













这是一个很少被提及的话题 —— 「依赖管理」(Dependencies Management) 。
在开源文化盛行的现代,多数时候我们都不必从零开始搭建一套软件系统,转而可以借助诸多开放的代码片段及其他资源更快速高效开发软件应用,这算的上软件工程发展史上一次巨大革命,因为它能大幅提升软件工业的生产效率,我们不必再从底层开始编写所有代码,大部分问题与常见的编程模式都能在社区找到相应的解决方案,且这些被反复消费锤炼的软件包通常有更高的稳定性与性能,你需要做的只是花一些时间了解学习这些开源资源,并在项目使用它们,“ 「依赖」 ”它们即可,这已经是一种被不断实践,不断被验证为行之有效的开发模式。
但现实比预想的复杂许多,如果你开发的只是规模较小,或生命周期非常短的项目时,依赖的状态并不会造成多大问题,你只要确保当下执行 ok,功能符合预期即可。但,任何软件项目一旦叠加“「规模」”与“「时间」”两个变量之后,依赖网络就很容易变得复杂混乱,如果不及时施加恰当的管理手段则迟早会引发诸多晦涩难懂的稳定性、性能、安全等诸多方面的问题。因此,我们需要学习了解“依赖管理”的基本含义与潜在风险,需要掌握一些软件工程管理方面的方式方法,确保依赖网络及其随时间发生的变化都在可控范围内,让依赖网络尽可能保持一个清晰有条理,且具备一定程度的健壮性。
在展开具体内容之前,我们先明确一下“依赖”这个概念,严格来说,你的代码所需要消费的任何直接与间接资源都归属于“依赖”范畴,往小了说,包括系统时间、语言特性(如事件循环、闭包)、执行环境(如浏览器接口、node 接口)等;往大了说还包括:操作系统、网络,甚至硬件设备(如 GPU),但这些并不在本文讨论范围内,诚然这些要素也可能带来性能、安全性各方面的影响,但多数属于基础设施,稳定性还是比较有保障的。
本文希望更聚焦讨论 Node 场景下的依赖 —— 或者更直观的说是 NPM Package 结构的不稳定性所带来的被严重低估的质量风险,以及相应的应对策略。
第三方依赖带来的问题
09 年 NodeJS + NPM 的出现,不仅让 JavaScript 拥有了脱离浏览器环境执行的能力,也带来一套相对体系化的依赖管理方案,在此之前的依赖管理多数由“人”手工完成,需要用到什么就手动 copy 代码进仓库,或者 copy cdn 链接到 HTML 页面。
而 NPM(Node Package Manager) 让这件事情 「尽可能」 做到了自动化,我们只需要执行 npm install 命令即可自动完成下述工作:
- 解析依赖树:根据项目 package.json 文件中的依赖项列表,递归检查每个依赖项及子依赖项的名称和版本要求,构建出依赖树并计算每一个依赖需要安装的确切版本(这个并不容易做到,参考:Version SAT);
- 参考:https://research.swtch.com/version-sat
- 下载依赖项:构建出完整的依赖树后,npm 会根据依赖项的名称和版本,下载相应的依赖包,下载过程还会对依赖包做一系列安全检查,防止被篡改;
- 安装依赖项:当依赖项下载完成后,npm 将它们安装到项目的
node_modules目录中。它会在该目录下创建一个与依赖项名称相对应的文件夹,并将软件包的文件和目录解压复制到相应的位置(不同包管理器最终产出的包结构不同); - 解决依赖冲突:在安装依赖项的过程中,可能会出现依赖冲突,即不同依赖项对同一软件包的版本有不同的要求。npm 会尝试解决这些冲突,通常采用版本回退或更新来满足所有依赖项的要求;
- 更新 package-lock.json:在安装完成后,npm 会更新项目目录下的
package-lock.json文件。该文件记录了实际安装的软件包和版本信息,以及确切的依赖关系树,可用于确保在后续安装过程中保持一致的依赖项状态(npm ci);
PS: 本文仅以 NPM 举例,yarn、pnpm 的执行算法虽差异较大,但整体遵循上述过程,因此不再赘述。
相比于过往人工管理的各种低效且容易出错的骚操作,NPM 这类包管理器能以极低的成本,更规范化、自动化完成依赖包的检索、安装、更新等管理动作,更容易搭建出一个相对稳定且安全可靠的工程环境,也更容易复用外部那些经过良好封装、充分测试的代码片段。
But,伴随着工程能力的提升,依赖之间的复杂度也在急剧增长,当前我们正面临着更多依赖管理相关的工程问题,例如:幽灵依赖、版本冲突、依赖地狱等等,这些问题很少被讨论却时时刻刻影响着工程项目的稳定性、开发效率、性能等要素,接下来我会尽可能完整讨论依赖管理的方方面面,帮助大家更深入了解这些潜藏在日常开发之下很少被察觉的各类问题,并讨论相关的应对方案。
依赖管理潜在的问题
1. semver 并不稳定
先从依赖管理中最浅显直观的视角讲起,当我们决定使用某一个 NPM 包时,需要做的第一件事就是在项目 package.json 文件中定义 dependencies ,类似于:
{
"name": "foo",
"dependencies": {
"lodash": "^1.0.0"
}
}这似乎已经是一种简单而自然,不需要过多讨论的常识,but,我们应该依赖于 Package 的那些版本呢?
