一、Two-Stage Constrained Actor-Critic for Short Video Recommendation
第一篇工作是快手自研的,主要针对的是带约束的多任务场景。
1. 短视频多任务推荐场景

这篇工作主要针对的是短视频的一个比较专业化的场景,多任务的用户反馈分为观看时长和互动,比较常见的互动包括点赞、收藏、关注还有评论,这些反馈各有特点。我们通过线上系统观察发现,时长信号实际上非常稠密,而且因为它是连续值,能够非常准确地反映用户对该视频的喜好程度,所以我们在优化过程中,把这个信号作为主要优化目标。相比之下互动信号更加稀疏,而且一般都是离散值,随机性也更高,准确度不足,但是又需要进行一定优化,所以在我们的系统中将它作为辅助目标进行优化。在整个系统的目标设定上,基于之前的观察,将时长作为主要目标,互动作为辅助优化,尽量保证互动的信号不损失,作为优化的整体目标。

这样就可以非常直观地将问题描述成一个带约束的优化问题,有一个主目标 utility 的优化,辅助目标是满足一个下界即可。有别于常见的 Pareto 优化问题,这里是需要分主次的。

解决这个问题的一个常用手段,就是把它转化成拉格朗日对偶问题,这样就可以直接合到一个优化的目标函数里面,无论是整体优化还是交替优化,可以合成一个整体目标进行优化。当然,需要去控制不同目标的相关性以及影响因子。

这种直观的 formulation 仍存在一些问题,因为用户状态动态变化,尤其是在短视频场景下,变化速度非常快。另外因为信号不统一,尤其是主要目标优化和稀疏的辅助目标优化存在非常不一致的分布问题,现有的解决方案很难处理。如果把它统一到一个目标 function,其中一个信号就可能 dominate 另外一个信号。
2. Multi-task Reinforcement Learning

基于第一点,考虑到用户的动态变化问题经常被描述成 MDP,也就是用户与系统的交替互动的 sequence,而这个 sequence 描述成 Markov Decision Process 之后就可以使用强化学习的手段求解。具体地,在描述成 Markov Decision Process 之后,因为同时还需要区分主要目标和辅助目标,所以需要额外声明一下,在用户反馈时,要区分两种不同目标,此外辅助目标也可能有多个。强化学习在定义长期优化目标时,会将要优化的主目标定义成一个长期价值函数,叫做 value function。同样对于辅助目标,也会有对应的 value function。相当于每一个用户的反馈,都会有一个长期价值评估,相比于之前做 utility function,现在变成了一个长期价值的 value function。

同样地,结合强化学习时会产生一些新的问题,比如强化学习如何区分不同的折扣系数。另外,因为引入了更多的 constraints,参数的搜索空间也变得更大,强化学习将变得更困难。
3. Solution: Two-Stage Multi-Critic Optimization

这篇工作的解决方案是把整个优化分成两个阶段,第一个阶段优化辅助目标,第二个阶段优化主要目标。
在第一个阶段辅助目标优化时,采取了典型的 actor critic 优化方式,针对例如点赞和关注等辅助目标的优化,分别优化一个 critic,用来预估当前 state 的优劣。长期价值预估准确之后,再去优化 actor 时就可以使用 value function 来引导它的学习。公式(2)是 critic 的优化,公式(3)是 actor 的优化,针对 critic 的优化,在训练时会用到当前的 state 和下一步的 state 以及当前 action 的采样。根据 Bellman equation 可以得到 action,再加上未来的 state 的 value 预估,应该趋近于当前 state 的预估,这样去优化就可以逐渐逼近准确的长期价值预估。在引导 actor 学习,也就是推荐策略学习时,会采用一个 advantage function。Advantage function 就是当采用某个 action 之后,其效果是否比平均预估更强,这个平均预估叫做 baseline。Advantage 越大,说明 action 越好,采用这个推荐策略的概率就会越大。这是第一阶段,辅助目标的优化。

