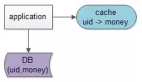
缓存是优化应用程序性能的一项关键技术,它可以临时存储频繁访问的数据,以便在后续请求期间更快地进行检索。多层缓存使用多层来存储和检索数据,可以显著减少延迟,并提高整体性能。
本文将从架构和开发的角度探讨多层缓存的概念,重点关注像Instagram这样的实际应用程序,并提供设计和实现高效多层缓存系统的见解。
理解真实世界应用中的多层缓存:Instagram示例
Instagram是一个流行的照片和视频分享社交媒体平台,每天处理大量数据和大量的用户请求。为了保持最佳性能并提供无缝的用户体验,Instagram采用了高效的多层缓存策略,包括内存缓存、分布式缓存和内容分发网络(CDN)。
1.内存缓存
Instagram使用内存缓存系统(例如Memcached和Redis)来存储频繁访问的数据,例如用户配置文件、帖子和评论。这些缓存速度非常快,因为它们将数据存储在系统的内存中,提供对热数据的低延迟访问。
2.分布式缓存
为了处理大量用户生成的数据,Instagram还采用了分布式缓存系统。这些系统跨多个节点存储数据,确保了可扩展性和容错性。分布式缓存(例如Cassandra和Amazon DynamoDB)用于管理大规模数据存储,同时保持高可用性和低延迟。
3.内容分发网络(CDN)
Instagram利用CDN更快地为用户缓存和提供静态内容,这通过从离用户最近的服务器提供内容来减少延迟。Akamai、Cloudflare和Amazon CloudFront等CDN有助于将图像、视频和JavaScript文件等静态资产分发到全球边缘服务器。
设计和实现多层缓存系统的架构和开发见解
在设计和实现多层缓存系统时,需要考虑以下因素:
1.数据访问模式
分析应用程序的数据访问模式,以确定最合适的缓存策略。考虑数据大小、访问频率和数据波动性等因素。例如,频繁访问且很少修改的数据可以从主动缓存中受益,而易失性数据可能需要更保守的方法。
2.缓存退出策略
根据数据访问模式和业务需求,为每个缓存层选择适当的缓存退出策略。常见的驱逐策略包括最近最少使用(LRU)、先进先出(FIFO)、生存时间(TTL)。每种策略都有其利弊,选择正确的策略会显著影响缓存性能。
3.可扩展性和容错性
缓存系统被设计为可扩展和容错的。分布式缓存通过跨多个节点划分数据并复制数据以实现冗余。在选择分布式缓存解决方案时,要考虑一致性、分区容忍度和可用性等因素。
4.监控和可观测性
监控和可观察性工具用来跟踪缓存性能、命中率和资源利用率。这使开发人员能够识别潜在的瓶颈,优化缓存设置,并确保缓存系统有效地运行。
5.缓存失效
设计一个健壮的缓存失效策略,使缓存的数据与底层数据源保持一致。例如直写缓存、旁路缓存和事件驱动的失效等技术可以帮助保持缓存层之间的数据一致性。
6.开发注意事项
为应用程序的技术栈选择适当的缓存库和工具。对于Java应用程序,可以考虑使用谷歌的Guava或Caffeine进行内存缓存。对于分布式缓存,可以考虑使用Redis、Memcached或Amazon DynamoDB。确保缓存实现是模块化和可扩展的,以便与不同的缓存技术轻松集成。
示例
下面的代码片段演示了使用Python和Redis实现分布式缓存层的多层缓存系统的简单实现。
首先,需要安装Redis软件包:
接下来,使用以下代码创建一个Python脚本:
这个示例演示了一个简单的多层缓存,使用内存缓存和Redis作为分布式缓存。InMemoryCache类使用Python字典来存储带有生存时间(TTL)的缓存值。DistributedCache类使用Redis进行分布式缓存,并具有单独的生存时间(TTL)。MultiLayeredCache类结合了这两个层,并处理跨两层的数据获取和存储。
注意:开发人员应该在本地主机上运行一个Redis服务器。
结论
多层缓存是一种强大的技术,可以通过有效地利用资源和减少延迟来提高应用程序的性能。像Instagram这样的现实应用程序展示了多层缓存在处理大量数据和流量的同时保持流畅的用户体验的价值。通过理解本文中提供的架构和开发见解,开发人员可以在他们的项目中设计和实现多层缓存系统,优化应用程序以获得更快、响应更快的体验。无论是使用硬件还是基于软件的缓存系统,多层缓存都是对开发人员具有重要价值的一个工具。
原文标题:Architectural Insights: Designing Efficient Multi-Layered Caching With Instagram Example,作者:Arun Pandey。
链接:https://dzone.com/articles/architectural-insights-designing-efficient-multi-l。