答案取决于具体的功能需求、稳定性、性能等诸多因素,但一个大致通用的实践是:「尽可能使用最新版本的范围版本」,例如假定 React 最新版本为 18.2.0,在项目中可以声明依赖为 "react": "^18.2.0",这种方法一方面能够应用最新版本 —— 这可能意味着更多的功能,以及更好的性能等;另一方面,借助 ^ 声明该依赖接受 >= 18.2.0 < 19 的版本范围,在 React 下次发布 18.2.1 或更大版本时都能自动匹配应用,以此获得一定范围内动态更新依赖的能力。
PS:补充一个知识点,当前多数框架都遵循 semver 版本号(https://semver.org/)规则,即包含 Major.Minor.Patch 三段版本号,Major 代表较大范围的功能迭代,通常意味着破坏性更新;Minor 代表小版本迭代,可能带来若干新接口但“承诺”向后兼容;Patch 代表补丁版本,通常意味着没有明显的接口变化。
这看似很完美,但实践却漏洞百出。首先,部分 NPM 包作者并没有严格遵守 semver 定义的规则迭代版本号,特别是许多公司内部依赖的版本管理更是混乱不堪,Patch 可能破坏原本的接口定义(多一个参数少一个参数),Minor 可能导致向后不兼容,等等,致使旧代码无法正常执行。
其次,即使完全按照 semver 语义严格管理版本号,谁又能保证每次版本迭代都能完美符合用户预期呢?例如按照 semver 语义,Patch 只用作 bug 修复,但难保会在一些边界情况发生变化,比如:「日志」,讲道理用户不应该直接依赖代码包的日志输出,但可能有一些输入输出没有覆盖用户需求,或者用户没有了解到正确的使用方式,致使消费者倾向于直接从运行日志解读信息(只要用户体量足够大,总会出现一些意料之外的使用方法),若此时 Patch 版本更改了日志内容 —— 这看似很合理,却可能导致日志解析失败。从这个示例来说,日志算不算补丁更新呢?这种情况下,Patch 还是安全的吗?
那么,能不能放弃范围版本,写死版本号呢?例如上例中只要把依赖关系写死成 "react": "18.2.0" 似乎就能规避版本变化带来的不确定性?某种程度上确实如此,但这又会带来新的风险:版本累积可能带来更大的破坏性更新!我们必须承认一个事实:无论你有多强的惰性,「软件项目只要存活的时间足够长,就总会有一天需要升级依赖」,升级的主因可能是:安全、合规、性能、架构调整等等,如果你从一开始就在使用某个固定版本,直到不得不更新的时刻到来时,新版本的使用方案、功能表现等可能都已经发生了剧变(例如,从 React 17 => 18),很可能会导致你原本运行良好的程序漏洞百出,质量风险、回归成本都很高。
因此,「良好的依赖管理策略应该在保证稳定的前提下,定期跟进依赖包的更新」,小步快进将升级风险分摊到每一次小版本迭代中,为达成这一效果,一个比较 「常见」 的实践是在开发环境中使用适当的范围版本,在测试 & 生产环境使用固定版本,以 NPM 为例,可以继续沿用 "react": "^18.2.0",在开发态中使用 npm install 安装依赖,在测试 & 生产环境则使用 npm ci 命令,两者区别在于 npm install 会尝试更新依赖,触发依赖结构树变化并记录到 package-lock.json 文件;而 npm ci 则严格按照 package-lock.json 内容准确安装各个依赖版本,在 CI/CD 环境中能获得更强的稳定性,确保代码行为与开发环境尽可能一致。
2. 依赖类型
在确定依赖版本之后,接下来需要决定将依赖注册到那个 dependencies 节点,按 package.json 规则,可选类型有:
- dependencies:生产依赖,指在软件包执行时必需的依赖项。这些依赖项是你的应用程序或模块的核心组成部分,当你部署到生产或测试环境时,这些依赖项都需要被安装消费;
- devDependencies:开发依赖,仅在开发过程中需要使用的依赖项,通常包括测试框架、构建工具、代码检查器、TS 类型库等。开发依赖项不需要在生产环境安装;
- peerDependencies:对等依赖,用于指定当前 package 希望宿主环境提供的依赖,这解释有点绕,下面我们会展开解释;
- optionalDependencies:可选依赖,当满足特定条件时可以选择性安装的依赖,且即使安装失败,安装命令也不会中断。可选依赖项通常用于提供额外的功能或优化,并不是必需的;
- bundledDependencies:捆绑依赖,用于指定需要一同打包发布的依赖项,用的比较少。
根据我们正在开发的软件包的用途及对依赖的使用方式,这里会有不同的决策逻辑。
假设正在开发的是“顶层”应用(Web APP、Service、CLI 等),那么多数依赖都可以注册到 devDependencies 或 dependencies 节点,这也是我们日常应用比较多的依赖类型。两者主要差异在于:dependencies 是生产环境依赖,是确保软件包正常运行的必要依赖项;而 devDependencies 则是仅在开发阶段需要使用的依赖项。
举个例子,假设你应用逻辑中直接使用了 lodash 的方法,那么 lodash 必然是 dependencies;但假设你只是在一些构建脚本之类的非应用逻辑中使用了 lodash ,那么应该将其注册到 devDependencies 中。
PS:对于需要将代码和依赖全部打包在一起的应用 —— 例如常见的基于 Webpack 的 web 应用,从功效上 dependencies 与 devDependencies 并无差别,但建议还是根据语义对依赖做好分类管理。
换个视角,假设正在编写的代码最终会被发布成 NPM Package 供其他方消费,那么我们必须慎重许多,因为你的决策会深刻影响消费者的使用体验。首先,你必须非常谨慎地使用 dependencies,因为 NPM 在安装你这个 Package 会顺带将你的 package.json 中的 dependencies 也都安装一遍,错误的依赖分类可能会带来一些影响开发体验的 Bad Case:
- 需要占用更多的安装依赖的时间;
- 依赖结构更复杂,容易导致“菱形依赖”(后面会会展开解释)问题;
举个例子,@vue/cli 的 package.json 部分内容如下:
{
"name": "@vue/cli",
"version": "5.0.8",
...