第二阶段是优化主要目标,我们采用的是时长。辅助目标在约束主要目标时,采用了近似的策略,我们希望主要目标输出的 action 分布尽可能接近不同的辅助目标,只要不断接近辅助目标,辅助目标的结果应该就不会太差。在得到近似的 formulation 之后,通过 completion of square 就可以得到一个闭式解,即加权的方式。整个主要目标的 actor critic 的优化方式,在 critic 层面和 value function 估计层面上,其实没有太大区别。但在 actor 时,我们引入了通过闭式解得到的权重。该权重的含义是,某个辅助策略 I 对应的影响因子越大,它对整体权重的影响也越大。我们希望策略输出的分布尽可能接近所有辅助目标策略的平均值,得出来的闭式解的 behavior 时有这样的现象。
4. Experiments

我们在 offline 的数据集上测试了多目标优化的效果,这里的主要目标是 watch time 即观看时长,辅助目标是 click、like、comment 和 hate 等互动指标。可以看到我们提出的 two-stage 的 actor-critic 能够拿到最优效果。

同样我们也在线上系统做了相应的对比实验,线上系统的设定采用了 actor 加 ranking 的推荐模式,这里的 action 是权重,最终的 ranking 是由每一个 item 和权重做内积得出来的结果。线上实验也可以看到,watch time 能够在提升的同时对其它互动有约束效果,相比于之前的优化策略,它能够更好地约束互动指标。
以上就是对第一篇工作的介绍。
二、Multi-Task Recommendations with Reinforcement Learning
第二个工作同样也是强化学习在多任务优化的应用,只不过这是比较传统的优化。这篇工作是快手和港城大的合作项目,一作是 Liu Ziru。
1. Background and Motivation

这篇工作主要讨论的问题是典型的多任务联合训练,其挑战是需要平衡不同任务之间的系数,传统的 MTL 的解决方案一般会考虑线性组合方式,且会忽略 session 维度,即长期的动态变化。这篇工作提出的 RMTL 通过长期的预估来改变加权方式。
2. Problem Formulation

问题设定是定义 CTR 和 CVR 的预估的联合优化。同样我们也有一个 MDP(Markov Decision Process)的定义,但这里 action 不再是推荐列表,而是对应的 CTR 和 CVR 预估。如果要预估准确,reward 就应该定义为 BCE 或者对应的任何一个合理的 loss。在整体的目标定义上,一般情况下会定义成不同的任务加权之后再对整个 session 以及所有的 data sample 进行求和。

可以看到,它的权重系数除了 Gamma 的 discount 之外,还会受到一个需要调整的系数的影响。
3. Solution Framework

我们的解决方案是让这个系数的调整和 session 维度的预估相关。这里给出了一个 ESMM 的 backbone,当然其它 baseline 的使用也是通用的,都可以用我们的方法进行改进。
下面详细介绍一下 ESMM,首先有一个 task specific 的 actor,对每一个任务都会有一个 target 和 current actor 的优化,优化时用到了类似之前提到的 actor critic 的 framework。优化过程中,BCE loss 在引导 actor 学习时,需要对 task specific 的权重进行调整。在我们的解决方案里,这个权重需要根据未来的价值评估进行相应的更改。该设定的意思是,如果未来的评估价值较高,说明当前 state 和当前 action 是比较准确的,对它的学习就可以放慢。相反,如果对未来的预估较差,说明该模型对 state 和 action 的未来并不看好,就应该增加它的学习,weight 采用这种方式进行了调整。这里的未来评估同样采用前文提到的 critic network 进行学习。

critic 的学习也同样采用未来 state 和当前 state 的差值,但区别于 value function,这里差值的学习采用的是 Q function,需要用到 state 和 action 的联合评估。在做 actor 更新时,还要同时使用不同 task 对应的 actor 的学习。这里 soft update 是一个通用的 trick,在增加 RL 学习稳定性的时候比较有用,一般会同时优化 target 和当前的 critic。
4. Experiment

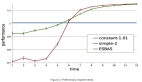
通过对两个公开数据集的对比实验,可以看出,我们的方法可以结合现有的优化方式包括 ESMM、MMoE 以及 PLE,得到的效果都能够对之前的 baseline 有所提升。

PLE 在我们的观测中是最好的 baseline,我们根据观测现象的归因是在学习不同 task 时,PLE 能够更好地学习到 shared embedding。

相比之下,ESMM 在 Kuairand task 上面可以达到更好的 CVR 的评估。我们推测这与 click 和 conversion 在这个 dataset 里更强的相关性有关。
5. Transferability Study

