Node.js,一个在开发者中口碑相传的JavaScript运行环境,以其单线程事件循环而著称。但你知道吗?在这个简单的架构之下,隐藏着强大的功能等待被发掘。今天,就让我们一起探索Node.js的五大特性,它们能极大地丰富你的开发体验,包括:
- 工作线程(Worker Threads)
- 集群进程模块(Cluster Process Module)
- 内置HTTP/2支持
- 流API(Streams API)
- 交互式解释器(REPL)
让我们带着兴奋的心情,一步步深入了解这些特性吧!
巧用工作线程,提升Node.js性能的秘诀(Worker Threads)
在Node.js的世界里,我们常常会听到这样的话:“Node.js是单线程的”。的确,这是它的默认行为,但在面对CPU密集型任务时,我们就需要一些小技巧来突破这一限制。好在Node.js提供了一个强大的工具:工作线程(Worker Threads)。
工作线程:多个大厨的厨房
想象一下,如果你的厨房里只有一个大厨,所有的菜都需要他一个人来准备,这无疑会非常低效。而工作线程,就好比在这个厨房里增加了多个大厨,他们能够独立工作,同时准备不同的菜肴(任务),这样效率自然大大提高。
下面的图片展示了两种情况:传统的单线程处理代码方式,以及引入工作线程后的处理方式。
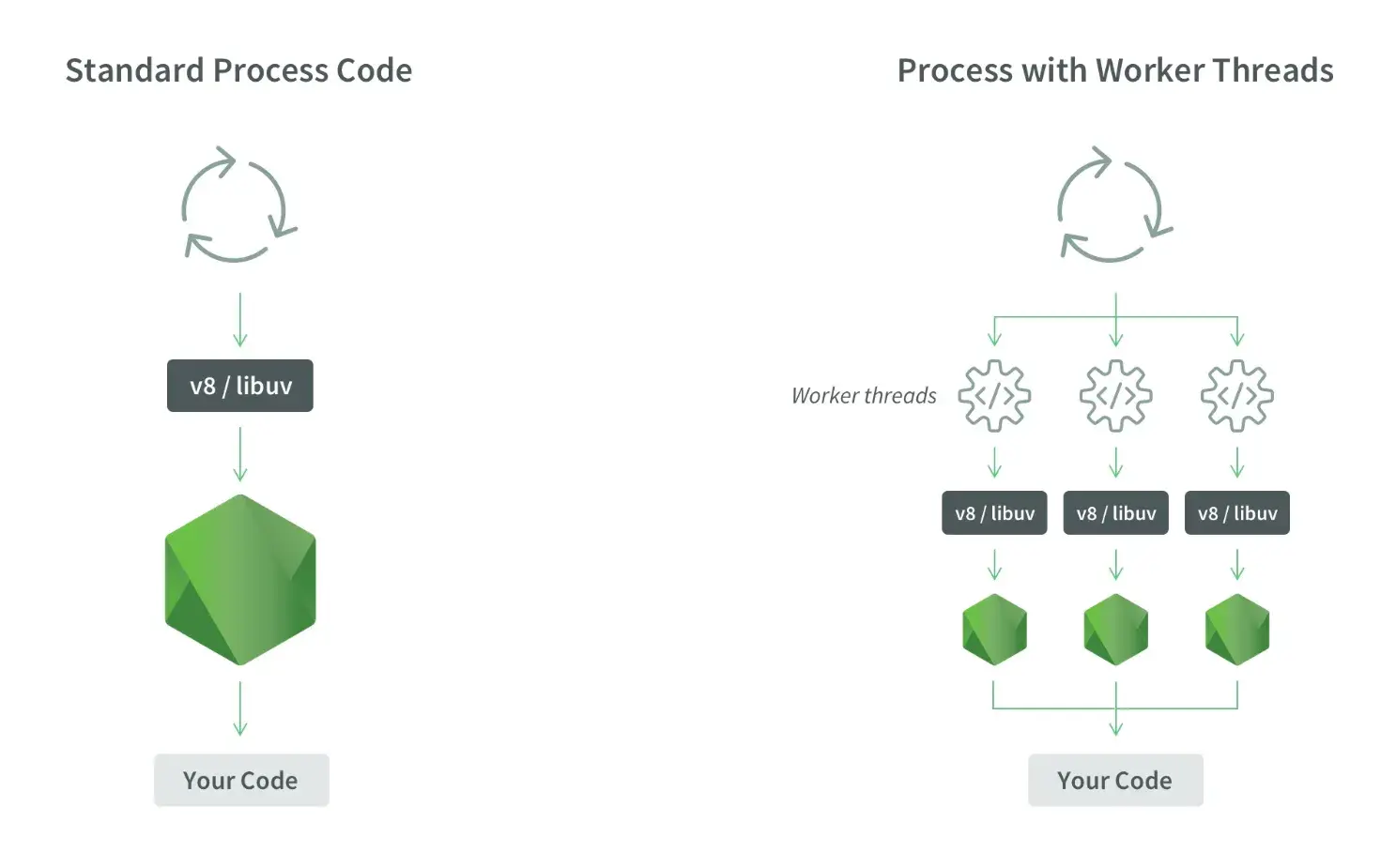
- 标准处理代码:所有的任务都需要通过同一个事件循环来处理,由单一的V8引擎负责执行你的代码。
- 工作线程处理:你的任务可以被分配给多个工作线程,每个工作线程都有自己的V8引擎实例,它们可以并行处理任务,而不会干扰主线程的事件循环。
工作线程的优势
- 卸载CPU密集型任务:让主线程解放出来,处理其他工作。
- 实现并行计算:任务可以并发执行,提高性能。
