ...) or CREATE ...
SELECT... without FOR UPDATE or IN SHARE
MODE in select, then we use consistent read
for select. */
m_prebuilt->select_lock_type = LOCK_NONE;
m_prebuilt->stored_select_lock_type = LOCK_NONE;
} else {
m_prebuilt->select_lock_type = LOCK_S;
m_prebuilt->stored_select_lock_type = LOCK_S;
}其中:
- 根据 lock_type 与 sql_command 判断,以下 SQL 可能需要加锁:
- LOCK TABLES ... READ LOCAL
- SELECT ... IN SHARE MODE
- INSERT INTO ... SELECT / REPLACE INTO...SELECT / CREATE ... SELECT
- 满足以下条件时不需要加锁,否则需要加 S 型锁:
1.事务隔离级别不是 SERIALIZABLE,并开启 innodb_locks_unsafe_for_binlog
2.事务隔离级别是 RC
前面提到两个枚举类型,下面展示定义。
首先是 enum_sql_command,表示 SQL 的类型,比如 insert select = 6 = SQLCOM_INSERT_SELECT。
enum enum_sql_command {
SQLCOM_SELECT,
SQLCOM_CREATE_TABLE,
SQLCOM_CREATE_INDEX,
SQLCOM_ALTER_TABLE,
SQLCOM_UPDATE,
SQLCOM_INSERT,
SQLCOM_INSERT_SELECT,
...
};然后是 lock_mode,表示加锁的模式,比如 insert select = 2 = LOCK_S。
/* Basic lock modes */
enum lock_mode {
LOCK_IS = 0, /* intention shared */
LOCK_IX, /* intention exclusive */
LOCK_S, /* shared */
LOCK_X, /* exclusive */
LOCK_AUTO_INC, /* locks the auto-inc counter of a table
in an exclusive mode */
LOCK_NONE, /* this is used elsewhere to note consistent read */
LOCK_NUM = LOCK_NONE, /* number of lock modes */
LOCK_NONE_UNSET = 255
};加锁原因
下面分析 insert select 语句加 S 型 next-key lock 的原因。
首先参考官方文档。
INSERT INTO T SELECT ... FROM S WHERE ... sets an exclusive index record lock (without a gap lock) on each row inserted into T. If the transaction isolation level is READ COMMITTED, or innodb_locks_unsafe_for_binlog is enabled and the transaction isolation level is not SERIALIZABLE, InnoDB does the search on S as a consistent read (no locks). Otherwise, InnoDB sets shared next-key locks on rows from S. InnoDB has to set locks in the latter case: During roll-forward recovery using a statement-based binary log, every SQL statement must be executed in exactly the same way it was done originally.
对于 insert t select s 语句,其中 t、s 分别表示表名。
执行过程中给 t 表加 record lock,具体是隐式锁,而给 s 表的加锁类型与事务隔离级别及参数配置有关:
- 如果事务隔离级别是 READ COMMITTED,不加锁;
- 如果事务隔离级别不是 SERIALIZABLE,并开启 innodb_locks_unsafe_for_binlog,不加锁;
- 如果事务隔离级别是 REPEATABLE-READ,加锁,类型是 S 型 next-key lock。
然后参考 MySQL 45 讲。
创建测试表
CREATE TABLE `t` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(null, 1,1);
insert into t values(null, 2,2);
insert into t values(null, 3,3);
insert into t values(null, 4,4);
create table t2 like t;在 RR 事务隔离级别下,binlog_format = statement 时执行以下语句时,为什么需要对 t 的所有行和间隙加锁呢?
insert into t2(c,d) select c,d from t;原因是需要保证日志与数据的一致性,否则将导致主从不一致。
假设 insert select 时 t 表存在并发 insert,其中假设 session B 先执行。