"dependencies": {
...
"vue": "^2.6.14",
...
},
...
}那么使用者安装 @vue/cli 之后,还会强制安装 vue@^2.6.14 版本 —— 即使用户消费的可能是其他 Vue 版本,这种行为无疑都会给用户增加不必要的负担,因此,在开发 Package 时,除非有非常明确且强烈的诉求,否则都应该优先使用 devDependencies!
那么,假设你的 Package 确实存在一些必要,但又不适合注册到 dependencies 的依赖,该怎么办呢?这种 Case 也非常常见,例如 Webpack 插件通常对 Webpack 存在强依赖,但并不适合直接使用 dependencies,否则可能导致用户安装多份 Webpack 副本。针对这种情况 NPM 提供了另外一种依赖类型:peerDependencies,语义上可以理解为:Package 希望宿主环境提供的“对等”依赖,NPM 对这种类型的处理逻辑稍微有点复杂:
若宿主提供了对等依赖声明(无论是 dependencies 还是 devDependencies),则优先使用宿主版本,若版本冲突则报出警告:
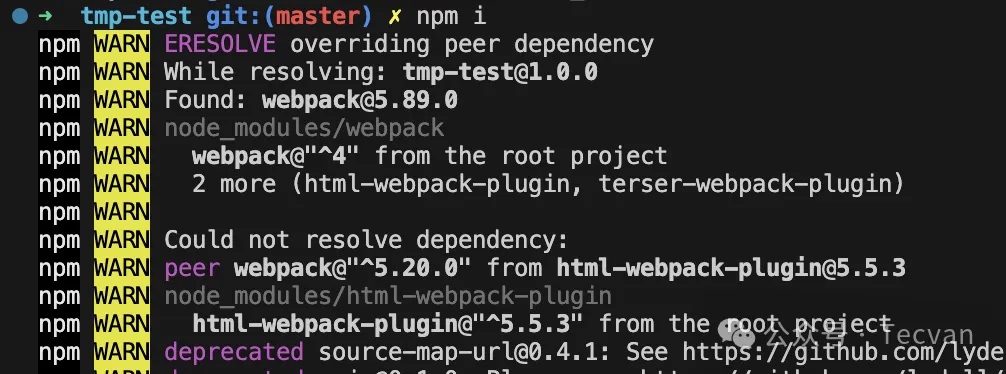
若宿主未提供对等依赖,则尝试自动安装对应依赖版本(NPM 7.0 之后支持)。
PS:正是因为 peerDependencies 的复杂性,不同包管理器,甚至同一包管理器的不同版本对其处理逻辑都有所不同,例如 NPM 在 3.0 之前支持自动安装 peerDependencies,但这一特性带来的问题比较多,3.0 之后取消了自动下载,交由消费者自行维护,一直到 7.0 版本设计了一种更高效的依赖推算算法之后,才又重新引入这一特性。
peerDependencies 能帮助我们实现:“「即要」”确保 Package 能正常运行,“「又要」”避免给用户带来额外的依赖结构复杂性,在开发 NPM Package,特别是一些“框架”插件、组件时可以多加使用,实践中通常还会:
- 使用 peerDependencies 声明 Wepack 为对等依赖,要求宿主环境安装对应依赖副本。
- 同时使用 devDependencies 声明 Wepack 为开发依赖,确保开发过程中能正确安装必要依赖项。
接下来聊一个相对冷门的类型:optionalDependencies,也就是“可选”依赖,虽然多数时候我们对 Package 的依赖应该是比较明确的:要么有要么没有,但某些特定场景下也可能是“可以有也可以没有”。
举个例子,fsevents 是一个针对 「Mac OSX」 系统的文件系统事件监控库 —— 注意啊,它只适用于 「Mac OSX」 系统,因此在其他操作系统上都不能使用 —— 自自然然的也不需要安装这个 Package,因此可以是一个“可选”依赖,实际上在知名构建工具 rollup 中就是以 optionalDependencies 方式引入 fsevents 的:
{
"name": "rollup",
"version": "4.1.4",
// ...
"optionalDependencies": {
"fsevents": "~2.3.2"
},
// ...
