我们遇到的任何软件系统很可能都过于复杂,一次无法完全理解 — 人类的思维无法理解大量实体及其关系。我们倾向于通过建立抽象来简化现实:一旦我们将许多闪亮的金属、玻璃和橡胶定义为“汽车”,我们就可以谈论“高速公路”、“停车场”和“乘客” — 我们生活在我们创造的抽象世界中。同样,我们编写的软件由服务、进程、文件、类、过程等组成 — 这些模块隐藏了我们无法抗拒的一堆位和片段。让我们思考一下。

概念与复杂性
任何系统都包括 概念 — 以其他概念为基础定义的概念。例如,如果你正在实现一个电话簿,你会处理 名 和 姓、号码、排序 和 搜索,这些概念是任何与电话簿相关的开发任务中必须牢记的 — 只因为电话簿的需求是用这些概念及其关系描述的。
在代码中,高级概念被体现为服务、模块或目录,而较低级的概念则对应于类、API 方法或源文件。
概念很重要,因为它们的数量(或相应类和方法的数量)定义了系统的 复杂性 — 开发人员面对的认知负荷。如果程序员详细了解他们正在处理的组件的行为,他们往往会变得极其高效,并且通常能够为看似复杂的任务找到简单的解决方案。否则,开发速度会很慢,并且需要进行大量测试,因为人们不确定他们的更改会如何影响系统的行为。
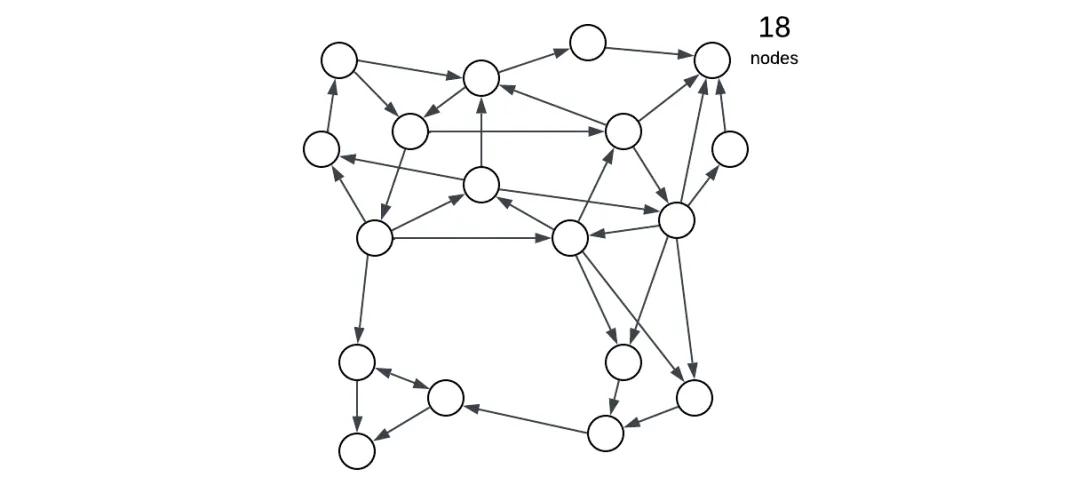
图1:复杂性与实体数量相关
模块、封装和有界上下文