其中:
- 由于该 SQL 会给 t 表主键索引 (-∞, 1] 加 next-key lock,因此 session A 将阻塞直到 session B 执行完成;
- 如果不加锁,可能出现 session B 的 insert 先执行,后写入 binlog 的场景。在 binlog_format = statement 时,binlog 中的语句序列如下所示。
insert into t values(-1,-1,-1);
insert into t2(c,d) select c,d from t;因此从库执行时,会将 id=-1 的记录也写入 t2 表中,从而导致主从不一致。
参考 chatgpt,insert t select * from s 给 s 表加锁的原因如下所示,显示与 45 讲中一致。
在MySQL中,执行"insert ... select"语句时,会对选择的表S进行锁定以确保在整个选择和插入过程中的数据一致性。
理论上说,"insert ... select"操作包含两个步骤:第一步是从表S中选择数据;第二步是将选择的数据插入到目标表。在这两个步骤之间,如果表S的数据被其他事务或操作更改,那么从表S选择的数据可能就不再准确或一致,插入到目标表的数据也会出现问题。
因此,为了在整个选择和插入过程中保持数据的一致性,MySQL在执行"insert ... select"操作时会对表S进行锁定。这样在锁定期间,其他事务或操作就不能更改表S的数据,从而保证了数据的一致性。
参考文章 mysql- insert select带来的锁问题,由于复制的实现机制不同,针对 insert select 语句,oracle 中不需要锁定源表。
MySQL 中可以通过开启 innodb_locks_unsafe_for_binlog 来避免这个现象,显然可能导致主从不一致,因此不建议使用。
针对给源表加锁的问题,建议使用 select ... into outfile 和 load data file 的组合来代替 insert select 语句,从而避免操作期间锁表。
需要注意的是如果主从版本不一致,也有可能导致主从不一致,原因是不同版本的加锁规则不同。
官方文档显示 5.7 中 CREATE TABLE ... SELECT 语句与 INSERT ... SELECT 语句加锁规则相同,也就是给源表加锁。
CREATE TABLE ... SELECT ... performs the SELECT with shared next-key locks or as a consistent read, as for INSERT ... SELECT.
早期版本(个人理解比如 5.5,未验证)中不给源表加锁,因此假如主库是 5.5,从库是 5.6+,对于 binlog_format = statement,主库不加锁从库加锁,导致主从不一致。
针对该问题,有两种方案,使用 binlog_format = row 或将主库升级为 5.7。
MySQL 5.7 does not allow a CREATE TABLE ... SELECT statement to make any changes in tables other than the table that is created by the statement. Some older versions of MySQL permitted these statements to do so; this means that, when using replication between a MySQL 5.6 or later replica and a source running a previous version of MySQL, a CREATE TABLE ... SELECT statement causing changes in other tables on the source fails on the replica, causing replication to stop. To prevent this from happening, you should use row-based replication, rewrite the offending statement before running it on the source, or upgrade the source to MySQL 5.7. (If you choose to upgrade the source, keep in mind that such a CREATE TABLE ... SELECT statement fails following the upgrade unless it is rewritten to remove any side effects on other tables.)
执行计划
参考 MySQL 45 讲,对比以下三条语句的执行计划。

其中:
- SQL 1,insert select,执行计划显示有两条记录,且 ID 相同,正常情况下 ID 相同时从上往下执行,但是个人理解这里先执行第二条的 select,具体待定;
- SQL 2,insert select limit,执行计划显示 rows 没变化,原因是 limit 语句的执行计划中 rows 不准确;
- SQL 3,insert 循环写入,查询与写入是同一张表,extra 显示使用临时表。
下面分别测试验证。
首先是 insert select 全表,显示 Innodb_rows_read 值的变化与慢查询中的扫描行数相等,且等于表的大小。

然后是 insert select limit,显示 Innodb_rows_read 值的变化与慢查询中的扫描行数相等,且等于 3。

最后是 insert 循环写入,显示 Innodb_rows_read 值的变化与慢查询中的扫描行数不相等,后者是前者的两倍。

原因是 insert 循环写入的执行流程为:
- 创建临时表;
- 按照索引扫描 t 表,由于 limit 3,因此仅取前三行数据,Rows_examined = 3;
- 最后将临时表的数据全部插入 t 表,因此 Rows_examined 加 3,等于 6。
显然,insert select 相同表与不同表的主要区别是后者需要使用临时表,原因是如果读出来的数据直接写回原表,可能导致读取到新插入的记录,注意事务隔离级别为 RR 时,事务可以看到自己修改的数据。
注意这里的测试结果与 45 讲中不同,45 讲中 limit 失效, t 表全表扫描,limit 在从临时表插回原表时生效。
参考文章 关于MySQL insert into ... select 的锁情况,判断原因是 select 语句中使用主键排序与非主键排序时的加锁规则不同。其中:
- 使用主键排序,逐行锁定扫描的记录,limit 失效,临时表中写入 limit 数据;
- 非主键排序,一次性锁定全表的记录,limit 生效,临时表中写入全表数据。
如下所示,对比测试使用主键排序与非主键排序。