除此之外我们也做了 transferability 的 test,因为我们的 critic 是可以直接嫁接到其他模型上的。比如可以通过最基础的 RMTL 学习出 actor critic,然后用 critic 直接去提升其他模型的效果。我们发现,在嫁接时都能够稳定提升效果。
6. Ablation Study

最后我们做了 ablation study,对不同的加权方式进行了对比,目前最好的效果都是由我们的 RMTL 得出来的。
三、Conclusion
最后总结一下 RL 和 MTL 的一些经验。

我们发现推荐系统在长期优化时,尤其是在长期优化复杂指标时,是非常典型的强化学习和多任务优化的场景。如果是主副目标联合优化,可以通过 soft regularization 去约束主要目标学习。多目标联合优化时,如果考虑到不同目标的动态变化,也能够提升其优化效果。
除此之外也存在一些挑战,比如在强化学习不同模块结合时,会对系统的稳定性带来很多挑战。我们的经验是,对数据质量的把控、label 的准确性的把控和模型预估准确率的监督是非常重要的途径。除此之外,由于推荐系统和用户是直接交互的,不同目标仅能片面反映用户体验,所以得到的推荐策略也会非常不同。如何在不断变化的用户状态下,联合优化全面提升用户体验,在未来将是一个非常重要的课题。
四、Q&A
Q1:快手的时长信号和互动信号一般用的是什么 loss,是分类还是回归,互动目标和观看目标离线评估一般看哪些指标?
A1:时长指标是一个典型的回归任务。但是我们同样也注意到,时长预估是和视频本身的长度强相关的,比如短视频和长视频的分布会非常不一样,所以在预估时会先对它做分类处理,然后再做 regression。最近我们在 KDD 也有一篇工作,讲用树方法拆分时长信号预估的方法,如果大家感兴趣可以关注。大概意思是,比如把时长分成长视频和短视频,长视频预估会有一个预估的范围,短视频会有一个短视频的预估范围。也可以用树方法进行更细致的下分,长视频可以分成中视频和长视频,短视频也可以分成超短视频和短视频。当然也有纯用分类方法解决时长预估的,我们也有做测试。整体效果上来看,目前还是在分类的框架下,再做 regression,效果会稍微好一点。其他的互动的指标预估,一般和现有的预估方法差不多。离线评估时,一般 AUC 和 GAUC 是比较强的信号,目前看这两个信号还是比较准确的。
Q2:回归类的比如时长指标离线看什么指标?
A2:我们的系统主要看的是 online 的指标,离线一般是用 MAE 和 RMSE。但我们同样看到离线和线上的评估也存在差异,如果离线评估没有比较明显的提升,那线上也不一定能看到对应的提升效果,它的实际对应关系在没有达到一定显著性的时候,区别不会太大。
Q3:类似转发等比较稀疏的目标,建模上有没有方法可以使其估得更准?
A3:对用户转发的理由分析,做一些观测等可能会有比较好的收效。目前我们在做转发预估的时候,在我们的链路下做和其他的互动目标的预估方式差距不太大。有个比较通用的思路,就是 label 的定义尤其是负反馈信号的定义,会非常大程度上影响模型训练准确率。除此之外就是数据来源的优化,数据和线上的分布是否有偏,也会影响到预估准确率,所以我们很多工作也在做消偏。因为在推荐场景下,很多预估的指标实际上是间接的信号,它在下一步才会影响到推荐效果。所以以推荐效果为主导去优化指标,是我们这边的应用场景。
Q4:快手这边这个多目标融合是怎么做的?是强化学习调参吗?
A4:在多目标融合时,一开始有一些 heuristic 的方法,一些手调的参数平衡的方法。后面逐渐开始使用调参方式,强化学习调参也尝试过。目前的经验是自动化调参比手调好一些,它的上限稍微高一些。
Q5:假如线上数据或者要调的某个目标本身特别稀疏,如果基于线上数据调参,反馈周期或者观察置信需要比较久,这样调参效率会不会比较低,这种情况下有什么解决办法?
A5:我们最近也有一些工作讨论极其稀疏、甚至几天才有反馈的这种信号。其中最典型的一个信号就是用户的留存,因为用户可能离开之后过几天才会回来,这样我们拿到信号时,模型已经更新好几天了。解决这些问题有一些折中方案,一个解决方案是可以去分析实时的反馈信号有哪些和这种极其稀疏的信号有一定的相关性。通过优化这些实时的信号采用组合方式去间接优化长期信号。以刚才的留存作为例子,在我们的系统中,我们发现用户的留存和用户实时的观看时长存在非常强的正相关,用户观看时长就代表用户对系统的粘度,这样基本能够保证用户留存的下界。我们优化留存时,一般会使用优化时长组合一些其他相关指标去优化留存。只要是我们分析发现和留存有一定相关性的,都可以引入进来。