让我们回到我们的例子。当你实现电话簿时,你会发现排序和搜索比你最初想象的要复杂得多。一旦你准备进入国际市场,你就会陷入深深的困境。一些电话服务提供商发送7位数字,其他人使用10位数字,还有些人使用13位数字(第一个字符为“+”或“0”)。德语有“ß”,它与“ss”相同,而日语同时使用两种字母表。一旦你开始阅读标准,实现所有奇怪的行为并回应用户投诉,你会感到你的电话簿实现淹没在充满特殊情况的外语字母表的无关逻辑中。你需要 封装。
引入 模块。模块封装了几个概念,有效地将它们隐藏在外部用户之外,并暴露了其内容的简化视图。引入模块将复杂的系统分成了几个通常更简单的部分。
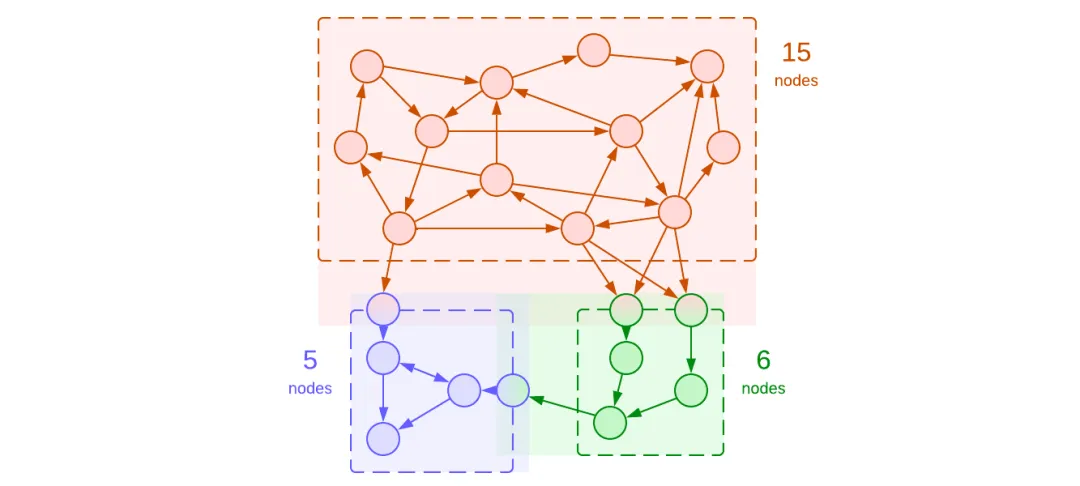
图2:将系统划分为模块,突出显示有界上下文
该图有几个值得注意的地方:
- 模块为其 公共API 创建了新的概念。
- API 入口点增加了 拥有者模块 和其客户的复杂性。
- 系统中的概念总数已增加(从18个到22个),但系统中最高复杂度已下降(从18到15)。
在这里,我们看到引入模块如何将分而治之的方法应用于减少在系统的任何部分上工作时的认知负荷,以较小的总工作量为代价。
在我们的电话簿示例中,与地区相关的字符串比较和联系人姓名的字母排序的特殊性(包括大小写敏感性)应该更好地保留在一个简单的字符串比较接口之后,以解除电话簿引擎程序员对支持外语的复杂性的负担。
模块代表 有界上下文 [DDD] — 系统知识的领域,这些领域操作不同的术语集。对于电话簿来说,整理 和 大小写敏感性 对于电话簿引擎并不重要 — 它们只在语言支持的上下文中定义。另一方面,通过号码匹配联系人 在语言支持模块中并未定义 — 该术语仅存在于电话簿引擎中。程序员所面临的是当前有界上下文的复杂性。
除了将问题分解为较简单的子问题外,模块还带来了一些额外的好处:
- 代码重用。一个良好编写的模块可以在多个项目中使用。
- 劳动分工。一旦系统被拆分为模块,并且每个模块都被分配给一个程序员,开发就会被高效地并行化。
- 高级概念。有些情况允许将原始问题的几个概念合并为更高级的聚合,进一步降低复杂性:
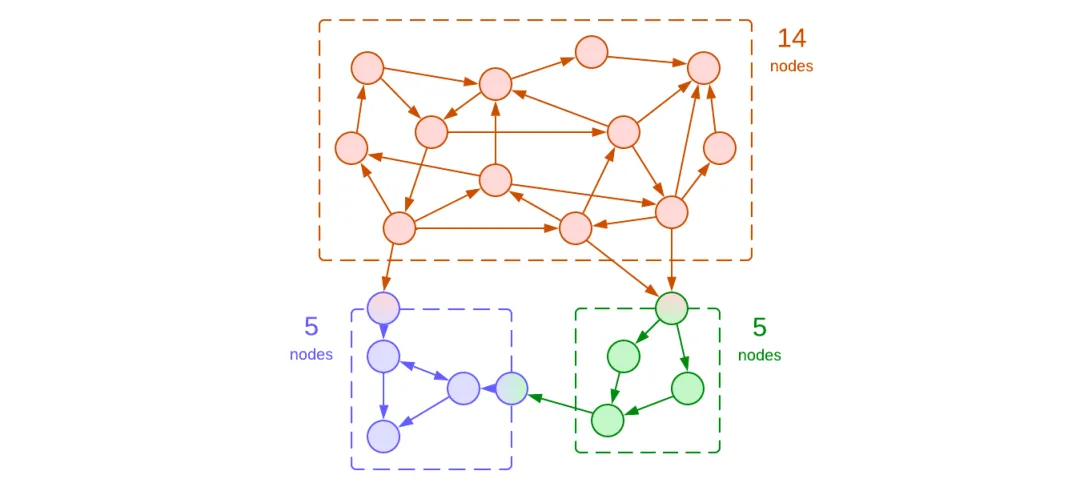
图3:合并了绿色模块的两个API概念
例如,电话簿的原始定义包含 名 和 姓。一旦我们将语言支持分离到一个专用模块中,我们可能会发现各种地区在表示联系人时有所不同:一些(美国)使用“名 + 姓”,而其他一些(日本)则需要“姓 + 名”。如果我们想要摆脱这个细节,我们应该使用一个新的 全名 概念,它以特定于区域的方式连接名和姓。这样的改变实际上简化了电话簿的某些表示逻辑和代码,因为它用一个概念替换了两个概念。
耦合度和内聚性
为了有效使用模块,我们需要学习一些新的概念:
- 耦合度 是模块之间连接数量(密度)的度量,相对于模块的大小。
- 内聚性 是模块内连接数量(密度)的度量,相对于模块的大小。
经验法则是要追求 低耦合和高内聚,这意味着每个模块应该封装一组相关(密切交互)的概念。这就是我们在图2和图3中将系统划分为的方式。现在让我们看看如果我们违反规则会发生什么:
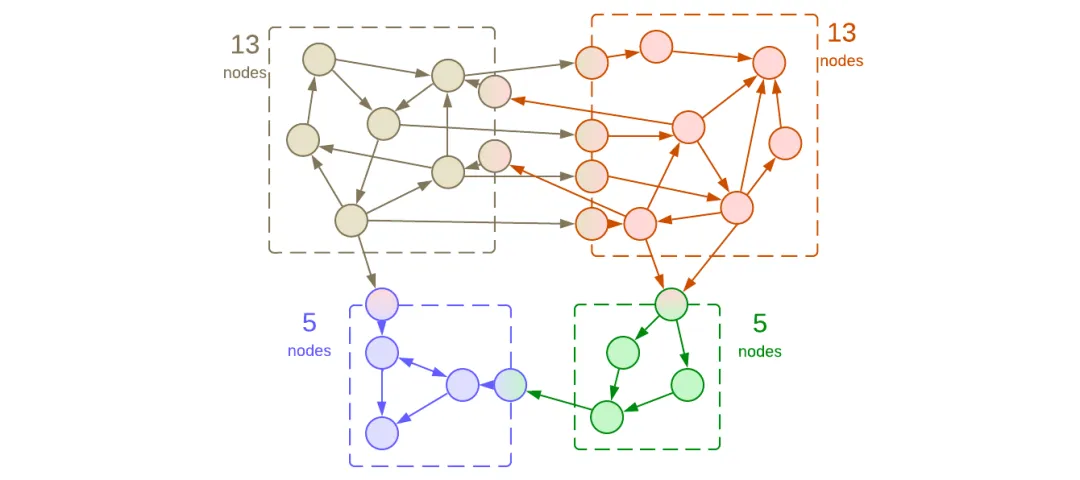
图4:上部模块耦合度高
拆分一个内聚模块(一组相互交互的概念),会产生两个强耦合的模块。这正是我们想要的,只是每个新模块几乎与原始模块一样复杂。也就是说,我们现在面临两个艰巨的任务,而不是一个。此外,系统的性能可能很差,因为模块之间的通信很少是最佳的,而我们却有太多这样的通信。