其中:
- 使用主键排序,执行成功,Rows_examined = 6;
- 使用非主键排序,执行失败,Rows_examined = 5190999,报错临时表打满。
因此,使用 insert select 时需要重点关注是否使用主键排序,减少扫描行数与加锁行数。
知识点
innodb_locks_unsafe_for_binlog
row_search_mvcc 函数中判断加锁类型时,如果开启 innodb_locks_unsafe_for_binlog 参数,只会对行加锁,而不会锁间隙。
innodb_locks_unsafe_for_binlog 参数用于控制查询与索引扫描时是否使用 gap lock。默认 0,表示使用 gap lock。
RR 开启 innodb_locks_unsafe_for_binlog 参数时相当于退化为 RC,但有两点不同:
- innodb_locks_unsafe_for_binlog 是全局参数,不支持 session 级别配置;
- innodb_locks_unsafe_for_binlog 是静态参数,不支持动态修改。
开启 innodb_locks_unsafe_for_binlog 时,将导致幻读,原因是间隙没有加锁,因此其他事务可以插入。
注意与 RC 相同,开启 innodb_locks_unsafe_for_binlog 参数时,外键冲突检测与唯一性检查时依然需要使用 gap lock。
Enabling innodb_locks_unsafe_for_binlog does not disable the use of gap locking for foreign-key constraint checking or duplicate-key checking.
除了影响查询语句的加锁规则,开启 innodb_locks_unsafe_for_binlog 参数时也会影响更新操作,具体规则为:
- 对于 update / delete 语句,提前释放不满足 where 条件的记录上的锁,优点是可以减少锁冲突,缺点是违背两阶段加锁协议;
- 对于 update 语句,如果发现行记录被锁定,使用半一致性读(semi-consistent read),具体是先不发生锁等待,而是先返回最新已提交的数据,然后判断是否满足条件,如果不满足条件,就不需要加锁,否则发生锁等待。因此 semi-consistent read 是 read committed 与 consistent read 两者的结合。
由于开启 innodb_locks_unsafe_for_binlog 参数时可能导致主从数据不一致,因此官方不建议使用,8.0.0 中已删除该参数,如果需要使用,建议使用 RC。
那么,针对 insert select,RC 中会存在数据不一致的问题吗?
实际上不会,原因是 RC 不支持 binlog_format=statement。具体操作中 RC 虽然可以将 binlog_format 修改为 statement,但是写入时报错。

参考官方文档,RC 中 binlog_format 仅支持 ROW 格式。
Only row-based binary logging is supported with the READ COMMITTED isolation level. If you use READ COMMITTED with binlog_format=MIXED, the server automatically uses row-based logging.
thr_lock_type
thr_lock_type 是表锁的一种类型,从名称判断是多线程锁数据结构。
尽管 MySQL 对外展示出现的只有读锁与写锁两种类型,但实际上内部枚举类型中定义了 14 种多线程锁类型,详见下表。
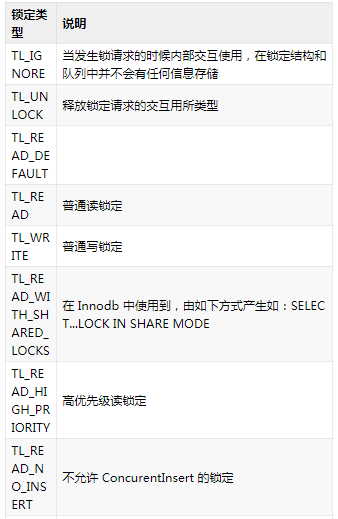

其中:
- select lock in share mode 对应 TL_READ_WITH_SHARED_LOCKS;
- insert select 对应 TL_WRITE_CONCURRENT_INSERT,表示允许在表的末尾进行插入操作,同时其他线程可以读取表中的数据。
具体不同类型的区别还不太清楚,待后续分析。
LOCK_AUTO_INC
前面关注的都是 insert select 中给源表的加锁规则,其实目标表的加锁规则也需要关注,比如自增锁 LOCK_AUTO_INC。
LOCK_AUTO_INC 也是表锁的一种类型,用于给自增计数器加锁,从而保证自增列(AUTO_INCREMENT)值的唯一性与连续性。
自增锁的锁定范围是 SQL 级别,但是锁的释放时间与自增锁模式有关,通过参数innodb_autoinc_lock_mode控制。
取值包括:
- 0,传统加锁模式(traditional),用于兼容 5.1 版本引入该参数之前的策略,具体是所有 insert 类型的语句,都在 SQL 执行结束时释放表级锁,因此对于 binlog_format=statement,可以保证主从数据的一致性;
- 1,连续加锁模式(consecutive),5.7 中的默认值,普通 insert 与批量 insert 的释放时间不同。具体为:
- 普通 insert,由于可以提前确定插入行数,因此可以在分配自增值后立即释放锁,使用 mutex (a light-weight lock);
- 批量 insert,由于无法提前确定插入行数,因此依然需要在 SQL 执行结束后释放锁,使用 table-level AUTO-INC lock。
“bulk inserts” use the special AUTO-INC table-level lock and hold it until the end of the statement. This applies to all INSERT ... SELECT, REPLACE ... SELECT, and LOAD DATA statements.
- 2,交叉加锁模式(interleaved),进一步放宽加锁模式,所有 insert 类型的语句,都在分配后立即释放锁,优点是允许批量插入,缺点是存在以下两个问题:
- 对于 binlog_format = statement,可能导致主从数据不一致;
- 对于批量插入语句,有可能多条语句交叉分配自增值,因此可能不连续。
LOCK_AUTO_INC 加锁函数是 ha_innobase::innobase_lock_autoinc,实现逻辑见下图,其中通过加锁模式与 SQL 类型选择加锁实现。