- 高效共享数据:通过ArrayBuffer或SharedArrayBuffer等结构,避免数据之间的不必要复制。
如何开始使用工作线程
Node.js的worker_threads模块提供了一个简单的API,让你能够轻松创建和管理工作线程:
记住,工作线程是共享内存的,这意味着对于大型数据交换,使用ArrayBuffer或SharedArrayBuffer是推荐的做法,这样可以避免不必要的数据复制。
同时还要注意:
- 创建和管理工作线程是有开销的,所以需要根据你的具体场景来考虑它的利弊。
- 线程安全至关重要!使用同步机制来确保数据完整性。
- 工作线程增加了复杂性,因此只有在真正能从并行计算中受益的任务上使用它们。
通过引入工作线程,Node.js可以更好地处理那些对性能要求较高的场景。你准备好尝试这个强大的特性了吗?动手试试吧,让你的Node.js应用飞速运行!
集群模块:多核心系统下的性能利器
在Node.js的世界里,我们已经知道了工作线程的强大,它让我们能够在同一个进程中并行处理多个任务。但是,如果你想在多核心系统中进一步提升性能,那就不能错过另一个功能强大的模块——集群(Cluster)。
集群的概念:多个独立的厨房
假设你不仅有一个厨房和多个大厨,而且每个大厨还有自己的独立厨房。他们可以同时独立处理各种请求,这正是集群所能带来的威力。
在这张图片中,我们看到了一个基于集群模块的概念图。它展示了如何将请求分配到不同的核心上。
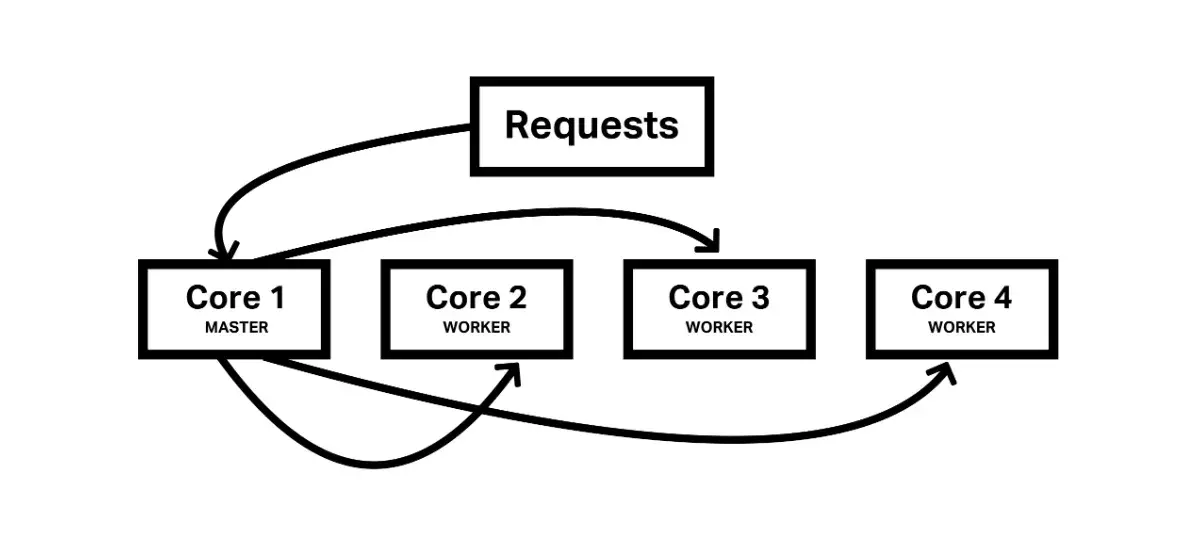
- 核心1(Master):这是主进程,负责管理和分配进入的连接。
- 核心2、核心3、核心4(Worker):这些是工作进程,可以在不同的核心上独立运行,充分利用多核心进行性能优化。
集群的优势