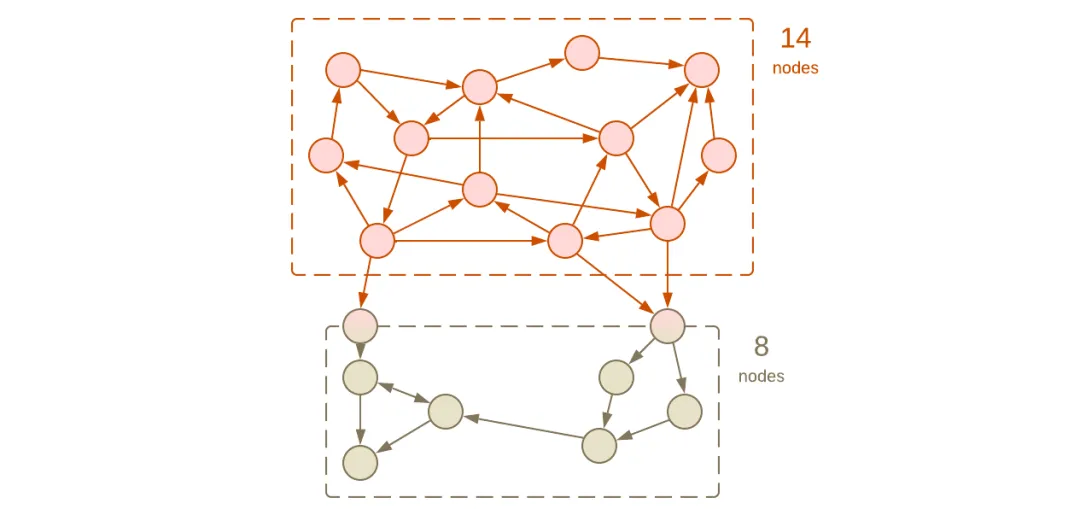
图5:下部模块内聚性低
如果我们将几个概念集聚在同一个模块中会发生什么?对于小模块来说,不会发生什么太糟糕的事 — 模块的复杂性高于其各个部分,但低于它们的总和。实际上,多个无关的函数通常被收集到一个‘utils’或‘tools’文件或目录中,以减轻 操作复杂性。
开发与操作复杂性
我们上面讨论的是 结构性 或 开发复杂性 —— 有界上下文内部的概念和规则的数量。然而,我们还需要理解系统作为一个整体的操作和组件,从而导致 操作 或 集成复杂性:
- 这个新需求是否适合现有模块,还是需要一个专用模块?
- 我们使用了哪些存在已知安全漏洞的库?
- 有没有办法减少我们的云服务成本?
- 1% 的请求超时了。你能调查一下吗?
- 我的团队需要实现这个和那个。我们有适合重用的东西吗?
- 那个全局变量到底是干什么的?
- 我们真的需要将这段代码投入生产吗?
- 我需要稍微改变一下那个共享组件的行为。有什么意见吗?
当部署了数百或数千个模块时,没有人知道答案。这类似于需要在 Linux 下执行某些操作的情况:已预安装了数百个工具,数千个其他工具则作为软件包可用,但唯一的前进方式是首先在搜索引擎中搜索您的需求,然后尝试搜索结果中的两三种方法,看哪种适合您的设置。不幸的是,谷歌并不索引您公司的代码。
模块的组合