}需要注意,optionalDependencies 意味着“可能有也可能没有”,因此消费方式上也需要加以区分,例如 rollup 是这么导入 fsevents 的:
import type FsEvents from 'fsevents';
export async function loadFsEvents(): Promise<void> {
try {
// 使用 `import` 函数异步导入,并做好异常判断
({ default: fsEvents } = await import('fsevents'));
} catch (error: any) {
fsEventsImportError = error;
}
}
// ...代码位置:rollup/src/watch/fsevents-importer.ts
optionalDependencies 非常适合用作处理“平台”强相关的依赖,除此之外还可用于性能兜底、交互功能兜底等场景,这里就不一一赘述了。
简单总结下,package.json 提供了若干影响安装行为的依赖类型属性,以应对不同场景的管理需求,开发者需要基于性能、可用性、稳定性等角度考虑谨慎判断依赖类型。当然,也有一些基本规则能帮助我们快速识别依赖类型,包括:
- 常见的各类工程化工具,如 eslint、vitest、vite、jest、webpack 等等都适合放在 devDependencies。
- 各类 TS 类型包,例如 @types/react、@types/react-dom 一般也可以放在 devDependencies 中。
- 开发框架插件时,尽可能将框架声明为 peerDependencies,例如 webpack 与 cache-loader。
- 平台强相关的依赖,可以考虑使用 optionalDependencies,之后配合 postinstall 钩子执行平台相关的依赖安装 or 编译动作。
- 等等。
3. 失控的依赖结构
思考一下:「安装某个依赖时,需要附带安装多少子孙依赖」?很多同学此前可能没关注过这一块,这个问题并没有具体的通用答案,取决于你实际安装的包,但这个数量通常都不会很小。举个例子,知名的 React 组件库 antd 的依赖结构是这样的:
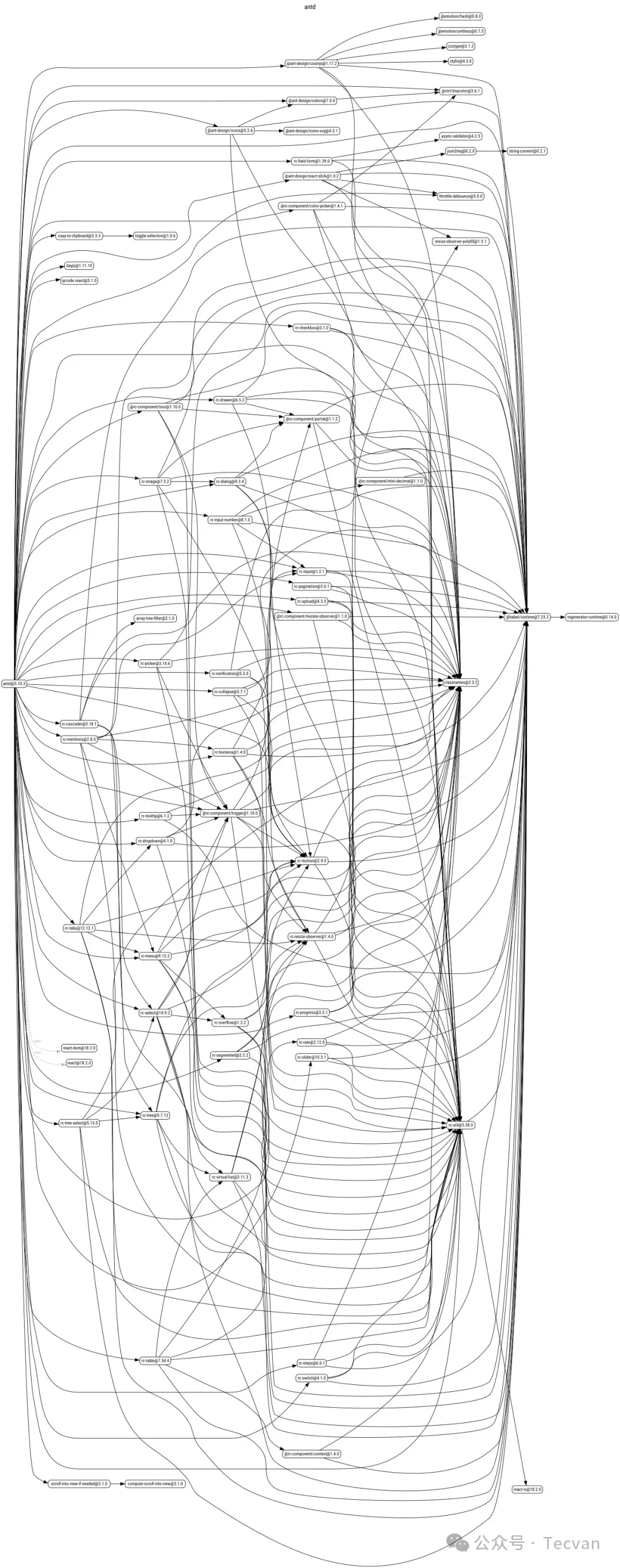
这张图肉眼可见的复杂。。。一旦我们决定使用 antd 则必须引入这一坨复杂的依赖结构,而这并不是孤例,不少知名框架都有类似问题,包括 jest、webpack、http-parser 等等,当我们依赖这些 Package 时,依赖结构最终会合并成一张庞大、复杂,且冲突不断的网络。
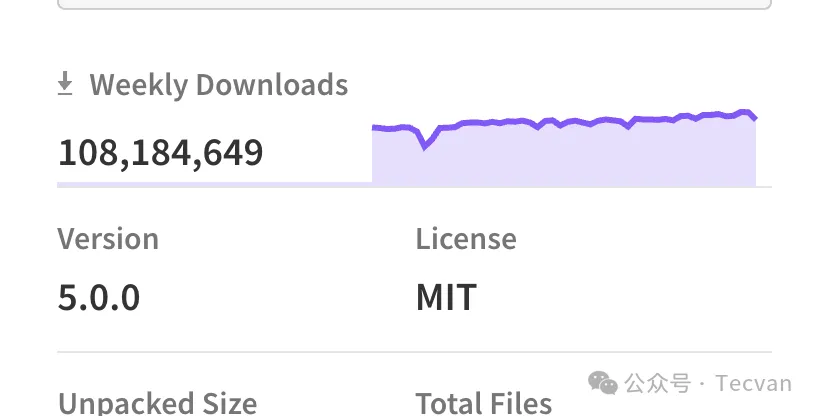
造成这一现象的原因其实不难理解,在当下开源文化环境下,跨组织的代码共享变得如此简单平常,即使是非常小的代码片段都可以以极低的成本贡献到社区供人使用。举个例子,在 NPM 上有一个这么一个 Package:escape-string-regexp,它的核心代码算上注释才不到十行,但周下载量达到惊人的一亿次:
export default function escapeStringRegexp(string) {
if (typeof string !== 'string') {
throw new TypeError('Expected a string');
}
// Escape characters with special meaning either inside or outside character sets.// Use a simple backslash escape when it’s always valid, and a `\xnn` escape when the simpler form would be disallowed by Unicode patterns’ stricter grammar.return string
