













多模态文档理解能力新SOTA!
阿里mPLUG团队发布最新开源工作mPLUG-DocOwl 1.5,针对高分辨率图片文字识别、通用文档结构理解、指令遵循、外部知识引入四大挑战,提出了一系列解决方案。
话不多说,先来看效果。
复杂结构的图表一键识别转换为Markdown格式:
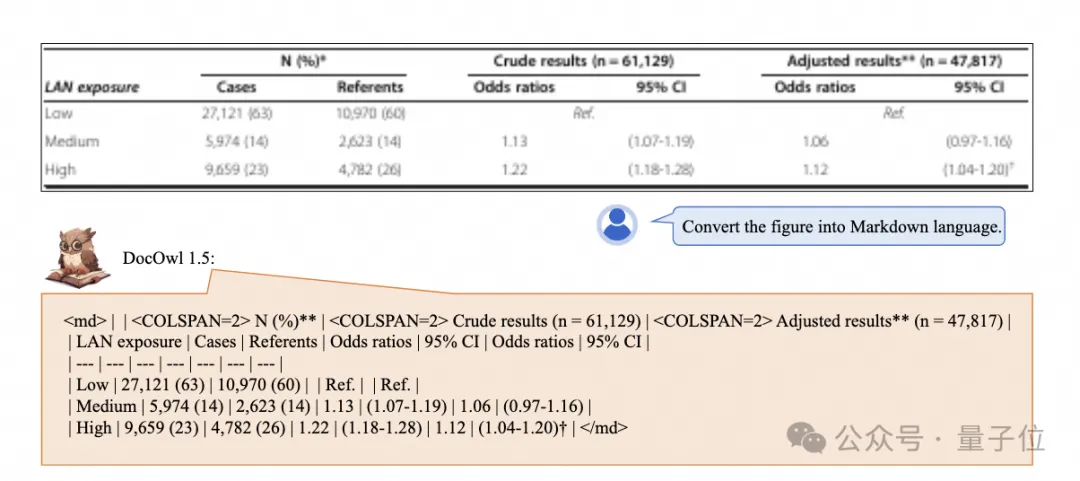
不同样式的图表都可以:

更细节的文字识别和定位也能轻松搞定:

还能对文档理解给出详细解释:

要知道,“文档理解”目前是大语言模型实现落地的一个重要场景,市面上有很多辅助文档阅读的产品,有的主要通过OCR系统进行文字识别,配合LLM进行文字理解可以达到不错的文档理解能力。
不过,由于文档图片类别多样、文字丰富且排版复杂,难以实现图表、信息图、网页等结构复杂图片的通用理解。
当前爆火的多模态大模型QwenVL-Max、Gemini, Claude3、GPT4V都具备很强的文档图片理解能力,然而开源模型在这个方向上的进展缓慢。
而阿里新研究mPLUG-DocOwl 1.5在10个文档理解基准上拿下SOTA,5个数据集上提升超过10个点,部分数据集上超过智谱17.3B的CogAgent,在DocVQA上达到82.2的效果。
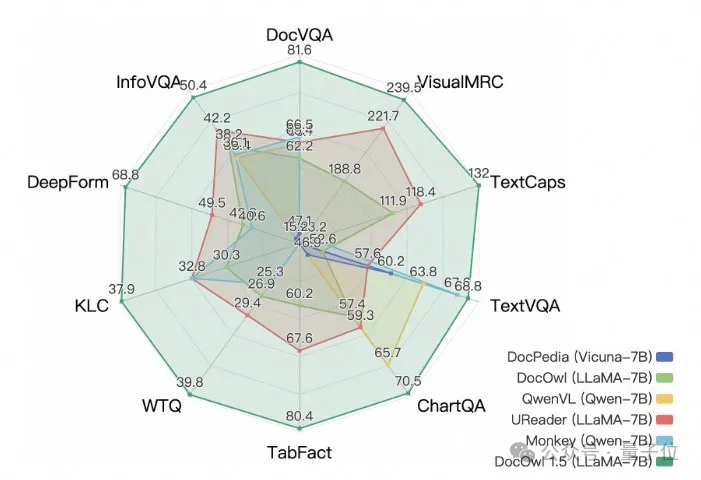
除了具备基准上简单回答的能力,通过少量“详细解释”(reasoning)数据的微调,DocOwl 1.5-Chat也能具备多模态文档领域详细解释的能力,具有很大的应用潜力。
阿里mPLUG团队从2023年7月份开始投入多模态文档理解的研究,陆续发布了mPLUG-DocOwl、 UReader、mPLUG-PaperOwl、mPLUG-DocOwl 1.5,开源了一系列文档理解大模型和训练数据。
本文从最新工作mPLUG-DocOwl 1.5出发,剖析“多模态文档理解”领域的关键挑战和有效解决方案。
挑战一:高分辨率图片文字识别
区分于一般图片,文档图片的特点在于形状大小多样化,其可以包括A4大小的文档图、短而宽的表格图、长而窄的手机网页截图以及随手拍摄的场景图等等,分辨率的分布十分广泛。
主流的多模态大模型编码图片时,往往直接缩放图片的大小,例如mPLUG-Owl2和QwenVL缩放到448x448,LLaVA 1.5缩放到336x336。
简单的缩放文档图片会导致图片中的文字模糊形变从而不可辨认。
为了处理文档图片,mPLUG-DocOwl 1.5延续了其前序工作UReader的切图做法,模型结构如图1所示:
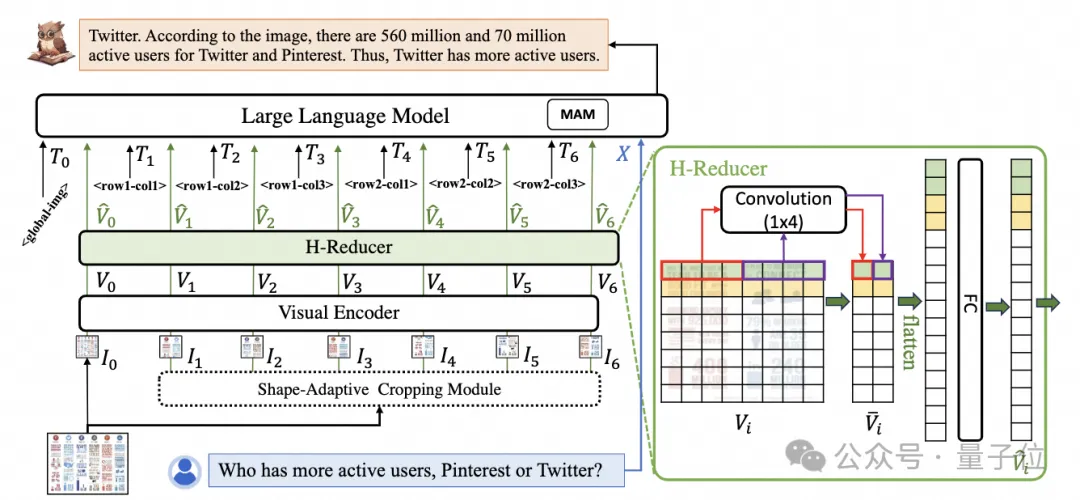
△图1:DocOwl 1.5模型结构图
UReader最早提出在已有多模态大模型的基础上,通过无参数的形状适应切图模块(Shape-adaptive Cropping Module)得到一系列子图,每张子图通过低分辨率编码器进行编码,最后通过语言模型关联子图直接的语义。
该切图策略可以最大程度利用已有通用视觉编码器(例如CLIP ViT-14/L)的能力进行文档理解,大大减少重新训练高分辨率视觉编码器的代价。形状适应的切图模块如图2所示:

△图2:形状适应的切图模块。
挑战二:通用文档结构理解
对于不依赖OCR系统的文档理解来说,识别文字是基本能力,要实现文档内容的语义理解、结构理解十分重要,例如理解表格内容需要理解表头和行列的对应关系,理解图表需要理解线图、柱状图、饼图等多样化结构,理解合同需要理解日期署名等多样化的键值对。
mPLUG-DocOwl 1.5着力于解决通用文档等结构理解能力,通过模型结构的优化和训练任务的增强实现了显著更强的通用文档理解能力。
结构方面,如图1所示,mPLUG-DocOwl 1.5放弃了mPLUG-Owl/mPLUG-Owl2中Abstractor的视觉语言连接模块,采用基于“卷积+全连接层”的H-Reducer进行特征聚合以及特征对齐。
相比于基于learnable queries的Abstractor,H-Reducer保留了视觉特征之间的相对位置关系,更好的将文档结构信息传递给语言模型。
相比于保留视觉序列长度的MLP,H-Reducer通过卷积大幅缩减了视觉特征数量,使得LLM可以更高效地理解高分辨率文档图片。
考虑到大部分文档图片中文字优先水平排布,水平方向的文字语义具有连贯性,H-Reducer中采用1x4的卷积形状和步长。论文中,作者通过充分的对比实验证明了H-Reducer在结构理解方面的优越性以及1x4是更通用的聚合形状。
训练任务方面,mPLUG-DocOwl 1.5为所有类型的图片设计了统一结构学习(Unified Structure Learning)任务,如图3所示。
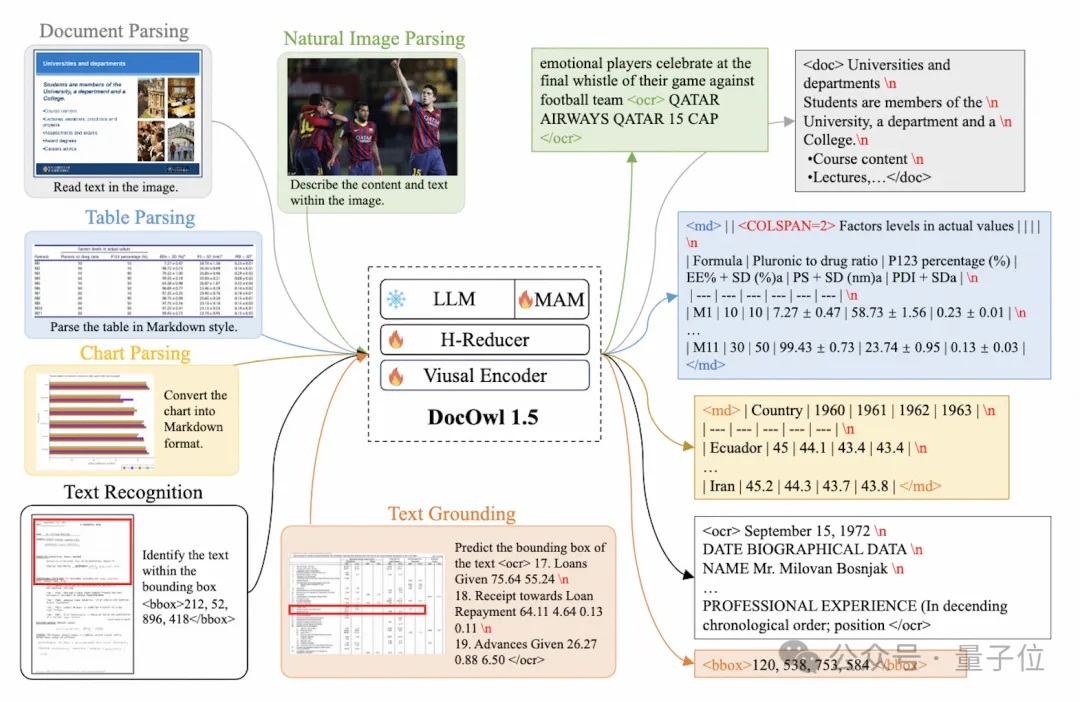
△图3:统一结构学习
Unified Structure Learning既包括了全局的图片文字解析,又包含了多粒度的文字识别和定位。
在全局图片文字解析任务中,对于文档图片和网页图片,采用空格和换行的形式可以最通用地表示文字的结构;对于表格,作者在Markdown语法的基础上引入表示多行多列的特殊字符,兼顾了表格表示的简洁性和通用性;对于图表,考虑到图表是表格数据的可视化呈现,作者同样采用Markdown形式的表格作为图表的解析目标;对于自然图,语义描述和场景文字同等重要,因此采用图片描述拼接场景文字的形式作为解析目标。
在“文字识别和定位”任务中,为了更贴合文档图片理解,作者设计了单词、词组、行、块四种粒度的文字识别和定位,bounding box采用离散化的整数数字表示,范围0-999。
为了支持统一的结构学习,作者构建了一个全面的训练集DocStruct4M,涵盖了文档/网页、表格、图表、自然图等不同类型的图片。
经过统一结构学习,DocOwl 1.5具备多领域文档图片的结构化解析和文字定位能力。