一个模块不仅可以封装单个概念,还可以封装其他模块。这并不奇怪,因为 OOP 类是一种模块 — 它具有公共方法和私有成员。将一个模块隐藏在另一个模块中会将其从全局范围中删除,减少了系统的操作复杂性 — 现在不再是系统的架构师,而是外部模块的维护者必须记住内部模块。一方面,在组织和代码中建立了可管理的层次结构。另一方面,代码重用和许多优化几乎不可能实现,因为内部模块在整个组织中几乎不为人知:
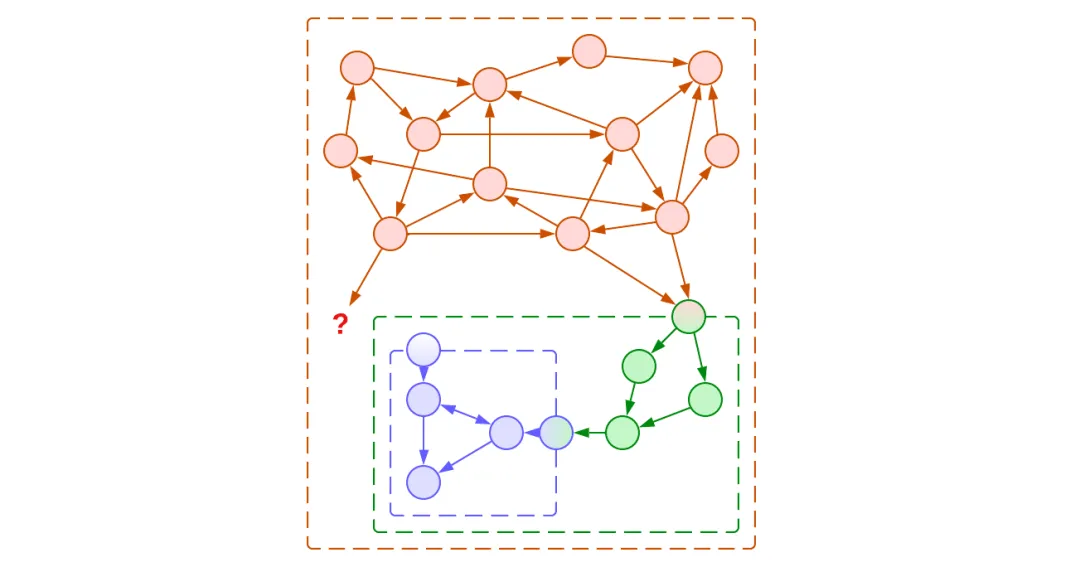
图6:模块的组合阻止了重用
如果我们的内部模块的功能被我们的客户需要,我们有两个不好的选择:
转发和重复
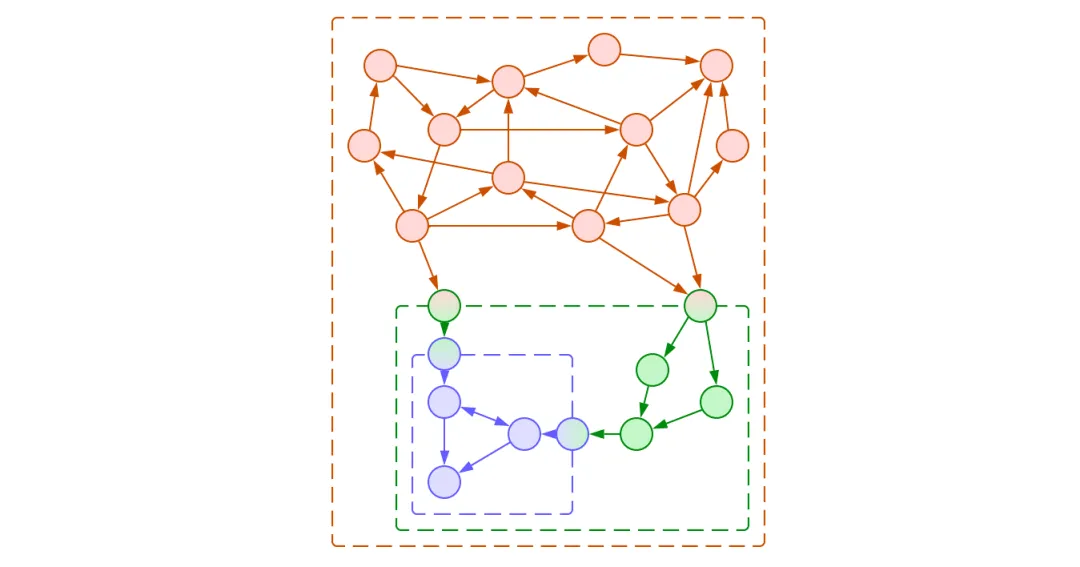
图7:转发内部模块的API
我们可以将我们封装的模块的API添加到我们的公共API中,并将其调用转发到内部模块。然而,这会增加我们模块的复杂性,并降低我们模块的内聚性 — 现在我们模块的每个客户都暴露于我们封装的模块的方法的细节中,即使他们并不打算使用它。
图8:重复内部模块
另一个不好的选择是让需要我们封装的模块的客户复制它并拥有副本作为自己的子模块。这使我们摆脱了任何共同的责任,让我们可以任意修改和误用我们的内部,并违反了常识的一对 规则。
这两种方法,即将所有模块保留在全局范围内和通过组合封装实用模块,都在历史上找到了它们的位置[FSA]。面向服务的架构 基于重用的想法,但却成了其 企业服务总线 的复杂性的牺牲品,该总线必须考虑系统中的所有交互(API 方法)。作为反应,微服务 方法把潮流转向了相反的方向:其支持者不允许在服务之间共享任何资源或代码,以确保它们的解耦。