从 trace 中也可以看到,ha_innobase::write_row 函数中 row_ins 函数开始前后分别调用函数 handler::update_auto_increment 与 ha_innobase::innobase_lock_autoinc。

代码注释显示 ha_innobase::write_row 函数中在插入开始前获取当前自增值,并在插入结束后更新当前自增值。
// storge/innobase/handler/ha_innodb.cc
/* Step-3: Handling of Auto-Increment Columns. */
// 内部调用 ha_innobase::innobase_lock_autoinc 函数
update_auto_increment()
/* Step-4: Prepare INSERT graph that will be executed for actual INSERT
(This is a one time operation) */
/* Build the template used in converting quickly between
the two database formats */
build_template(true);
/* Step-5: Execute insert graph that will result in actual insert. */
// 内部调用 row_ins 函数
error = row_insert_for_mysql((byte*) record, m_prebuilt);
/* Step-6: Handling of errors related to auto-increment. */
auto_inc = innobase_next_autoinc(
auto_inc,
1, increment, offset,
col_max_value);
// 内部调用 ha_innobase::innobase_lock_autoinc 函数
err = innobase_set_max_autoinc(
auto_inc);结论
insert select 语句的执行分两步,先 select 后 insert,其中 select 阶段需要给源表加 S 型 next-key lock。
原因是数据查询阶段中判断加锁类型时:
- 判断 prebuilt->select_lock_type 是否为空,如果是,不加锁,表示快照读,否则继续判断;
- 判断事务隔离级别与 innodb_locks_unsafe_for_binlog,如果 RC 或开启 innodb_locks_unsafe_for_binlog,不加锁,同样使用快照读,否则加 next-key lock。
其中 prebuilt->select_lock_type 对应 thr_lock_type,表示表锁的类型,其中对于 insert select,对应 S 型锁。
而在行锁加锁时 lock_mode 同样使用 prebuilt->select_lock_type,个人判断行锁类型与表锁类型有关。
关于加锁类型,有两个参数需要关注:
- innodb_locks_unsafe_for_binlog 参数控制查询源表时是否使用间隙锁,RR 开启该参数时相当于 RC。对于 update 语句,使用半一致性读(semi-consistent read),semi-consistent read 是 read committed 与 consistent read 两者的结合;
- LOCK_AUTO_INC 参数控制目标表中自增锁的加锁模式,实际上是自增锁的释放时间,默认 1,对于批量插入的场景,由于无法提前确定插入行数,因此需要在 SQL 执行结束后释放锁,否则可以在分配自增值后立即释放。
insert select 给源表加锁的原因是保证日志与数据的一致性,否则 binlog_format = statement 时可能导致主从数据不一致。
针对 insert select 给源表加锁的问题,有以下几个优化建议:
- RR 中开启 innodb_locks_unsafe_for_binlog,但是 binlog_format = statement 时可能导致主从数据不一致,因此不建议使用;
- 使用 RC,RC 中 binlog_format 仅支持 ROW 格式,因此不会导致主从不一致;
- 使用 select ... into outfile 和 load data file 的组合来代替 insert select 语句。
即使使用 insert select,也需要注意以下两点:
- 是否使用主键排序,如果使用非主键排序,可能导致全表扫描与直接锁表;
- 如果主从数据库版本不一致,依然可能导致主从不一致,原因是早期版本中不加锁,5.6+ 中加锁。
待办
- thr_lock_type