













译者 | 布加迪
审校 | 重楼
速度对于Coralogix而言很重要,这是一个开发团队信任的可观测性平台,可以及时发现问题。Coralogix使用了实时流分析管道,提供了监控、可视化和警报等功能,无需索引。
Coralogix主要的差异化优势之一是分布式查询引擎,可以快速查询远程存储的客户归档中的映射数据。该引擎使用特殊的Parquet格式查询存储在对象存储(Google Cloud Storage或S3)中的半结构化数据。它最初是底层对象存储上的无状态查询引擎,但是在查询执行期间读取Parquet元数据带来了不可接受的延迟影响。为了克服这个问题,团队开发了一个元数据存储(简称为“Metastore”),以便更快地检索和处理执行大型查询所需的Parquet元数据。
最初的Metastore实现建立在PostgreSQL之上,速度不够快,无法满足该公司的需求。因此,团队尝试了一种新的实现:这次使用ScyllaDB,尝试取得了成功。团队取得了显著的性能提升——查询处理时间从30秒缩短到86毫秒。不妨深入了解一下他们是如何做到这一点的,并了解一下他们计划如何使用WebAssembly用户定义函数(UDF)和Rust进一步优化它。
Metastore动机和需求
在讨论Metastore实现细节之前,不妨先介绍一下当初构建Metastore的理由。
Coralogix的首席软件工程师Dan Harris解释道:“我们最初将这个平台设计为底层对象存储之上的无状态查询引擎,但我们很快意识到,查询执行期间读取Parquet元数据的成本占查询时间的很大一部分。”他们意识到,可以通过将Parquet元数据放在一个可以快速查询的快速存储系统中(而不是直接从底层对象存储读取和处理Parquet元数据),加快速度。
他们设想的解决方案具有以下功能:
- 以分解格式存储Parquet元数据,从而获得高扩展性和高吞吐量。
- 使用布隆过滤器,有效地识别每个查询要扫描的文件。
- 使用事务提交日志以事务性方式添加、更新和替换底层对象存储中的现有数据。
关键需求包括低延迟、读/写容量方面的可扩展性以及底层存储的可扩展性。为了理解所需的极端可扩展性,请考虑这种情况:单单一个客户每小时生成2000个Parquet文件(每天50000个),总计每天15TB,因此单单一天仅Parquet元数据就有20GB。
最初的PostgreSQL实现
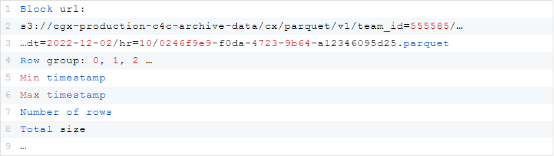
Harris承认:“我们在Postgres上开始了最初的实现,当时我们明白从长远来看,非分布式引擎是不够的。”最初的实现存储诸如块(block)之类的关键信息,表示一行组和一个Parquet文件。这包括元数据,比如文件的URL、行组索引和关于文件的少量细节。比如说:
为了优化读取操作,他们使用了布隆过滤器进行高效的数据修剪。Harris解释道:“最终,我们希望支持全文搜索之类的操作。大致来说,当我们将这些文件摄取到系统中时,可以为我们在文件中找到的所有不同的令牌构建一个布隆过滤器。然后,根据特定的查询,我们可以使用这些布隆过滤器来修剪我们需要扫描的数据。”
他们将布隆过滤器存储在块分割的环境中,将它们分成32字节大小的块,以便高效检索。它们独立存储,因此系统不必在查询时读取整个布隆过滤器。

此外,它们为每个Parquet文件存储列元数据。比如说:

Harris解释:“我们写入的文件内容相当宽,有时多达2万列。因此,如果只读取我们需要的元数据,就可以真正减少任何特定查询所需的IO数量。”
ScyllaDB实现
接下来,不妨看看由Harris的同事、Coralogix的高级软件工程师Sebastian Vercruysse概述的ScyllaDB实现。
块数据建模
为了新的实现,必须重新考虑块建模。这里有一个块URL的例子:s3://cgx-production-c4c-archive-data/cx/parquet/v1/team_id=555585/…
…dt = 2022-12-02 / hr = 10/0246f9e9-f0da-4723-9b64 a12346095d25.parquet
粗体部分是客户的顶层存储桶;在存储桶内,各项按小时划分。在这种情况下,应该使用什么作为主键?
- (表url)?但有些客户比其他客户拥有更多的Parquet文件,他们希望保持平衡。
- ((块url,行组))?这标识了特定块的独特身份,但是很难列出某一天的所有块,因为时间戳不在键中。
- ((表url,小时))?这很管用,因为如果你有24小时的查询时间,就很容易查询。
- ((表url,小时),块url,行组)?这是他们选择的。通过将块URL和行组添加为聚簇键,他们可以在一小时内轻松检索某个特定块,这也简化了更新或删除块和行组的过程。
布隆过滤器分块和数据建模
下一个挑战是:考虑到ScyllaDB没有提供相应的开箱即用功能,如何验证某些位是否已设置。团队决定读取布隆过滤器,并在应用程序中处理它们。不过记住,他们每天为每个客户处理多达50000个块,每个块含有布隆过滤器部分的262KB。总共是12GB——对于一个查询来说太大了,无法拉回到应用程序中。但他们不需要每次都读取整个布隆过滤器,只需要其中的一部分,这取决于查询执行期间涉及的令牌。因此,他们最终将布隆过滤器分成几行,这将读取的数据减少到易于管理的1.6 MB。
对于数据建模,一种选择是使用((block_url, row_group),块索引)作为主键。这将为每个布隆过滤器生成8192个32字节的块,从而生成每个分区约262 KB的均匀分布。对于同一分区中的每个布隆过滤器,使用单个批处理查询就可以轻松插入和删除数据。但是有一个问题会影响读取效率:在读取布隆过滤器之前,您需要知道块的ID。此外,该方法需要访问大量的分区;5万个块意味着5万个分区。正如Vercruysse特别指出:“就算使用像ScyllaDB这样快的技术,仍然很难为5万个分区实现亚秒级处理。”
另一个选项(这也是他们最终决定的):((表url,小时,块索引),块url,行组)。请注意,这是与块相同的分区键,只是在分区键上添加了一个索引,该索引表示查询引擎所需的第n个令牌。使用这种方法,扫描24小时时间窗口的5个令牌可生成120个分区——与之前的数据建模选项相比,这个改进很出色。
此外,这种方法在读取布隆过滤器之前不再需要块ID,从而允许更快的读取。当然,总存在不足之处。在这里,由于阻塞布隆过滤器方法,他们不得不将单个布隆过滤器拆分为8192个独特分区。与之前允许一次摄取所有布隆过滤器块的分区方法相比,这最终限制了摄取速度。然而,能够在一小时内快速读取某个块比快速写入来得更重要,因此他们认为这种取舍是值得的。
数据建模问题
毫不奇怪,从SQL迁移到NoSQL需要大量的数据建模返工,包括一些试错。比如说,Vercruysse表示:“有一天,我认识到我们弄乱了最小和最大时间戳——我想知道我该如何修复它。我想也许可以重命名这些列,然后让它重新运行。但是,如果列是聚簇键的一部分,你就无法重命名列。我想也许可以添加新列并运行UPDATE查询来更新所有行。遗憾的是,这在NoSQL中也行不通。”