.replace(/[|\\{}()[\]^$+*?.]/g, '\\$&')
.replace(/-/g, '\\x2d');
}
在此背景下,多数时候 —— 包括开发 Package 时,多数开发者在解决特定需求时自然都会倾向于使用开源代码片段,这可以帮助作者跳过代码「设计、开发、测试、调试、维护」等步骤,进而提升开发效率。
这本是一种良好实践,但当它被广泛采用时,不可避免的会带来一个副作用:依赖粒度变得非常细小,依赖网络结构变得无比复杂庞大,而这又容易(或者说必然)触发更多负面效应,包括:
- 需要计算依赖包之间的关系并下载大量依赖包,CPU 与 IO 占用都非常高,导致项目初始化与更新性能都比较差,我就曾经历过初始 yarn install 需要跑两个小时,加一个依赖需要跑半个小时的巨石项目。。。开发体验一言难尽;
- 多个 Package 的依赖网络可能存在版本冲突,轻则导致重复安装,或重复打包,严重时可能导致 Package 执行逻辑与预期不符,引入一些非常难以定位的 bug,这个问题比较隐晦却重要,后面我们还会展开细讲;
- 由于可能存在大量冲突,项目的依赖网络可能变得非常脆弱,某些边缘节点的微小变化可能触发依赖链条上层大量 Package 的版本发生变化,引起雪崩效应,进而影响软件最终执行效果,这同样可能引入一些隐晦的 bug;
- 等等吧。
那么,如何应对这些问题呢?先说结论:没有一劳永逸完美方案,只能尽力降低问题出现的范围和影响。首先我们不应该因噎废食,即使存在上述问题,依赖外置更有助于提升模块之间的低耦合高内聚,保持更佳的可维护性,在此基础上,可以适当引入一些管理措施缓解症状,包括:
- 设定更严格的开源包审核规则:除了周下载量、Star 数这些指标外,可以适当打开仓库看看代码结构是否合理,是否有单测,单测覆盖率多少,是否能通过单测,Issue 持续时间,二级依赖网络结构是否合理等等,确保依赖的质量是稳定可信赖的;
- 尽可能减少不必要的依赖:在引入第三方库时,仔细审查其功能,看看是否真的需要使用整个库,或者我们仅需要其中的部分功能,有时我们可能自己实现(甚至 Copy)这些功能更为快速、更为简单,同时也减少了对第三方库的依赖;
- 分层依赖:如果项目较大(monorepo?),可以将项目分层,每一层只能依赖相同层级或更基础的层级的库,这样可以降低各层之间的相互依赖,也有助于分层级管理依赖结构,减小变动对上游的影响;
- 避免循环依赖:循环依赖绝对是一种可怕的灾难!它不仅会急剧提升依赖网络的结构复杂度,还很可能导致一些难以预料的问题,因此在做依赖结构审计时务必尽可能规避这类情况。
4. 幽灵依赖
“幽灵依赖”是指我们明明没有在 package.json 中注册声明某个依赖包,却能在代码中引用消费该 Package,之所以出现这个问题,归根到底主要是两个因素引起的:
- NodeJS 的模块寻址逻辑;
- 包管理器执行 install 命令后,安装下来的 node_modules 文件目录结构。
众所周知(吧?),在 NodeJS 以及 Webpack、Babel 等常见工程化工具中,当我们使用 require/import 导入外部依赖包时,NodeJS 会首先尝试在当前目录下的 node_modules 寻找同名模块,若未找到则沿着目录结构逐级向上递归查找 node_modules 直至系统根目录,例如在 /home/user/project/foo.js 文件中查找模块时,可能会在如下目录尝试寻找 Package:
/home/user/project/node_module
/home/user/node_module