Q6:有没有试过其他的强化学习方法,actor critic 有什么优势,为什么使用这种方式?
A6:Actor critic 是我们迭代了几次之后的结果,之前也试过 DQN 和Reinforce 等稍微直观的方法,有的在一些场景下确实会有效果,但目前 actor critic 是一个相对稳定且好调试的方法。举个例子,比如用 Reinforce 需要用到长期信号,而长期的 trajectory 信号波动性比较大,想提升它的稳定性会是比较困难的问题。但 actor critic 的一个优点是可以根据单步信号进行优化,这是非常符合推荐系统的一个特点。我们希望每一个用户的反馈都能作为一个 training sample 去学习,对应的 actor critic 和 DDPG 方法会非常符合我们系统的设定。
Q7:快手多目标融合用强化学习方法时,一般会使用哪些 user 特征,是否存在一些很精细的特征例如 user id 导致模型收敛困难,怎么解决这个问题?
A7:user id 其实还好,因为我们 user 侧的特征还是会用到各种各样的特征的。user 除了有 id 特征以外,还会有一些统计特征。除此之外在推荐链路上,因为 RL 在我们应用的模块处于比较靠后的阶段,比如精排和重排,在前面的一些阶段也会给出预估还有模型的排序信号,这些实际上都有用户的信号在里面。所以强化学习在推荐的场景下拿到的 user 侧的信号还是很多的,基本上不会出现只用一个 user id 的情况。
Q8:所以也用了 user id,不过暂时还没有出现收敛困难的问题,对吧?
A8:对的,而且我们发现如果不用 user id,对个性化影响还是挺大的。如果只用一些用户的统计特征,有的时候不如一个 user id 的提升效果大。确实 user id 的影响比较大,但是如果让它的影响占比太大,会有波动性的问题。
Q9:有些公司的一些业务中,用户的行为数据可能比较少,是不是也会遇到如果用 user id 就不好收敛这个问题,如果遇到类似问题,有什么解决方案?
A9:这个问题偏向于 user cold start,偏 cold start 场景下在推荐链路一般会用补全或自动化 feature 填充,先把它假设成一个默认 user,可能会在一定程度上解决这个问题。后面随着 user 和系统不断交互、session 不断充实,实际上可以拿到一定的用户反馈,会逐渐训的越来越准。保证稳定性方面,基本上只要控制好不让一个 user id 去 dominate 训练,还是能够很好地提升系统效果的。
Q10:前面提到的对时长目标建模先做分类再做回归,具体是时长先做分桶,分完桶再回归吗?这种方式还是不是无偏估计?
A10:那篇工作是直接去做分桶,然后用每一个分桶到达的概率去联合评估时长,不是分桶之后再做 regression。它仅用分桶的概率,再加上分桶的值去做整体的带概率的评估。分桶之后再 regression 应该确实不再是无偏的,毕竟每一个分桶还是有它自己的分布规律的。
Q11:刚才老师提到一个问题,对于两个目标 a 和 b,我们的主目标是 a,对 b 的要求就是不降就行。我们实际场景中可能还存在 a 是主目标,对 b 没任何约束的场景。例如,把 CTR 目标跟 CVR 目标一起优化,但模型本身是一个 CVR 模型,我们只关注 CVR 的效果,不关心 CTR 效果会不会变差,我们只是希望 CTR 尽可能地帮助到 CVR。类似这种场景,如果想把它们放在一起联合训练,是否有什么解决办法?
A11:这实际上已经不再是多目标优化了,CTR 的指标甚至都可以直接作为一个输入去优化 CPR,因为 CTR 不再是优化目标了。但这样可能对用户不太好,因为用户的 CTR 更大程度上代表了对系统的喜好程度和粘性。不过不同系统可能也有所差别,这取决于推荐系统是以卖商品还是以流量为主。由于快手短视频这种是以流量为主的,所以说用户 CTR 是一个更直观、更主要的指标,CVR 只是流量引流之后的一个效果。