Kafka 会丢失信息吗?
许多开发人员普遍认为,Kafka 的设计本身就能保证不会丢失消息。然而,Kafka 架构和配置的细微差别会导致消息的丢失。我们需要了解它如何以及何时可能丢失消息,并防止此类情况的发生。
下图显示了消息在 Kafka 的生命周期中可能丢失的场景。
 图片
图片
01 生产者(Producer)
当我们调用 producer.send() 发送消息时,消息不会直接发送到代理。
消息发送过程涉及两个线程和一个队列:
- 应用程序线程
- 消息累加器
- 发送线程(I/O 线程)
我们需要为生产者配置适当的 "acks "和 "retries",以确保消息被发送到代理。
02 消息代理(Broker)
当代理集群正常运行时,它不应该丢失消息。但是,我们需要了解哪些极端情况可能会导致消息丢失:
- 为了提高 I/O 吞吐量,消息通常会异步刷到磁盘上,因此如果实例在刷新之前宕机,消息就会丢失。
- Kafka 集群中的副本需要正确配置,以保持数据的有效副本。数据同步的确定性非常重要。
03 消费者(Consumer)
Kafka 提供了不同的提交消息的方式。自动提交可能会在实际处理记录之前确认对记录的处理。当消费者在处理过程中宕机时,有些记录可能永远不会被处理。
一个好的做法是将同步提交和异步提交结合起来,在处理消息的循环中使用异步提交以提高吞吐量,在异常处理中使用同步提交以确保最后的偏移始终被提交。
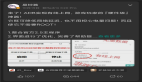
下图是这个方法的伪代码:
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
// process records one by one
}
consumer.commitAsync();
}
} catch (Exception e){
// exception handling
} finally {
try {
consumer.commitSync();
} finally {
consumer.close();
}
}