/home/node_module
/node_module若此时某些 Package 被安装在项目 project 路径的上层,则必然会被寻址逻辑命中,导致代码中能够“错误”引用到这个包。其次,即使不考虑这个目录递归寻址逻辑,NPM 与 Yarn 的扁平化 node_modules 结构也非常容易引起幽灵依赖问题。这里补充点历史知识,在 NPM@3 之前,每个模块的依赖项都会被放置在自己专属的 node_modules 文件夹内,即所谓的"「嵌套依赖」",例如:
- 依赖结构:
- A
- B
- C
- D
- C- node_module 结构:
- node_modules
- A
- node_modules
- B
- node_modules
- C
- D
- node_modules
- C这种方案非常容易导致依赖结构深度过大,最终可能导致文件路径超过了一些系统的最大文件路径长度限制(主要是Windows 系统),导致奔溃。这就引入 NPM@3 的优化策略:扁平化依赖结构,也就是将所有的模块 —— 无论是顶层依赖还是子依赖,都会直接写入到在项目顶层的 node_modules 目录中,例如:
- 依赖结构:
- A
- B
- C
- D
- C- node_module 结构:
- node_modules
- A
- B
- C
- D这种目录结构看起来更简洁清晰,也确实解决了目录过深的问题。「但是」,根据 NodeJS 的寻址逻辑,这也就意味着我们可以引用到任意子孙依赖!这种不明确的依赖关系是非常不稳定的,可能触发很多问题:
- 不一致性:幽灵依赖可能导致应用程序的行为在不同的环境中表现不一致,因为不同环境中可能缺少或包含不同版本的幽灵依赖;
- 不可预测性:本质上,幽灵依赖的是顶层依赖的依赖网络的一部分,你很难精细控制这些子孙依赖的版本,完全随缘;
- 难以维护:若你的代码中存在幽灵依赖,在依赖库升级或迁移时,幽灵依赖可能导致意外的兼容性问题或升级困难。
那么如何解决幽灵依赖问题呢?其实也比较简单,核心准则:请务必确保依赖关系是清晰明确的,一旦消费则必须在项目工程内注册依赖!有许多工具能帮我们达成这一点:
- 使用 pnpm:与 yarn、npm 不同,pnpm 不是简单的扁平化结构,而是使用符号链接将物理存储的依赖链接到项目的 node_modules 目录,确保每个项目只能访问在其 package.json 中明确声明的依赖;
- 使用 ESLint:ESLint 提供了不少规则用于检测幽灵依赖,例如 import/no-extraneous-dependencies,只需要在项目中启用即可;
- 使用 depcheck:这是一个用于检测未使用的或缺失的 npm 包依赖,可以协助发现现存代码可能存在的幽灵依赖,类似的还有:npm-check 等。
5. 依赖冲突
依赖冲突通常发生在两个或多个包依赖不同版本的同一库时。设想这样一个场景:包 app 依赖了 lib-a、lib-b,而 lib-a、lib-b 又依赖了 lib-d,此时这几个实体之间之间形成了一种菱形依赖关系:
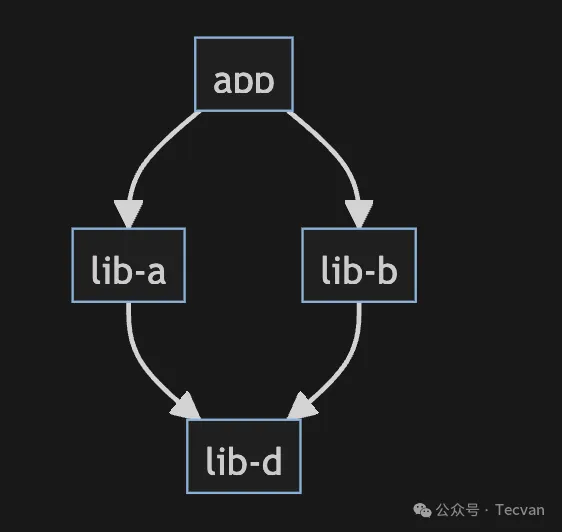
图解:菱形依赖
ok,菱形依赖本身是一种非常常见且合理的依赖结构,这不是问题,真正的问题出现在若此时 lib-a/lib-b 所依赖的 lib-d 版本不一致时,就会产生依赖冲突现象:
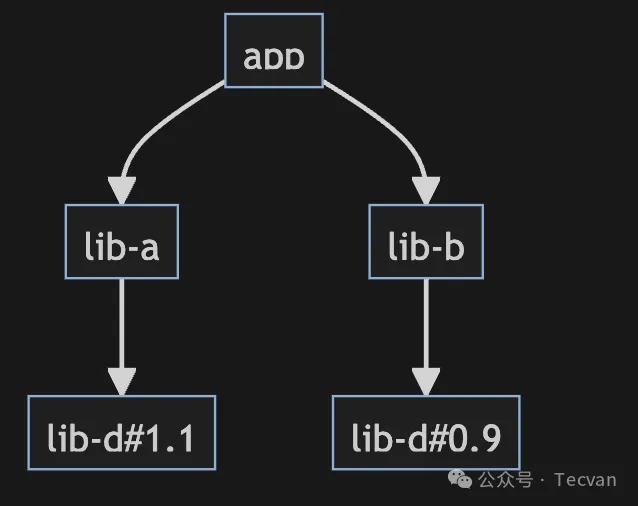
图解:依赖冲突
而这轻则导致 lib-d 被重复安装;严重时可能导致如构建失败、应用运行错误(例如 bundle 中同时存在两个 react 实例)等问题。其次,更大的隐患在于,依赖冲突会使得依赖网络的复杂度进一步提升恶化,降低项目的可维护性和扩展性,长期难以维护。