△图4: 结构化文字解析
如图4和图5所示:

△图5: 多粒度文字识别和定位
挑战三:指令遵循
“指令遵循”(Instruction Following)要求模型基于基础的文档理解能力,根据用户的指令执行不同的任务,例如信息抽取、问答、图片描述等。
延续mPLUG-DocOwl的做法,DocOwl 1.5将多个下游任务统一为指令问答的形式,在统一的结构学习之后,通过多任务联合训练的形式得到一个文档领域的通用模型(generalist)。
此外,为了使得模型具备详细解释的能力,mPLUG-DocOwl曾尝试引入纯文本指令微调数据进行联合训练,有一定效果但并不理想。
在DocOwl 1.5中,作者基于下游任务的问题,通过GPT3.5以及GPT4V构建了少量的详细解释数据(DocReason25K)。
通过联合文档下游任务和DocReason25K进行训练,DocOwl 1.5-Chat既可以在基准上实现更优的效果:

△图6:文档理解Benchmark评测
又能给出详细的解释:

△图7:文档理解详细解释
挑战四:外部知识引入
文档图片由于信息的丰富性,进行理解的时候往往需要额外的知识引入,例如特殊领域的专业名词及其含义等等。
为了研究如何引入外部知识进行更好的文档理解,mPLUG团队着手于论文领域提出了mPLUG-PaperOwl,构建了一个高质量论文图表分析数据集M-Paper,涉及447k的高清论文图表。
该数据中为论文中的图表提供了上下文作为外部知识来源,并且设计了“要点”(outline)作为图表分析的控制信号,帮助模型更好地把握用户的意图。
基于UReader,作者在M-Paper上微调得到mPLUG-PaperOwl,展现了初步的论文图表分析能力,如图8所示。

△图8:论文图表分析
mPLUG-PaperOwl目前只是引入外部知识进文档理解的初步尝试,仍然面临着领域局限性、知识来源单一等问题需要进一步解决。
总的来说,本文从最近发布的7B最强多模态文档理解大模型mPLUG-DocOwl 1.5出发,总结了不依赖OCR的情况下,进行多模态文档理解的关键四个关键挑战(“高分辨率图片文字识别”,“通用文档结构理解”,“指令遵循”, “外部知识引入” )和阿里巴巴mPLUG团队给出的解决方案。
尽管mPLUG-DocOwl 1.5大幅提升了开源模型的文档理解表现,其距离闭源大模型以及现实需求仍然有较大差距,在自然场景中文字识别、数学计算、通用型等方面仍然有进步空间。
mPLUG团队会进一步优化DocOwl的性能并进行开源,欢迎大家持续关注和友好讨论!
GitHub链接:https://github.com/X-PLUG/mPLUG-DocOwl
论文链接:https://arxiv.org/abs/2403.12895






