最终,他们决定截断表并重新开始,而不是编写迁移代码。在这方面,他们给出的最好建议是第一次就把事情做好。
性能提升
尽管需要进行数据建模工作,但迁移收到了很好的成效。对于Metastore块列表:
- 每个节点当前处理4到5 TB的数据。
- 他们目前每秒处理大约1万个写入操作,P99延迟始终低于1毫秒。
- 块列表在一小时内生成了大约2000个Parquet文件;就布隆过滤器而言,他们的处理时间不到20毫秒。对于5万个文件,处理时不到500毫秒。
他们还执行了位校验。但是对于5万个Parquet文件而言,500毫秒可以满足需求。
在列元数据处理中,P50相当不错,但尾部延迟较高。Vercruysse解释:“问题在于,如果我们有5万个Parquet文件,我们的执行器会并行获取所有这些文件。这意味着我们有很多并发查询,我们没有使用最好的磁盘。我们认为这是问题的根源。”
ScyllaDB设置
值得注意的是,Coralogix从最初发现ScyllaDB到部署到拥有TB级数据的生产环境仅用了两个月(这是需要数据建模工作的SQL到NoSQL迁移,而不是简单得多的Cassandra或DynamoDB迁移)。
实现是在ScyllaDB Rust驱动程序上用Rust编写的,他们发现ScyllaDB Operator for Kubernetes、ScyllaDB Monitoring和ScyllaDB Manager都对快速迁移大有帮助。由于为他们自己的客户提供低成本的可观测性替代方案对Coralogix很重要,因此团队对他们的ScyllaDB基础设施的性价比感到满意,一个三节点聚簇有以下配置:
- 8个vCPU
- 32 GB内存
- Arm/Graviton
- 带宽为500mbps、IOPS为12k的EBS卷(gp3)
使用ARM可以降低成本,而决定使用弹性块存储(EBS)(gp3)卷最终归结为可用性、灵活性和性价比。他们承认:“这是一个有争议的决定,但我们正在努力让它切实可行,我们会看看我们能坚持多久。”
汲取的经验
他们在这里学到的主要经验是:
- 注意分区大小:使用ScyllaDB与使用Postgres的最大区别是,您必须非常仔细地考虑分区和分区大小。有效的分区和聚簇键选择对性能有很大的影响。
- 考虑读/写模式:您还必须仔细考虑读/写模式。您的工作负载是不是读取密集型?它是否涉及搭配均衡的读写操作?或者,以写入操作为主?Coralogix的工作负载有大量的写入操作,就因为他们不断地摄取数据,但需要优先考虑读取操作,因为读取延迟对业务来说最关键。
- 避免EBS:团队承认他们被警告不要使用EBS:“我们没有听从,但我们可能应该听从。如果您在考虑使用ScyllaDB,那么查看具有本地SSD的实例而不是尝试使用EBS卷可能是好主意。”
未来计划:结合使用WebAssembly UDF和Rust
将来,他们希望在写入足够大的块和读取不必要的数据之间找到折衷。他们将数据块分成大约8000行,认为可以进一步划分成1000行,这有望加快插入速度。
他们的最终目标是通过充分利用WebAssembly的用户定义函数(UDF),将更多的工作交给ScyllaDB处理。使用现有的Rust代码,集成UDF将不需要把数据发回给应用程序,为分块调整和潜在的改进提供了灵活性。
Vercruysse表示:“我们已经用Rust编写了所有内容。如果我们可以开始使用UDF,这样我们不必向应用程序发回任何其他内容。这给了我们更大的余地来处理分块。”
原文标题:From Postgres to ScyllaDB NoSQL, with a 349x Speed Boost,作者:Cynthia Dunlop




