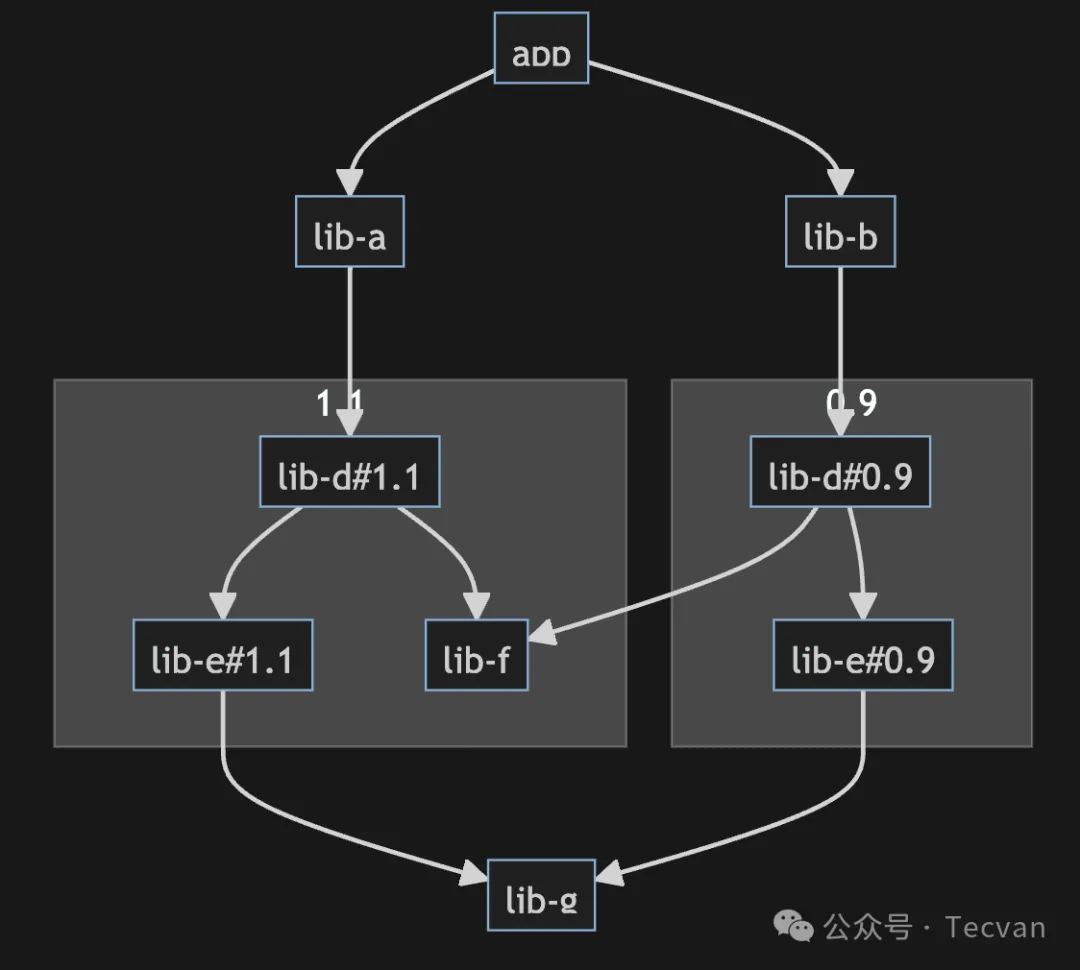
图解:进一步劣化的结构
比较难受的是,依赖冲突问题多数时候出现在次级依赖中,我们通常无法细粒度地管控好这些底层依赖,悲观地说,我们还无法从根本上解决这些问题,只能采取一些手段尽可能缓解:
- 打包构建时,可以借助 webpack alias 之类的手段,强制指定版本包位置。
- 可以借助 package.json 的 resolution 字段强制绑定版本号。
- 必要时,借助 patch-package 或 pnpm patch 对依赖包做微调。
6. 循环依赖
循环依赖是指两个或多个 Package 之间相互依赖,形成链式闭环的情况。这种循环结构可能很明显也可能很隐蔽,但总之在依赖链条上形成了一个环状的结构关系。
循环依赖的问题在于,它会使得依赖关系变得非常复杂 —— 从有向无环到更复杂的有向有环图,这会增加依赖网络解析成本,包管理器通常需要为此编写复杂的循环依赖安装算法;也会增加“开发者”的理解成本 —— 而这必然也会进一步降低项目的可维护性。
其次,循环依赖的更新逻辑也会变得特别啰嗦,假设存在 A=>B=>C=>A 这样的循环依赖链条,那么 B 的更新可能会导致 C/A 需要同步更新,整体结构的稳定性变得非常脆弱。
7. 依赖更新链路长
设想一个场景,存在依赖链条:A => B => C => D,若底层 D 包发布了一个新版本(比如修复了一个重要的安全问题),那么有时候可能需要链条上的 B 与 C 包都随之更新版本之后,A 才能得到相应更新。关键问题在于,中间节点越多,完成更新所需要的时间往往越长,如果中间某些节点的更新活跃度并不高的时候,延迟问题必然会更严重,这些风险点最终都会嫁接到顶层 A 包身上。
当然,当下的开源依赖包也并没有如上述设想的那般脆弱,质量“良好”的开源 Package 往往有较强的容错性,对底层的依赖往往也会优先遵循 semver 的范围版本规则。但“闭源”软件包通常就没这么高的质量要求了,可能会设置一些拙劣的兼容策略,甚至为了避免向前向后兼容的麻烦,直接“锁死”核心依赖版本,导致底层包出现问题时,顶层依赖可能难以得到更新。
8. 大型应用中的依赖更新
设想我们正在维护代码总量超过 10w 行且持续迭代的一个大型应用,若此时需要对某些基础依赖做比较大的版本升级,那么你所面临工作量与复杂度都会非常高。
首先,你需要细致地梳理出新旧版本之间的接口、行为差异,这一步需要做许多调研工作,甚至可能需要仔细比对两个版本源码之间的区别;其次,按照这些差异点对 10w 行代码都做一次更新适配,以使得代码在新版本中能够正常运行,某些命中 Breaking change 的地方可能还需要重新设计实现方案。
这个过程隐含着非常大的开发与测试的工作量,通常需要持续投入一段时间做开发,但问题是业务本身还在持续迭代,不可能把所有事情停下来等着你慢慢把版本升上去;也通常,这件事情很难仅仅通过“增加人力”就能提高执行效率,因为改造过程随时可能出现一些始料未及的新问题,需要有足够技术功力的人才能高效做出新的判断与决策。
应对这些问题,一个 「理所当然」 的解决方案是 Case by case 地设计一些技术方案来实现渐进式代码升级,例如在微前端场景中可以通过子应用方式,将页面与模块逐个迁移到新的依赖版本,直至整体升级完毕;此外,也可以适当设计一些接口适配器,尽可能减少直接改动顶层代码。
其次,对于一些工程能力比较强的团队,推荐引入一些 E2E 技术(彩蛋:为什么这里不是 UT?)并持续维护一套至少覆盖核心链路的测试用例,发生变更时由自动化测试技术确保应用状态符合功能预期。这是一种一本万利的技术投入,同样适用于验证日常业务迭代中的代码变动。
一些最佳实践
综上,依赖管理是一个复杂问题,天然存在着许多复杂性与不可控因素,并且当下并没有任何解决方案能普适地解决所有问题。不过,也有一些值得在日常工作中遵循的最佳实践,能够一定程度上缓解各种问题的影响面。