- 提升性能:处理更高的流量,尤其是在I/O密集型任务上,提升响应时间。
- 最大化资源利用:充分利用服务器上所有可用的核心,显著增加处理能力。
- 增强容错能力:如果一个工作进程崩溃,其他工作进程仍能保持应用运行,确保可靠性和正常运行时间。
如何开始使用集群
Node.js的cluster模块提供了一个直观的API,用于设置和管理工作进程:
记住:
- 工作进程共享内存和资源,因此要仔细考虑数据同步问题。
- 集群模块会增加应用架构的复杂性,所以需要根据具体需求评估它的益处与复杂性。
集群模块何时考虑使用:
- 高流量网站:当你的单线程事件循环达到极限时,通过集群进行水平扩展可以有效管理庞大的用户基础。
- 长时间运行的任务:如果某些请求涉及长时间操作(如图像处理或数据加密),将它们分布在不同的工作进程中可以提高其他请求的响应性。
- 容错性至关重要:对于任务关键的应用程序,集群模块对单个进程失败的弹性提供了宝贵的保护。
利用集群模块,你可以把Node.js的应用性能推向新的高度。试试看,让你的应用在多核心的强大推动下,高速运转起来吧!
HTTP/2模块:高效网络通信的秘密武器
在Node.js中,工作线程和集群模块帮助我们在处理任务和性能上达到了一个新的高度。但当涉及到网络通信时,HTTP/2协议的支持就显得尤为重要。Node.js内置的http2模块为这一高效的协议提供了支持,直接对性能进行了优化。
HTTP/2协议是什么?
HTTP/2是HTTP/1.1的继承者,它带来了几项性能提升:
- 多路复用:在单个连接上同时发送和接收多个请求和响应,消除了HTTP/1.1中的队头阻塞问题。
- 头部压缩:通过压缩头部来减小头部大小,大幅减少数据传输的开销。
- 服务器推送:允许服务器在客户端请求之前主动发送资源,可能加速页面加载时间。
Node.js是如何支持HTTP/2的?
