













一条磁力链,Mistral AI又来闷声不响搞事情。
281.24GB文件中,竟是全新8x22B MOE模型!

全新MoE模型共有56层,48个注意力头,8名专家,2名活跃专家。
而且,上下文长度为65k。

网友纷纷表示,Mistral AI一如既往靠一条磁力链,掀起了AI社区热潮。

对此,贾扬清也表示,自己已经迫不及待想看到它和其他SOTA模型的详细对比了!

靠磁力链火遍整个AI社区
去年12月,首个磁力链发布后,Mistral AI公开的8x7B的MoE模型收获了不少好评。
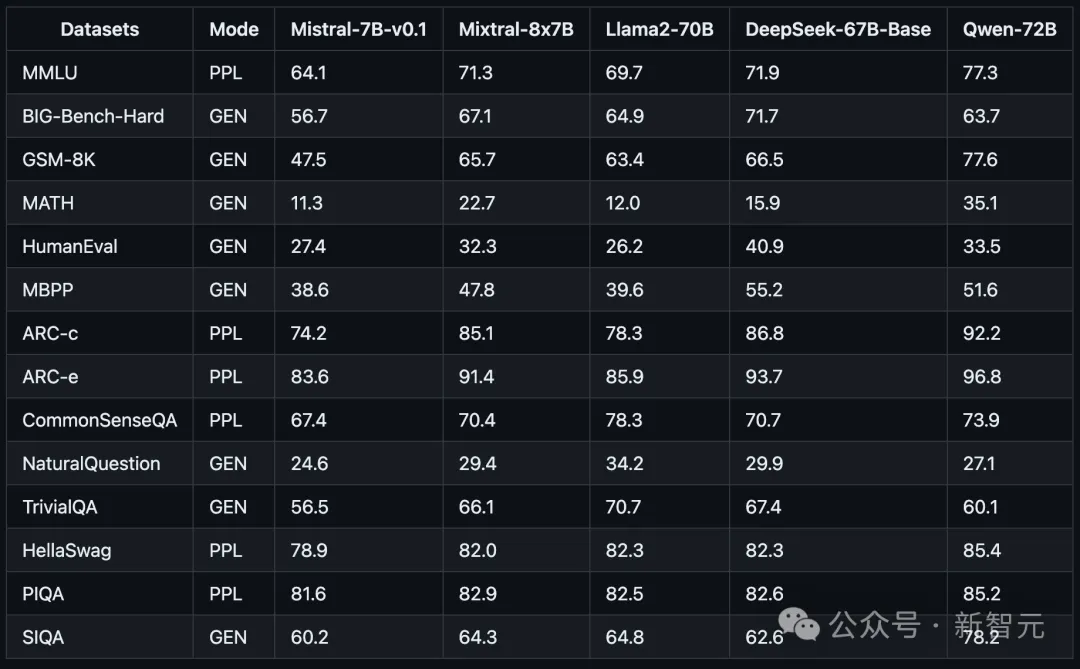
基准测试中,8个70亿参数的小模型性能超越了多达700亿参数的Llama 2。
它可以很好地处理32k长度的上下文,支持英语、法语、意大利语、德语和西班牙语,且在代码生成方面表现出强大的性能。
今年2月,最新旗舰版模型Mistral Large问世,性能直接对标GPT-4。
不过,这个版本的模型没有开源。
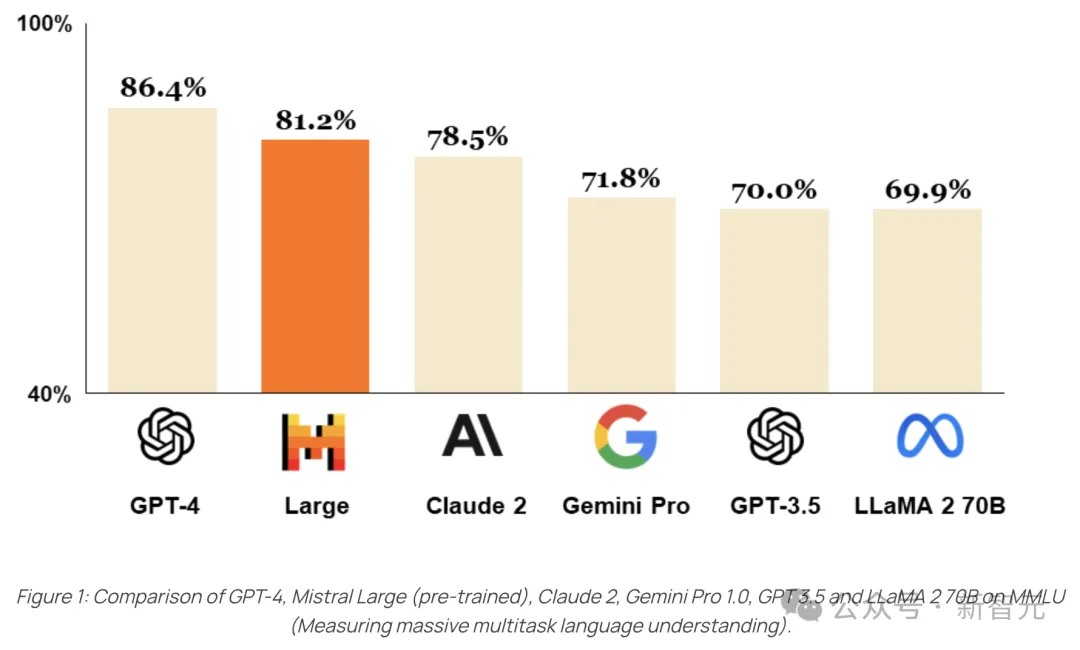
Mistral Large具备卓越的逻辑推理能力,能够处理包括文本理解、转换以及代码生成在内的复杂多语言任务。
也就是半个月前,在一个Cerebral Valley黑客松活动上,Mistral AI开源了Mistral 7B v0.2基础模型。
这个模型支持32k上下文,没有滑动窗口,Rope Theta = 1e6。

现在,最新的8x22B MoE模型也在抱抱脸平台上上线,社区成员可以基于此构建自己应用。





