1. 严格审查
在引入新的三方依赖时,不要轻易做决定!虽然 NPM 已经注册了数不胜数的各种类型的依赖,足以覆盖我们日常遇到的多数开发场景,并且使用成本都非常低,但这并不意味着我们可以未经思考通通采用!请记住,在软件工程中,治理问题的成本与复杂度多数时候比开发一个新功能特性要高出许多,一个错误的决策在未来可能需要花十倍力气解决问题(总是要还的)。
因此,在使用某个 Package 之前,我们至少应该对它做一些基础的调研,虽然很难完全准确评估一个 Package 的好坏,但某些关键特性还是有助于侧面了解它的质量,例如:
- 是否有完备详尽的 Readme:这体现了作者的用心程度与专业度,也同时决定了我们使用这个包的成本。理想的 Readme 应该至少包含这个包的使用方法与基本原理,内容越详细越好;
- 更新频率:更新频率越高通常证明作者或者社区的活跃度越高,也通常意味着出现 Issue 时解决速度越快,你也不想在遇到问题时没有被及时解决吧?
- 单测:作为开源框架,稳定性是一个非常重要的指标,而单测又是一种能够确保稳定性的重要工具,因此可以在做决策时建议看看框架源码本身的单测覆盖率,以及单测断言的使用情况;反之,如果连单测都没做好,建议慎重!
- Benchmark:与单测类似,若源码中包含一定比例的 Benchmark,则意味着作者对作品的性能有一定要求,那么自然地质量相对更值得信任一些;
- 下载或 Star 量:这两个指标通常意味着这个开源作品被使用的频率,频率越高通常意味着被越多人消费、验证过,也就越能证明这个框架不会存在一些基本的质量问题 —— 至少能跑的通嘛;不过请注意,不要迷信这两个指标,有许多场外因素(例如发布时间、作者影响力等)都会影响这些数量的变化,数量大不足以证明质量高;
- 代码结构:如果时间允许,非常建议审查开源框架的代码结构,如果发现明显的 Bad Smell,例如圈复杂度明显很高,或者有许多重复代码,则建议慎重采用;
2. 定期清理无用依赖
随项目迭代,依赖列表通常会逐渐增加,但很少被及时清理,导致无用依赖逐渐增多,甚至可能引发上述诸多依赖问题,因此建议有一套机制,定期扫描 & 删除项目中的无用依赖。社区已经提供了不少依赖扫描工具,例如 depcheck,借助这些工具我们能快速找出无用依赖。
3. 定期 review 依赖结构图
同样,随项目迭代,依赖结构图持续发生变化,且通常会越来越复杂,可能多数开发者体感上觉得依赖安装的时间越来越长,但没有深究或观察过依赖结构正在出现一些不合理的劣化,可能那天想起来要优化的时候,问题已经变得非常复杂,难以纠偏。
因此,建议在日常工作中关注依赖结构的变化情况,是否出现上述异常,例如:重复依赖、依赖冲突等。一个比较简单的方式,是观察 pnpm-lock.yaml、yarn.lock 等文件的内容,可以考虑借助 CI,写脚本,在合码之前对比 Merge Request 前后的结构图,检查是否出现一些 bad case。
4. 使用 Pnpm
在 JS 社区,目前比较主流的包管理器有:NPM、Yarn、Pnpm 三种,从底层实现逻辑来说,更推荐使用 Pnpm (Performance NPM),它安装下来的依赖结构更合理,能避开大多数幽灵依赖问题,更重要的,它的缓存结构更合理,也因此有更好的安装、更新性能。
结语
综上,社区开源能切实提升整个软件工业的发展速度,极大降低开发成本,但不可忽视的也带来了一些新的复杂性 —— 依赖管理,这其中隐含着许多很少被关注的隐患,多数时候这并不会直接造成问题,但叠加时间与规模两个因素后,通常会慢慢会演变的越来越复杂,积重难返!所以,一方面日常需要警惕依赖结构的劣化,一方面真遇到问题时,可以参照上面梳理的各种 case,分析具体问题,予以解决。




