Node.js提供了一个健壮的http2模块,用于处理HTTP/2。这个模块提供了以下特性:
- 创建HTTP/2服务器:使用熟悉的Node.js服务器模式,并增加了管理流和服务器推送功能的选项。
- 处理HTTP/2客户端:访问客户端功能,连接并与HTTP/2服务器交互。
- 广泛的API:探索各种方法和事件来管理连接、流、推送机制和错误处理。
开始使用http2
Node.js的文档提供了详细的指南和示例,用于使用http2模块。让我们来看一些实际的例子,来展示它的使用方式。
创建一个基本的HTTP/2服务器:
这段代码创建了一个简单的服务器,它向通过HTTP/2连接的任何客户端发送“Hello”消息。
处理客户端请求:
这段代码扩展了前一个例子,用来处理不同的请求路径(/),并发送适当的响应。通过利用HTTP/2的多种特性,Node.js的网络通信变得更加高效和可靠。
Streams API:高效数据处理的艺术
在Node.js中,Streams API是一个用于高效数据处理的强大基础。掌握了流,你就能构建可扩展且性能出色的系统。
流是什么?
想象一下数据像水流一样流动,这就是流的概念。
流代表了随时间传递的连续数据块序列。Node.js提供了多种类型的流,每种都适用于不同的场景:
- 可读流(Readable Streams):为消费输出数据块,适用于读取文件、网络连接或用户输入。
- 可写流(Writable Streams):允许写入数据块,完美适合写入文件、网络连接或数据库。
- 双工流(Duplex Streams):结合了读写能力,适用于双向通信,如套接字或管道。
- 转换流(Transform Streams):在数据流动过程中修改数据,可以用于加密、压缩或数据处理。
为什么要使用流?
当涉及到大型数据集或连续数据流时,流的优势尤其明显。它们提供了几个优点:
- 内存效率:流通过分块处理数据,避免一次性将整个数据集加载到内存中。
- 非阻塞性质:流不会阻塞主线程,允许应用在处理数据时保持响应。
- 灵活性:不同类型的流适应了各种数据处理需求。
开始使用流
通过探索内置的fs模块,我们可以实际介绍流。这里有一个逐块读取文件的例子:
这段代码逐块读取large_file.txt文件,并将它们记录到控制台。可以在Node.js文档中探索更多类型及其用法。
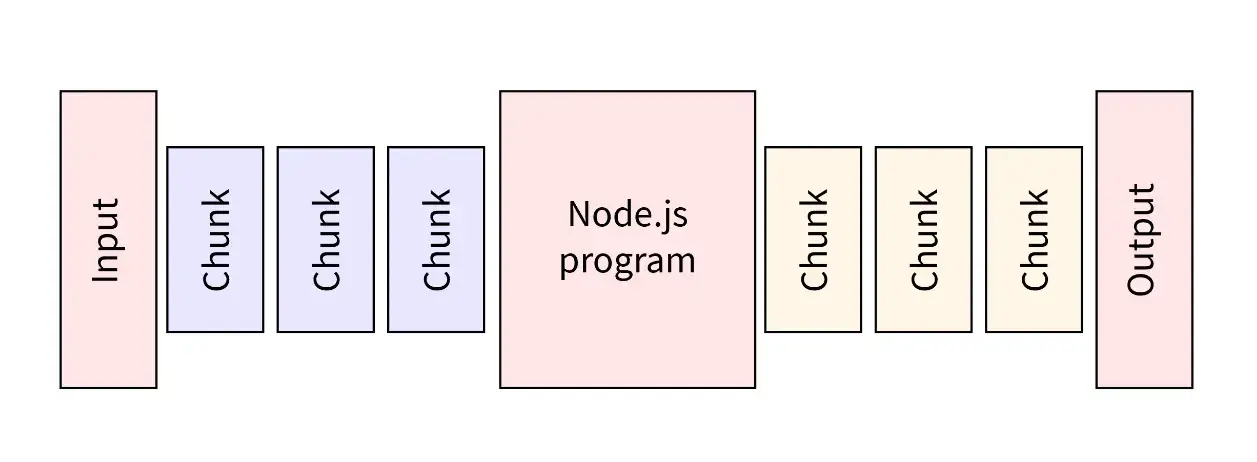
上图描绘了这个概念:输入数据被分成多个块,流经Node.js程序,并最终输出处理后的数据块。这种方式让你能够高效地处理例如视频流、大型日志文件或任何类型的数据流。流是Node.js中不可或缺的一部分,它们可以让你的应用在处理大量数据时更加敏捷和高效。
