














随着互联网上各种 UGC 越来越多,各种原创性的长文本内容也不断地涌现出来。例如,在人工智能领域的三大顶会之一的 ICML,许多论文的长度都达到了二三十页。因此,如何快速的从长文本中提取出有用的信息,成为困扰许多包括科研人员在内的互联网网民的难题。
在 2012 年结束的人工智能领域顶会 AAAI 2012 上,来自中国浙江大学的研究团队,发表了一篇题为 Document Summarization Based on Data Reconstruction 的论文。该篇论文提出了 DSDR 算法,描述了如何利用贪心算法进行文本摘要提取的方法。论文下载地址在这里:Document Summarization Based on Data Reconstruction (nju.edu.cn)。下面我们介绍一下他们的方法。
所谓的文本自动摘要问题,本质上就是从原始的长文本中抽取一个文本的子集合,使得利用这个子集合的线性组合能尽可能的恢复出原始文本。我们按照如下方式定义文本自动摘要问题:
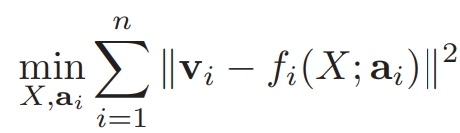
其中, f 是线性组合摘要句子之后的转换函数。X 是摘要生成的句子,a 是线性组合的系数,而 v 是原始文本,也就是输入数据。
首先,f 可以是线性组合,也就是:
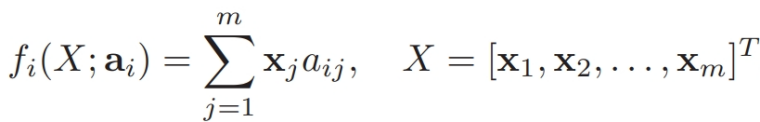
因此,文本自动摘要问题转换成为了下述问题:
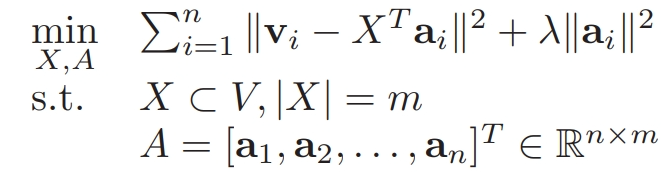
上述损失函数公式,等价于下面的公式:
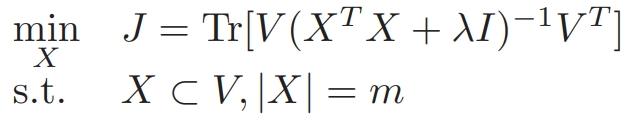
利用贪心算法,我们设计了如下损失函数:
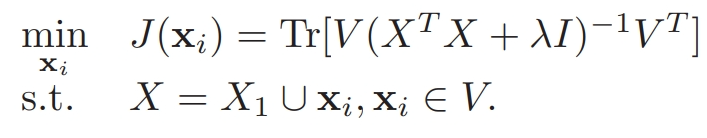
整个算法的伪代码流程如下所示:

在上面介绍的算法中,线性组合的系数 a 有可能是负数,为了保证 a 非负,我们重构了算法的损失函数:
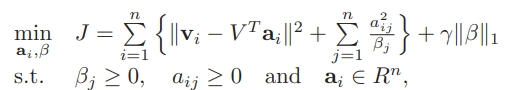
经过重新设计之后,算法的伪代码如下:

通过对比实验,我们发现新设计的算法,取得了优异的实验结果:
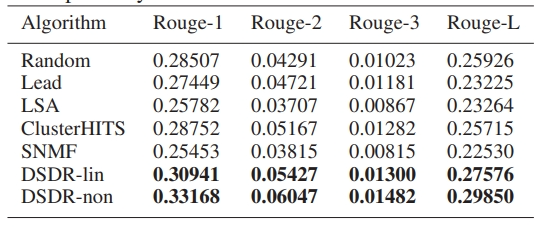
文本自动摘要,对于阅读长篇幅的文本,比如博士毕业论文、咨询报告、审计报告等内容,非常有帮助。对于赶时间的当代人来说,文本自动摘要无疑是随身办公的文书利器。希望通过本文,广大的互联网从业者能够有所收获。
作者介绍
汪昊,前 Funplus 人工智能实验室负责人。曾在 ThoughtWorks, 豆瓣,百度,新浪,网易等公司有超过 13 年的技术研发和技术高管经验。先后在科技公司上线过 10 余款成功的商业产品。担任过创业公司的 CTO和技术副总裁。精通数据挖掘、计算机图形学和数字博物馆领域的技术、技术管理和技术变现等内容。在国际学术会议和期刊如 IEEE TVCG 和 IEEE / ACM ASONAM 上发表论文 39 篇,获得最佳论文奖 1 次(IEEE SMI 2008)和最佳论文报告奖 4 次(ICBDT 2020 / IEEE ICISCAE 2021 / AIBT 2023 / ICSIM 2024)。