REPL:交互式编程的魅力
在Node.js的世界中,工作线程和集群模块提高了性能和可扩展性,HTTP/2和流扩展了这些能力,为多个领域提供了多样化的好处。而在另一个战场上,REPL(读取-求值-打印循环)则引入了一种不同的力量 — 交互性和探索性。
想象一个沙盒环境,在这里你可以实验代码片段,测试想法,并获得即时反馈 — 这就是REPL的本质。
可以将它看作是一种对话式编码体验。你输入代码表达式,REPL求值并显示结果,让你可以迅速迭代和学习。这使得REPL对于以下方面非常宝贵:
- 学习和实验:在一个安全、隔离的环境中尝试新的JavaScript特性,探索库,并测试假设。
- 调试和故障排除:逐行隔离并修复代码中的问题,检查每一步的变量和值。
- 交互式开发:快速原型设计,立即获得反馈,并迭代精炼你的代码。
如何访问REPL:
打开你的终端,简单地输入node。瞧!你现在已经进入REPL,准备好玩耍了。输入任何JavaScript变量赋值,函数调用,甚至复杂的计算。
与前面概述的所有强大功能相比,REPL可能看起来欺人太甚的简单。然而,只有通过亲身体验,它的真正价值才变得明显。作为一个Node.js开发者,将REPL融入到你的工作流中,不仅有益,而且至关重要。
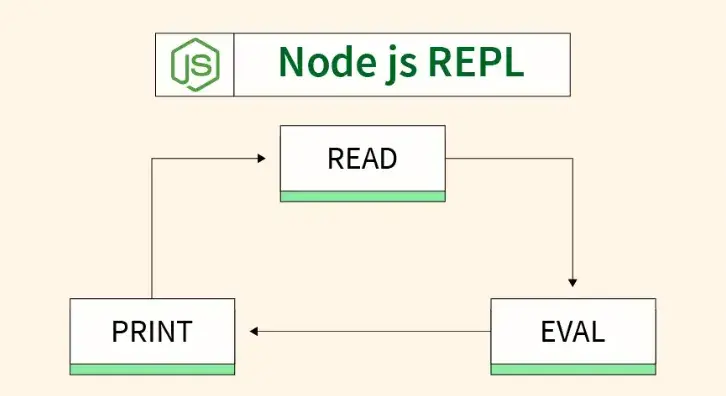
上图展示了Node.js REPL的工作原理。你输入代码(READ),它求值(EVAL),然后打印出结果(PRINT),如果需要,这个循环可以继续进行。
REPL是一个快速实验和解决问题的完美工具。它是Node.js生态中不可或缺的一部分,无论是新手还是资深开发者都能从中受益。下次当你需要快速测试一个想法或函数时,不妨尝试一下REPL吧!
结束
Node.js作为当下最流行的JavaScript运行环境,它所提供的强大工具集能够帮助开发者解决各种各样的问题。工作线程(Worker Threads)能够让我们更好地处理CPU密集型任务;集群模块(Cluster)可以实现应用的水平扩展;HTTP/2模块让我们能够利用高效的HTTP/2网络协议;而流(Streams)则提供了高效的数据处理方式;REPL(读取-求值-打印循环)则为交互式的探索和学习提供了强大支持。
通过精通这些特性,你将能够释放Node.js的全部潜能,构建出性能高、可扩展、并且开发体验愉快的应用。
在你的开发旅程中,不断地探索和应用这些工具,将使你能够更加自信地面对各种挑战,创造出更加出色和创新的解决方案。无论是在后端开发、提供强大的API,还是在处理大数据流和快速原型设计中,Node.js的这些工具都能帮助你达到目标。
现在,让我们拿起这些工具,开始构建未来吧!